1. 主机概述
| 主机名 | 主机IP | 备注 |
|---|---|---|
| node1 | 192.168.1.101 | 模拟fence设备 |
| node2 | 192.168.1.102 | rhcs双机节点 |
| node3 | 192.168.1.103 | rhcs双机节点 |
修改三台主机的hosts文件,内容如下
[root@node1 ~]# vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6
192.168.1.101 node1
192.168.1.102 node2
192.168.1.103 node3
2. 配置ntp
(1) 修改ntp.conf文件vim /etc/ntp.conf
增加如下配置
#Hosts on local network are less restricted.
restrict 192.168.1.0 mask 255.255.255.0 nomodify notrap
#Use public servers from the pool.ntp.org project.
#Please consider joining the pool (http://www.pool.ntp.org/join.html).(ntp服务器可自行选择合适的,这里我用的是1.cn.pool.ntp.org)
server 1.cn.pool.ntp.org prefer
(2)启动ntpd服务
service ntpd start
3. 安装luci
(1) 登陆node1服务器,配置yum源,安装luci服务yum install luci
(2) 启动luci服务service luci start
(3) 浏览器访问https://192.168.1.101:8084/
(4) 输入用户和密码(用户名root,密码是root的口令),登陆到主页

4. 配置RHCS
4.1 在node2和node3主机上,安装ricci、cman和rgmanager
yum install ricci cman rgmanager -y
4.2 修改ricci用户密码,否则创建集群时会出现节点认证失败的错误
passwd ricci
启动ricci服务service ricci start
4.3 创建集群
点击Create

配置集群参数
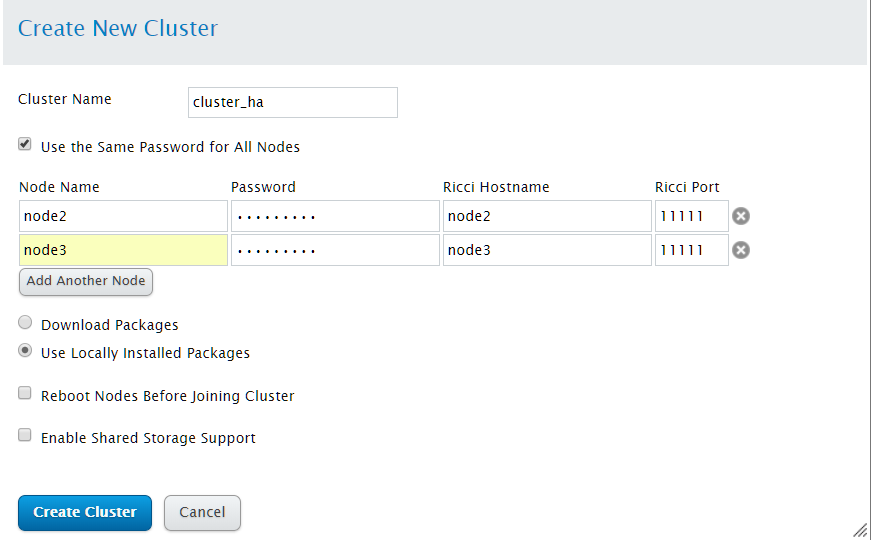
1). 在Cluster Name 文本框中输入集群名称,不能超过15个字符
2). 如果集群中每个节点都有相同的ricci密码,则选择"Use the same password for all nodes",以便在添加节点中自动填写ricci用户口令
3). 在Node Name栏中输入集群中各节点的主机名,并填入ricci用户口令
4). 点击Add Another Node添加集群节点
5). 如果不想在创建集群的时候升级已经在节点中安装的集群软件包,则必须选择"Download Packages",特别的,如果缺少任意基本集群组件(cman,rgmanager及其所依赖软件包),无论是否选择哪个,都会安装他们,否则节点创建失败
6). 如果需要集群的存储,则选择"Enable share storage support"来启动共享存储支持
参数配置完成后,点击"Create Cluster"创建集群。
集群创建完成后,如果出现下面的情形,节点Status为"Not a cluster member"
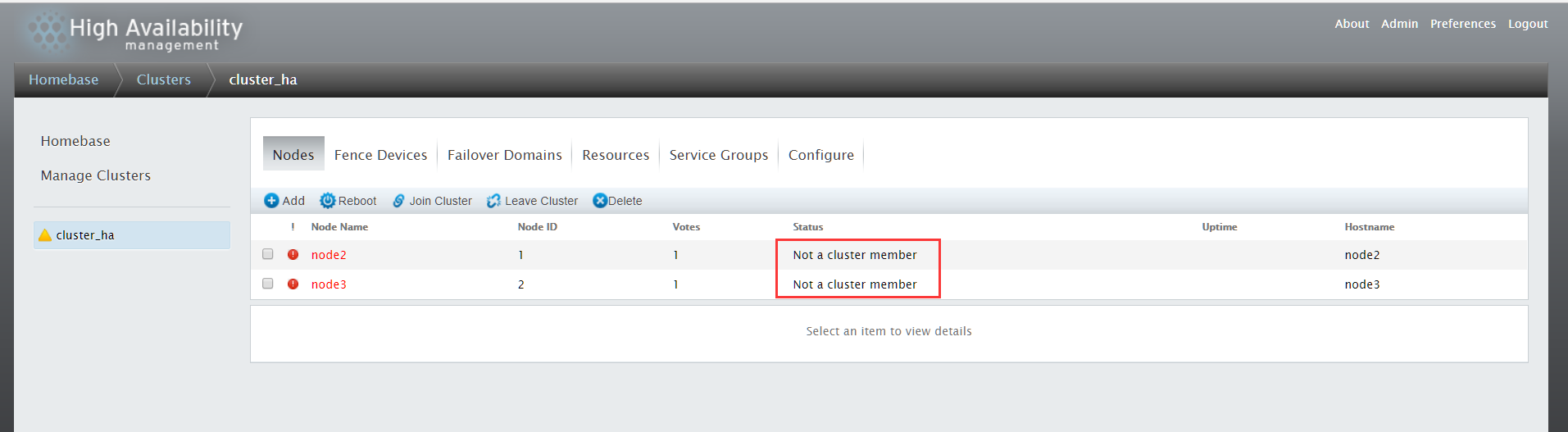
原因是cman和rgmanager服务未启动,启动这两个服务即可,注意启动顺序,先启动cman,然后再启动rgmanager。
另外启动cman时,要关闭NetworkManager服务(service NetworkManager stop),同时关闭该服务的开启启动chkconfig NetworkManager off。
