原题:
神经网络
时间限制: 1 Sec 内存限制: 256 MB
题目描述
人工神经网络(Artificial Neural Network)是一种新兴的具有自我学习能力的计算系统,在模式识别、函数逼近及贷款风险评估等诸多领域有广泛的应用。对神经网络的研究一直是当今的热门方向,兰兰同学在自学了一本神经网络的入门书籍后,提出了一个简化模型,他希望你能帮助他用程序检验这个神经网络模型的实用性。
在兰兰的模型中,神经网络就是一张有向图,图中的节点称为神经元,而且两个神经元之间至多有一条边相连,下图是一个神经元的例子:
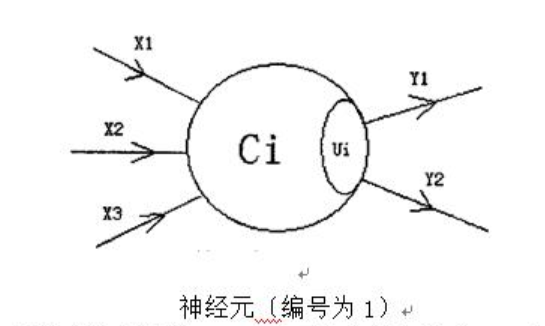
图中,X1−X3是信息输入渠道,Y1−Y2是信息输出渠道,C1表示神经元目前的状态,Ui是阈值,可视为神经元的一个内在参数。
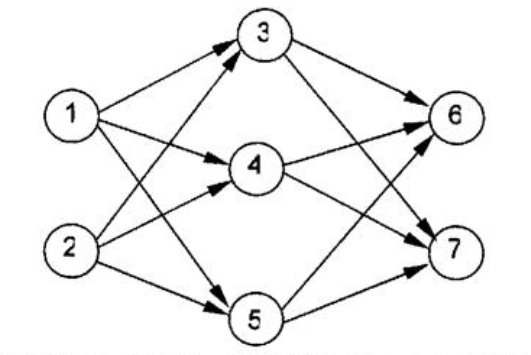
神经元按一定的顺序排列,构成整个神经网络。在兰兰的模型之中,神经网络中的神经元分为几层;称为输入层、输出层,和若干个中间层。每层神经元只向下一层的神经元输出信息,只从上一层神经元接受信息。下图是一个简单的三层神经网络的例子。
兰兰规定,Ci服从公式:(其中n是网络中所有神经元的数目)
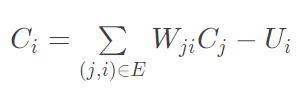
公式中的Wji(可能为负值)表示连接j号神经元和i号神经元的边的权值。当Ci大于0时,该神经元处于兴奋状态,否则就处于平静状态。当神经元处于兴奋状态时,下一秒它会向其他神经元传送信号,信号的强度为Ci。
如此.在输入层神经元被激发之后,整个网络系统就在信息传输的推动下进行运作。现在,给定一个神经网络,及当前输入层神经元的状态(Ci),要求你的程序运算出最后网络输出层的状态。
输入格式
输入文件第一行是两个整数n(1≤n≤200)和p。接下来n行,每行两个整数,第i+1行是神经元i最初状态和其阈值(Ui),非输入层的神经元开始时状态必然为0。再下面P行,每行由两个整数i,j及一个整数Wij,表示连接神经元i、j的边权值为Wij。
输入格式
输出文件包含若干行,每行有两个整数,分别对应一个神经元的编号,及其最后的状态,两个整数间以空格分隔。仅输出最后状态非零的输出层神经元状态,并且按照编号由小到大顺序输出!
若输出层的神经元最后状态均为 0,则输出 NULL。
输入输出样例
输入
5 6
1 0
1 0
0 1
0 1
0 1
1 3 1
1 4 1
1 5 1
2 3 1
2 4 1
2 5 1
输出
3 1
4 1
5 1
题面有点复杂,刚看的时候我也被绕进去了 ( ╯-_-)╯┴—┴(面无表情地掀桌)。
摁住桌板仔细看一遍,我们就会明白出题老师是如何把简单东西弄成一堆我们看不懂的东西的。。。
好了回到正题——
题意:
有一张不自环的有向图,每个点都有一个值(阈值)和初始状态,从初始状态为1的点开始遍历,按题中所述计算每个点的值,求最后状态由0变为1的点的编号。
前置芝士
显而易见的,这是一道拓扑排序的模板题。
那么,什么是拓扑排序?