cman和rgmanager服务开启后,点击"Nodes"

可以看到,node2和node3节点已经加入集群
4.4 添加Fence Devices设备
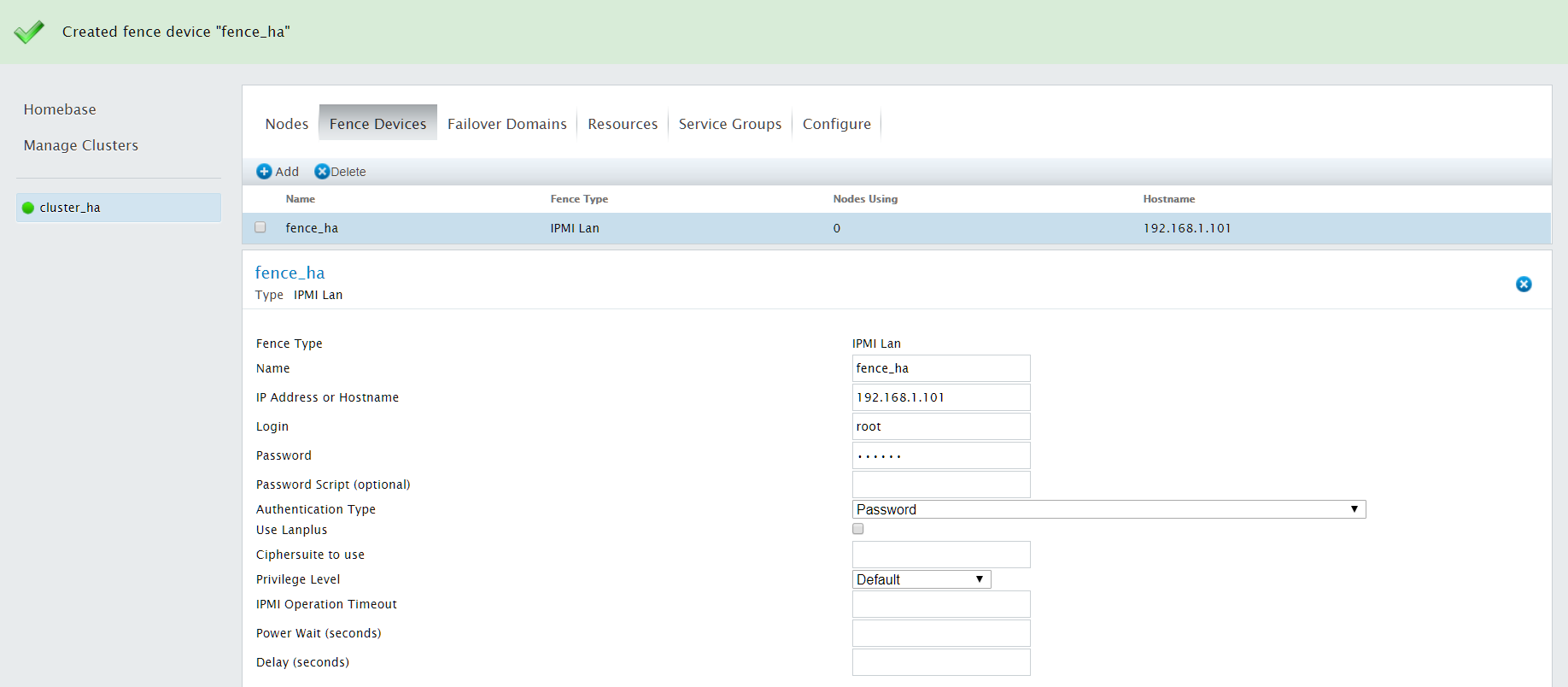
点击"Fence Devices",添加Fence Devices设备

点击add,选择IPMI Lan
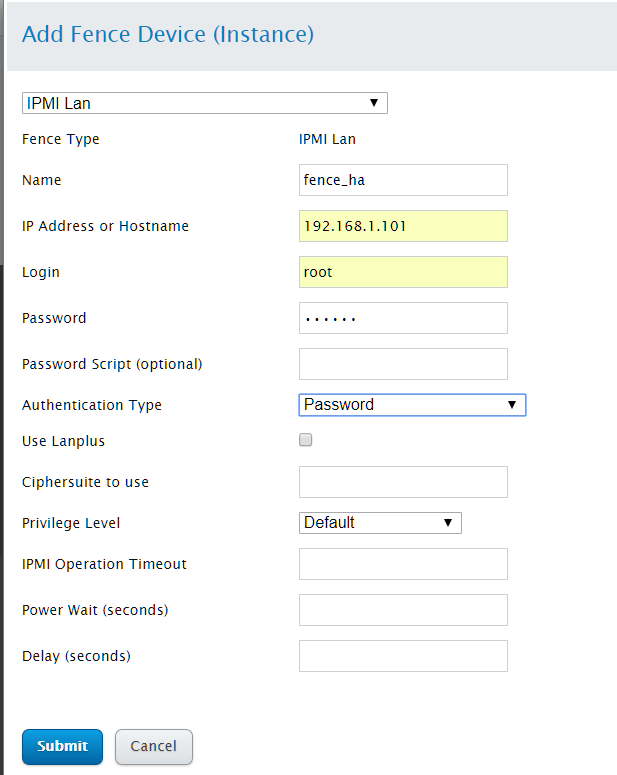
1). Name:填入对应主机fene设备的名字
2). IP address or hostname:fence设备主机IP或主机名
3). Login:管理端口用户名
4). Password:管理端口口令
参数配置完成后,点击"Submit"
4.5 为集群成员配置fence
给节点配置对应的fence设备,点击常规选项栏的"Nodes"

选择node2节点,点击进入配置界面
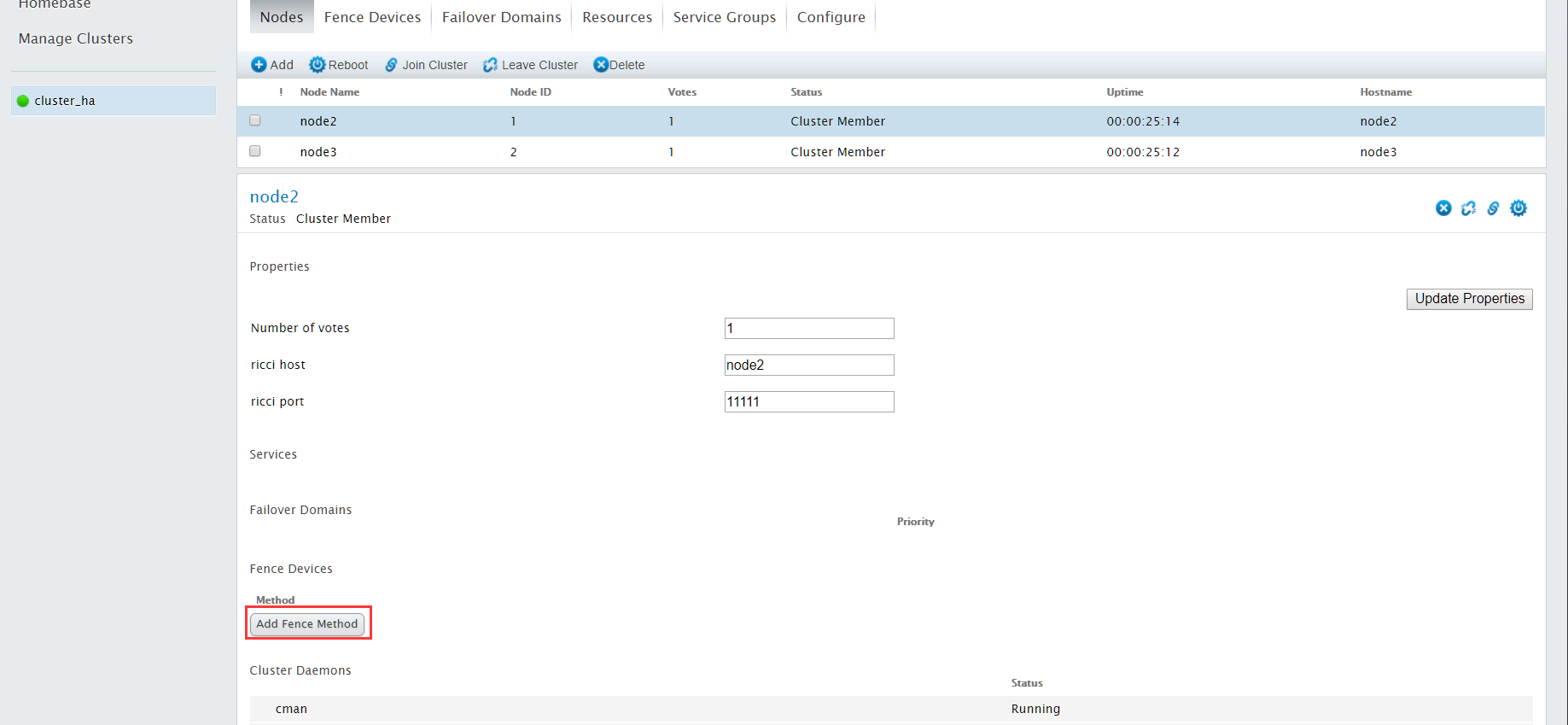
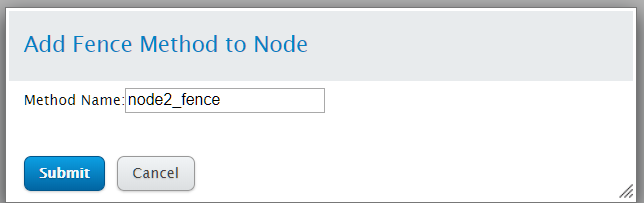
点击Add Fence Method,设置方法名
接下来点击Add Fence Instance
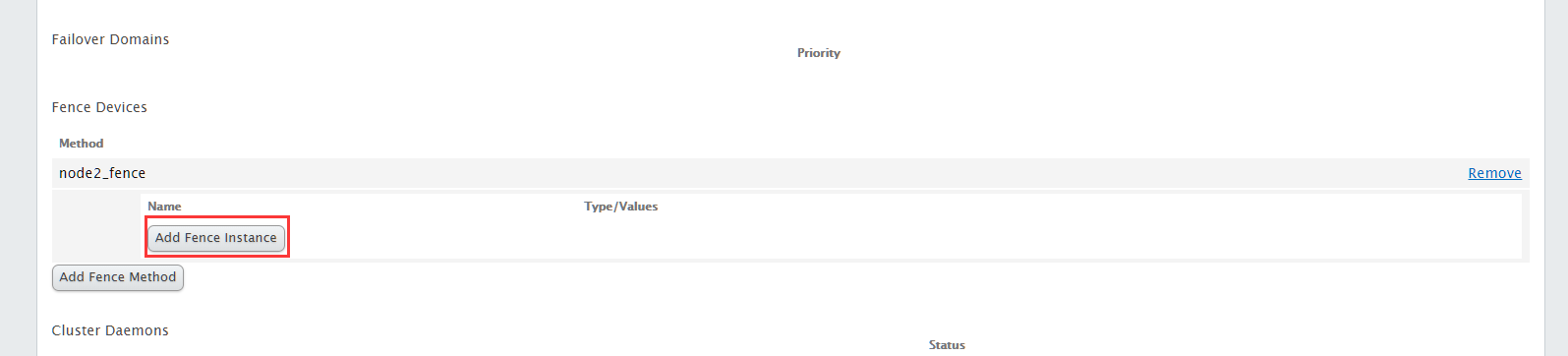
选择fence_ha
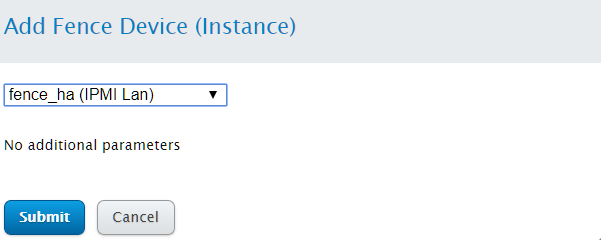
接下来为node3节点添加fence设备,过程同node2相似
4.6 配置Failover Domains
点击常规选择中的"Failover Domains"

设置"Failover Domains"的参数配置
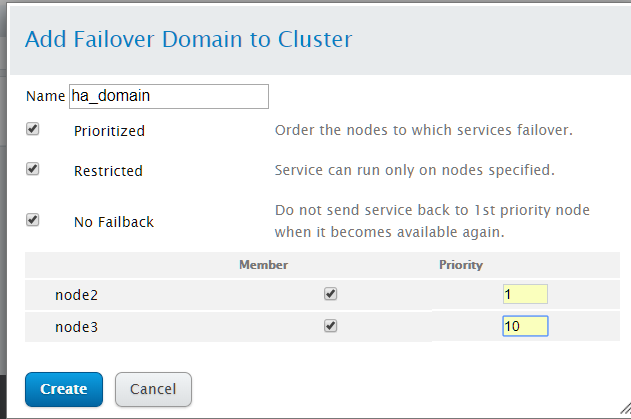
1). 输入故障切换域的名字
2). Prioritized:是否启用故障切换域成员间设置故障切换优先权,如果启用了,则可以为每个节点配置优先级
3). Restricted:是否在失败转移域成员中启用服务故障切换限制
4). No Failback:当最高优先级恢复时,不自动回切服务到最高优先级节点
5). Member: 勾选,则表示节点属于本故障切换域
6). Priority:指定优先级,priority值越小,表示优先级越高,为了以后添加节点方便,建议节点间优先级最好相差5左右
配置完Failover Domains相关参数后,点击create创建
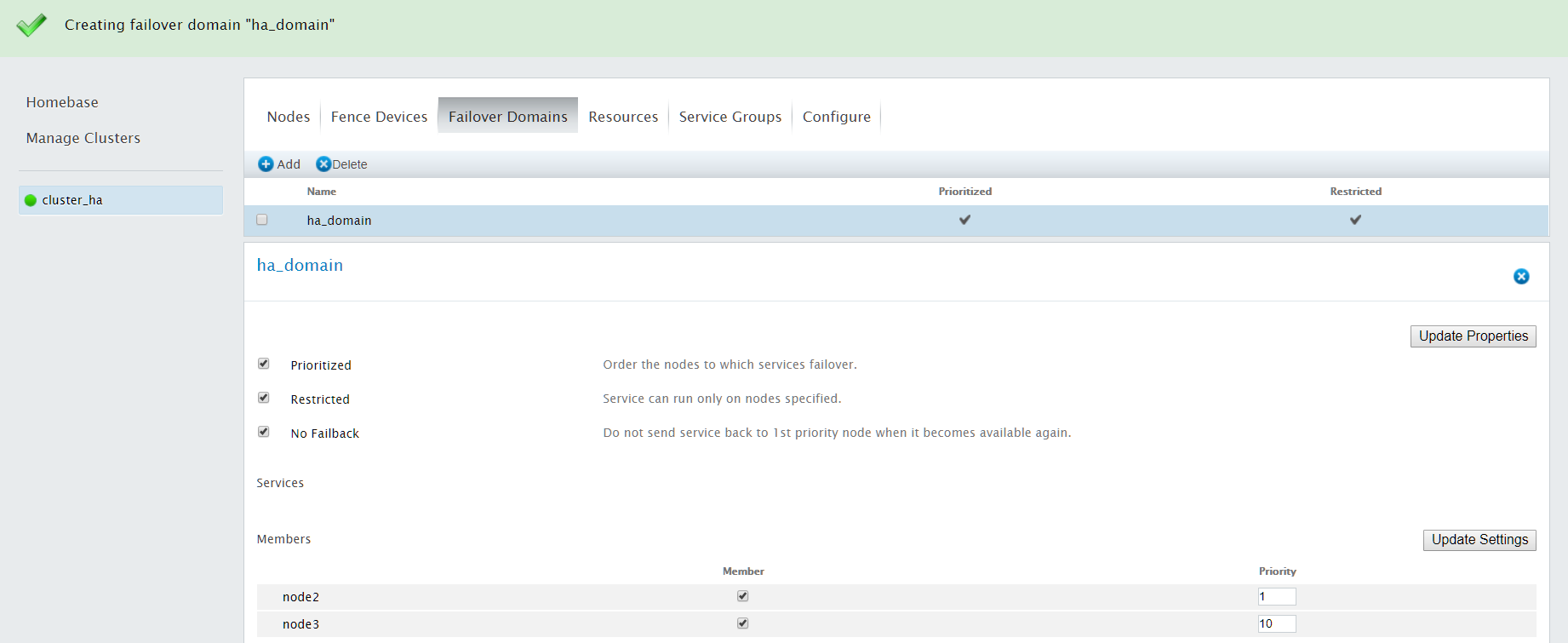
4.7 配置Resource
点击常规选择中的"Resources"

点击Add,创建IP Address资源
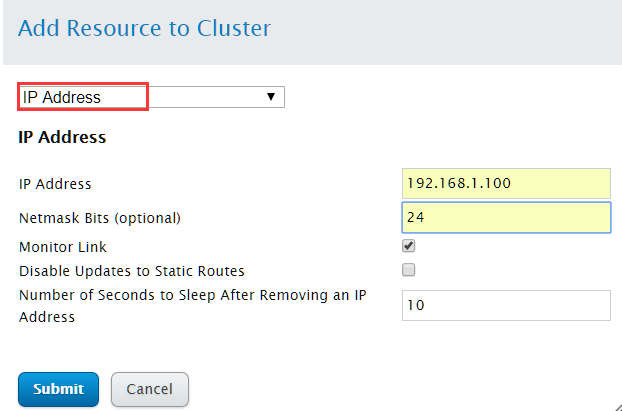
IP address:浮动IP地址
Netmask Bits:输入掩码设置
配置完成后,点击"Submit"
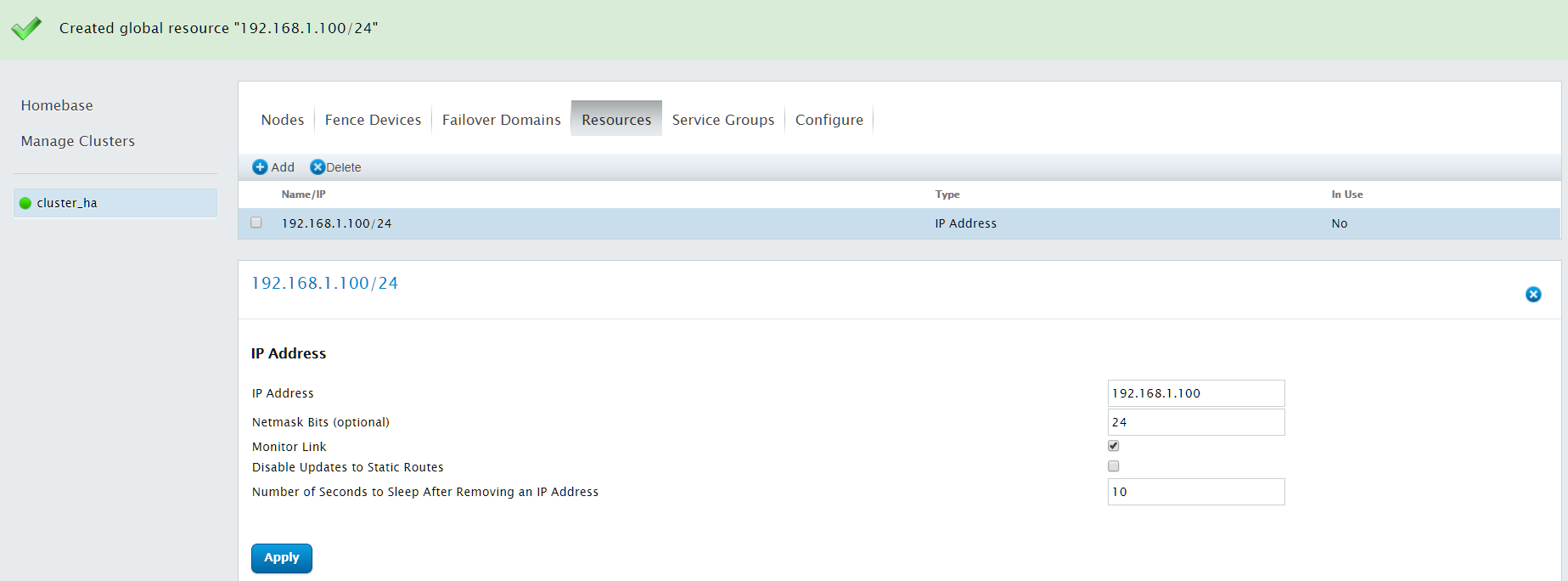
继续点击Add,创建Filesystem资源
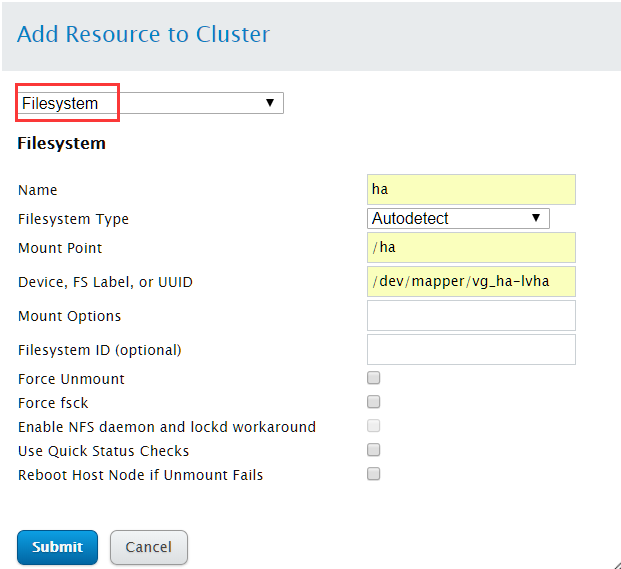
Name:指定filesystem资源名称
Filesystem Type:指定文件系统类型
Mount Point:指定文件系统挂载点
Device, FS Label, or UUID:指定逻辑卷设备路径
配置完成后,点击"Submit"
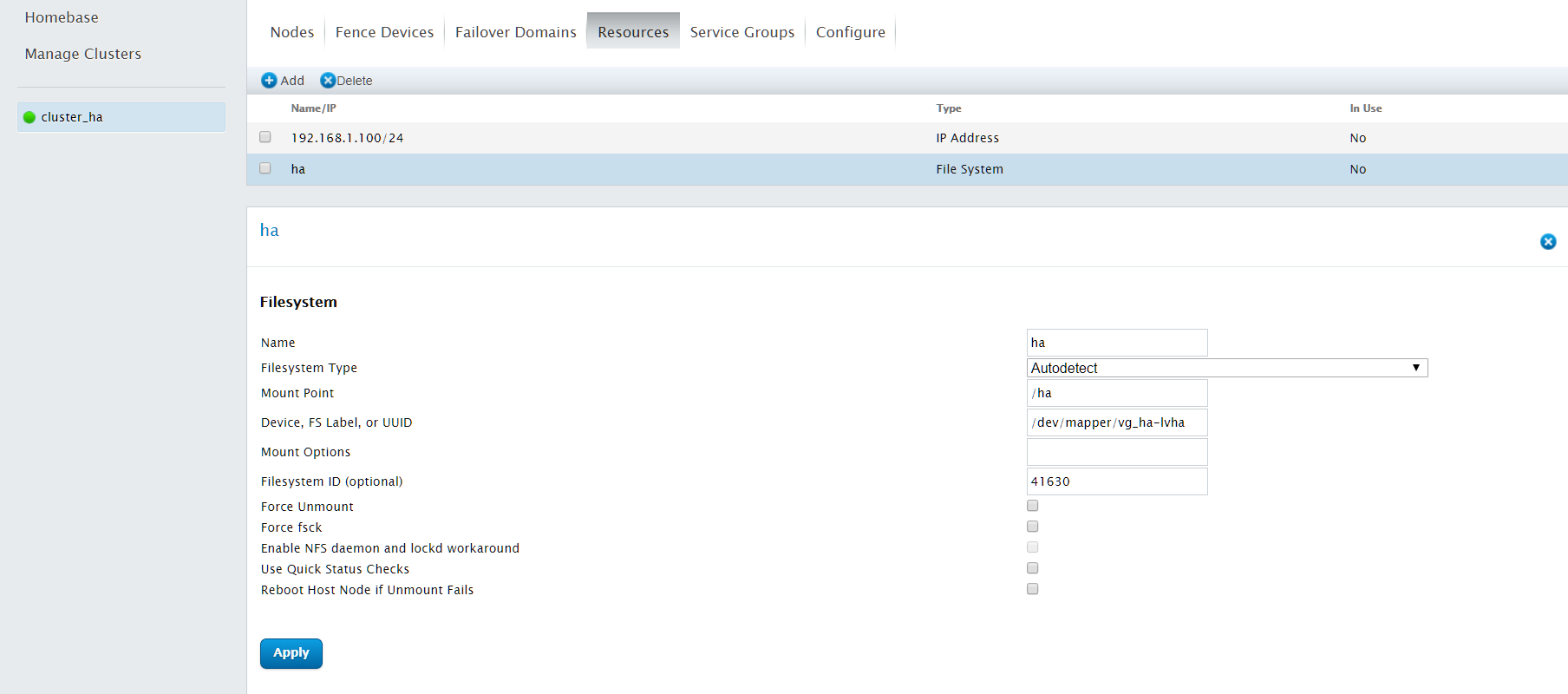
4.8 创建集群服务
点击常规选择中的"Service Group"

点击Add,添加服务组
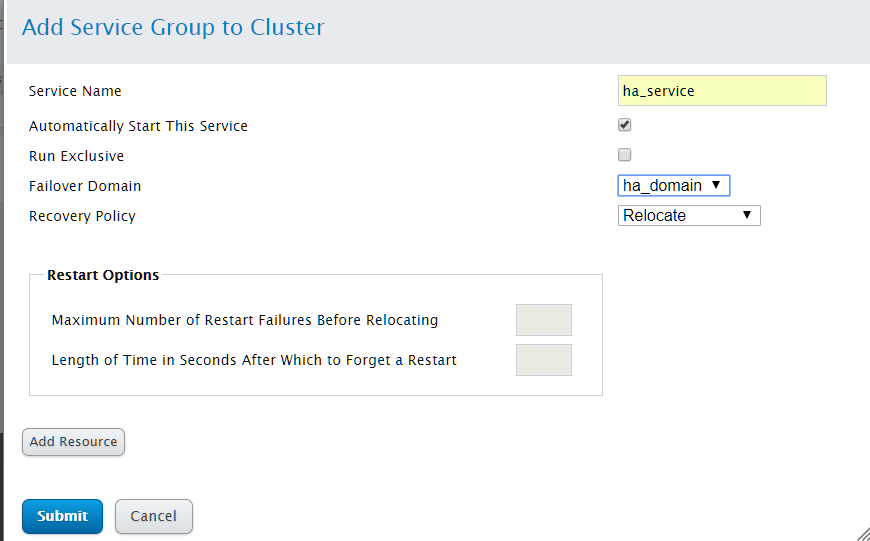
Service Name:指定服务组名
Automatically Start This Service:指定是否在启动集群时自动启动集群服务