拓扑排序不是像冒泡排序、插入排序、归并排序......它并不是对一组数据进行大小比较,而是指一张有向图的遍历方法(不带环)
举一个简单的例子
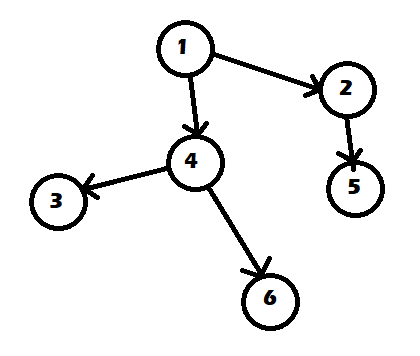
这张图中,我们首先找一个起始点,使它不被任何边指向,称之“入度为零”。
然后找到它指向的点,图中为4号与5号。
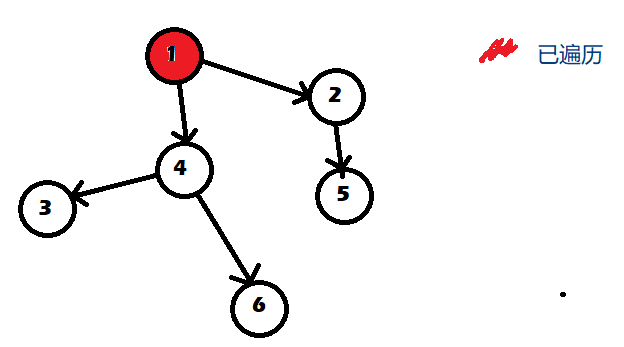
现在,1号已经没有用了,所以把1号取出。接下来可以发现2号和4号的入度也变成了零,所以把它们也取出,遍历它们指向的点。
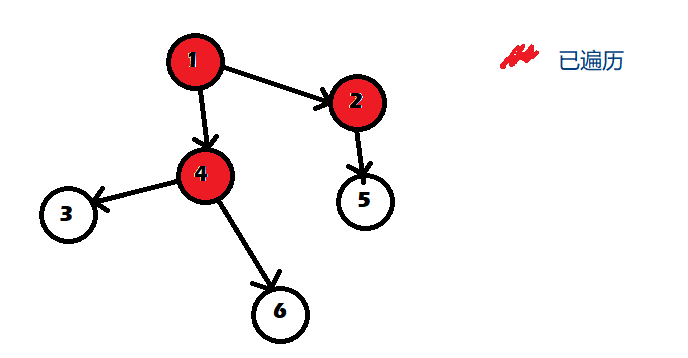
剩下的3号,5号,6号都没有被别的边指向,所以都可以取出。
好了,图就这么轻松的遍历完了。
拓扑排序的顺序可以有很多种,比如上面的图可以是1→2→4→5→3→6,也可以是1→2→4→3→6→5,也可以是......
题中满足无环、有向,所以是非常明显的拓扑排序题。
我觉得已经讲得非常详细了,那么(敲黑板划重点)——
如何实现?
在之前的讲述中,我们注意到有一个非常重要的名词——入度。
(某同学:既然有“入度”,是不是也有“出度”? 当然是的!这里就不具体展开了,自行百度)
我们自然而然的想到了敲代码的方法——读入边的时候,记录一次入度,记录一次出度("rd"即"入度","cd"即"出度")
void add(int a,int b,int c) { Next[++tot]=head[a],vet[tot]=b,len[tot]=c; head[a]=tot; }
for(int i=1; i<=m; i++) { int a,b,c; scanf("%d%d%d",&a,&b,&c); add(a,b,c); cd[a]++; rd[b]++; }
这里的add函数使用到了邻接表的做法,不明白的同学看这里(Angel_Kitty大佬)
while(le<ri) { int x=q[++le]; for(int i=head[x]; i; i=Next[i])//遍历指向的点 { int y=vet[i],z=len[i]; cc[y]=cc[y]+cc[x]*z;//题中运算 rd[y]--;//遍历到后就把来时的边舍弃不用(图是有向的嘛),入度减一 if(rd[y]==0)//如果没有边指向它,就取出判断 { cc[y]-=u[y]; if(cc[y]>0) q[++ri]=y;//大于零就储存到队列 } } }
干脆爽口的代码(点击左上角复制):
1 #include<bits/stdc++.h> 2 using namespace std; 3 const int M=205; 4 int n,m,cc[M],u[M]; 5 int rd[M],cd[M]; 6 int q[M],le,ri; 7 int tot,head[M],Next[M*M],vet[M*M],len[M*M]; 8 void add(int a,int b,int c){ 9 Next[++tot]=head[a],vet[tot]=b,len[tot]=c; 10 head[a]=tot; 11 } 12 int main(){ 13 scanf("%d%d",&n,&m); 14 for(int i=1; i<=n; i++){ 15 scanf("%d%d",&cc[i],&u[i]); 16 if(cc[i]>0) q[++ri]=i; 17 } 18 for(int i=1; i<=m; i++){ 19 int a,b,c; scanf("%d%d%d",&a,&b,&c); 20 add(a,b,c); 21 cd[a]++; 22 rd[b]++; 23 } 24 while(le<ri){ 25 int x=q[++le]; 26 for(int i=head[x]; i; i=Next[i]){ 27 int y=vet[i],z=len[i]; 28 cc[y]=cc[y]+cc[x]*z; 29 rd[y]--; 30 if(rd[y]==0){ 31 cc[y]-=u[y]; 32 if(cc[y]>0) q[++ri]=y; 33 } 34 } 35 } 36 int cnt=0; 37 for(int i=1; i<=n; i++){ 38 if(cd[i]==0&&cc[i]>0){ 39 printf("%d %d ",i,cc[i]); cnt++; 40 } 41 } 42 if(cnt==0) printf("NULL "); 43 return 0; 44 }