Run Exclusive:指定是否选择只在没有服务运行的节点中运行
Failover Domain:指定服务组的故障切换域
Recovery Policy:指定恢复策略,RHCS提供的始终恢复策略:Relocate(表示服务失败时切换到别的节点)、Restart(表示重新定位该服务前尝试重启失败的服务)、Restart-Disable(表示系统应在服务失败的位置尝试重启该服务,但如果重启失败,则禁用该服务而不是移动到集群中的其它几点)、Disable(表示服务失败时关闭此服务)
配置完成后,点击"Submit"创建服务组

4.9 为已创建的集群服务添加资源
点击刚才创建的服务组ha_service
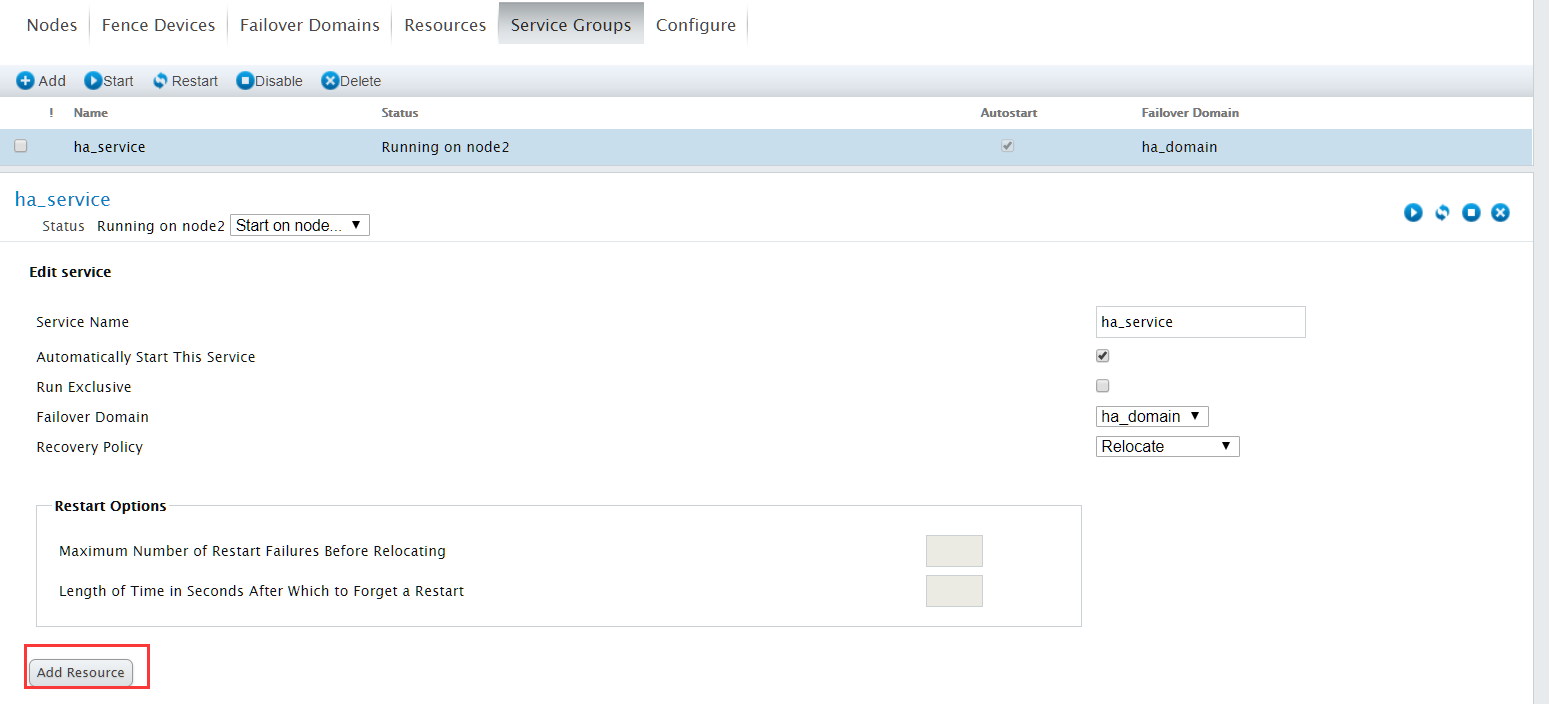
服务组中的资源不用配置依赖关系,直接点击Add Resource添加相应资源
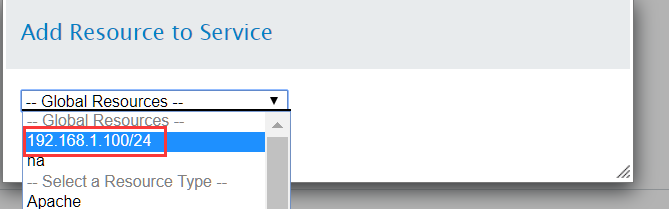
首先添加我们刚才创建的IP address资源
继续添加Filesystem资源
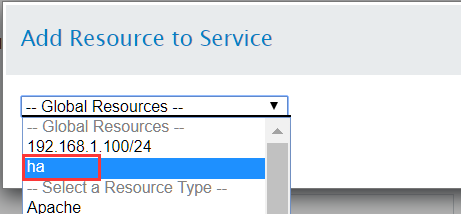
最后点击"Submit",提交服务
4.10 查看集群状态
在node2和node3上,执行clustat命令查看集群状态
[root@node2 ~]# clustat
Cluster Status for test @ Mon May 28 20:52:19 2018
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2 1 Online, Local, rgmanager
node3 2 Online, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:ha_service node2 started
[root@node3 ~]# clustat
Cluster Status for test @ Mon May 28 20:52:44 2018
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2 1 Online, rgmanager
node3 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:ha_service node2 started
因为服务运行在node2节点上,所以ip和filesystem资源都在node2上
[root@node2 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:d0:a4:dd brd ff:ff:ff:ff:ff:ff
inet 192.168.1.102/24 brd 192.168.1.255 scope global eth0
inet 192.168.1.100/24 scope global secondary eth0
inet6 fe80::20c:29ff:fed0:a4dd/64 scope link
valid_lft forever preferred_lft forever
[root@node2 ~]# df -h /ha
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_ha-lvha 981M 18M 915M 2% /ha
5 RHCS集群管理
5.1 启动RHCS集群
RHCS集群的核心进程有cman、rgmanager,依次在集群的每个节点执行如下命令
service cman start
service rgmanager start
注意:cman和rgmanager的启动是有顺序的,先启动cman,再启动rgmanager
5.2 停止RHCS集群
和启动命令相反,先停止rgmanager、再停cman服务
service rgmanager stop
service cman stop
注意:RHCS双机打印日志默认在/var/log/message中,可通过/var/log/message查看进程的启动和停止信息
5.3 设置集群服务开机自启
为了方便集群的运行,建议设置luci、ricci、cman和rgmanager服务开机自启
chkconfig luci on
chkconfig ricci on
chkconfig cman on
chkconfig rgmanager on
5.4 管理RHCS集群
使用clusvcadm命令可以disable、enable、切换(relocate)、重启(restart)RHCS服务。
(1) disable的命令格式clusvcadm –d <group>(比如clusvcadm -d ha_service)
(2) enable的命令格式clusvcadm –e <group> -m <member> (比如clusvcadm -e ha_service -m node2),如果未指定member,将会在当前节点启动服务
(3) relocate的命令格式clusvcadm –r <group> -m <member>(比如clusvcadm –r ha_service -m node3>)
(4) restart的命令格式clusvcadm –R <group> -m <member>(比如clusvcadm –R ha_service -m node3>)
6. RHCS测试
我们关机node2节点,等待几分钟,观察服务是否转移到node3上
[root@node3 ~]# clustat
Cluster Status for test @ Mon May 28 21:39:30 2018
Member Status: Quorate
Member Name ID Status
------ ---- ---- ------
node2 1 Online
node3 2 Online, Local, rgmanager
Service Name Owner (Last) State
------- ---- ----- ------ -----
service:ha_service node3 started
[root@node3 ~]#
[root@node3 ~]# ip a
1: lo: <LOOPBACK,UP,LOWER_UP> mtu 16436 qdisc noqueue state UNKNOWN
link/loopback 00:00:00:00:00:00 brd 00:00:00:00:00:00
inet 127.0.0.1/8 scope host lo
inet6 ::1/128 scope host
valid_lft forever preferred_lft forever
2: eth0: <BROADCAST,MULTICAST,UP,LOWER_UP> mtu 1500 qdisc pfifo_fast state UP qlen 1000
link/ether 00:0c:29:34:be:b3 brd ff:ff:ff:ff:ff:ff
inet 192.168.1.103/24 brd 192.168.1.255 scope global eth0
inet 192.168.1.100/24 scope global secondary eth0
inet6 fe80::20c:29ff:fe34:beb3/64 scope link
valid_lft forever preferred_lft forever
[root@node3 ~]#
[root@node3 ~]# df -h /ha
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/vg_ha-lvha 981M 18M 915M 2% /ha
可以看到资源已经成功转移到node3节点上。
重启node2节点,查看集群状态。