数仓是什么
面向主题的,集成,不可更改的,随时间不断变化的数据集合,用来做决策分析
为什么需要数据仓库
在大数据时代:
传统数据库无法满足快速增长的海量数据存储需求,无法有效处理不同类型的数据,
计算能力不足,可扩展性差
OLTP 和OLAP的区别
OLTP遵循三范式,不存在数据冗余,擅长数据的修改
OLAP不遵循三范式,join操作少,查询效率快,擅长数据分析
数仓理论
Inmon理论
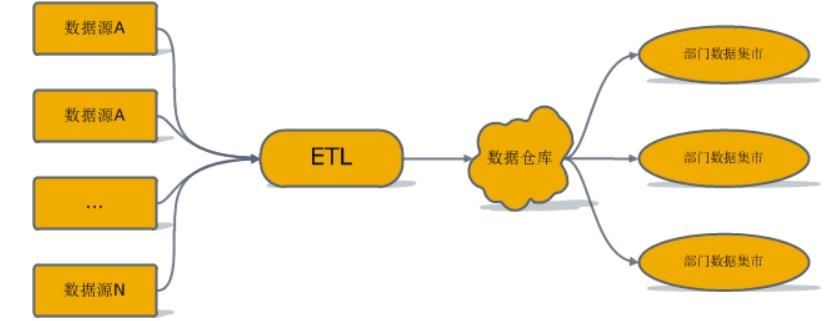
Inmon 模式从流程上看是自顶向下的,即从数据源到数据仓库再到数据集市的(先有数据仓库再有数据集市)一种瀑布流开发方法。
对于Inmon模式,数据源是多样的。
Inmon是以数据源头为导向,首先,需要探索性地去获取尽量符合预期的数据,尝试将数据按照预期划分为不同的表需求,
清洗完数据之后将数据抽象为实体-关系模型,采用三范式。
该套建模理论通过规范化建模后得到一个关系型的中心数据库,然后各部门基于中心数据库进行维度建模,搭建数据集市,
开发人员通过数据集市获取数据,一般不直接从中心数据库获取数据
图解:
kimball理论
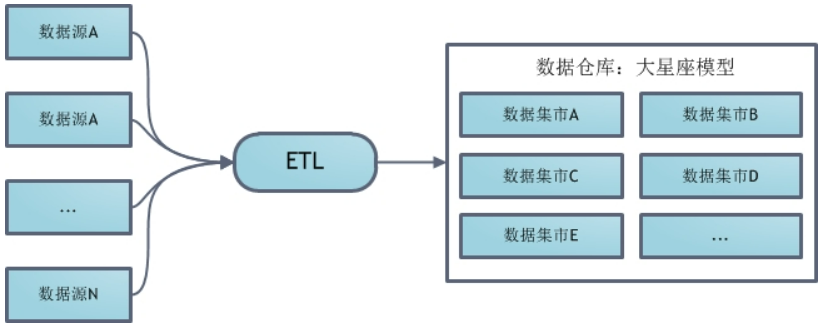
Kimball 模式从流程上看是是自底向上的,即从数据源到数据集市再到数据仓库(先有数据集市再有数据仓库)的一种敏捷开发方法。
对于Kimball模式,数据源往往是给定的若干个数据库表,数据来源较稳定。
维度表和事实表是以需求为导向,根据业务需求创建维度表和事实表,不采用三范式,会存在一定的数据冗余。
kimball理论从数据源获取数据后直接进行维度建模,维度之间互相交错,最终一般呈现为星座模型,整个星座模型就是数据仓库
示例:
总结
-
对于大多数互联网公司由于需求的快速变化,处心积虑设计(Inmon)实体-关系的设计哲学似乎并不能满足快速迭代的业务需要。所以,更多场景下趋向于使用(Kimball)维度-事实的设计哲学反而可以更快地完成任务。
-
数据仓库建设通常以日为粒度,将OLTP数据变化的不情况增量同步到数据仓库中。
-
在数据仓库的实际工作中,80%的时间会花费在任务调度、数据清洗和业务梳理上,只有20%的时间会投入到数据挖掘上。
因此我们将基于kimball理论搭建数仓。
数仓命名规范

分层
为什么分层:
1.复杂问题简单化,容易定位问题
2.减少重复开发,利用中间层数据,大大减少重复计算,增加数据复用性
3.隔离原始数据,将统计数据和原始数据隔离开
如何分层:
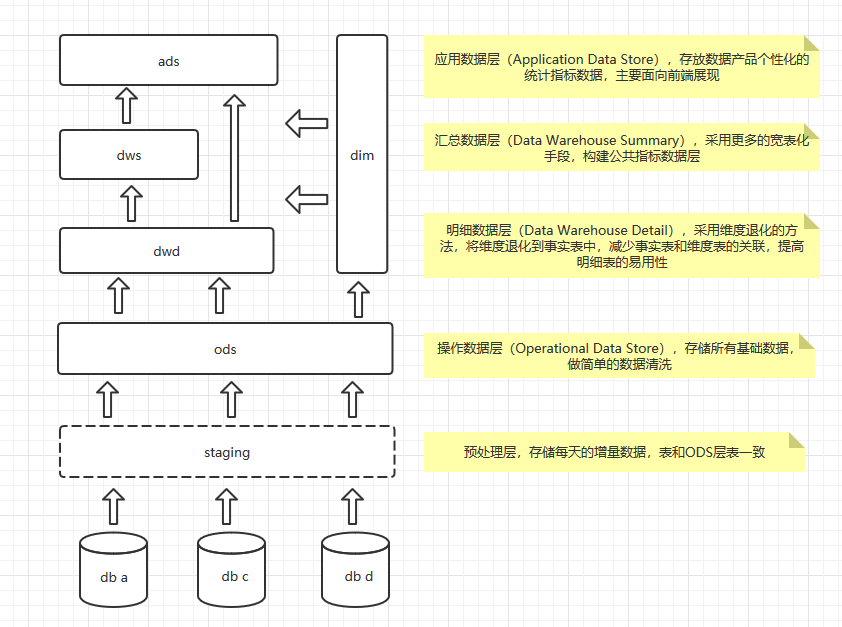
Ods层:存放原始数据
Dwd层:数据清洗(去空,脏数据,不合理数据),维度退化,脱敏等
Dws层:以dwd为基础,按天进行轻度汇总
Dwt层:以dws为基础,按主题(维度)进行汇总
Ads层:以dwt,dws为基础,为报表提供数据
数仓建模(主要在dwd层建模)
常用建模方式:
1.关系建模:三范式 -> 属性不可分割;不存在部分函数依赖;不存在传递依赖
好处:不会造成冗余数据,但常常需要进行多次join操作
2.维度建模:不遵循三范式,分为维度表,事实表
好处:join操作少,mr计算速度大大加快
维度表:主要是描述信息,比如对商品的描述。
事实表:用户做了什么,比如今天10点,用户买了一部手机。
特征:字段多为外键或可进行度量的值
数据仓库建模方式:维度建模
三大维度建模模型:
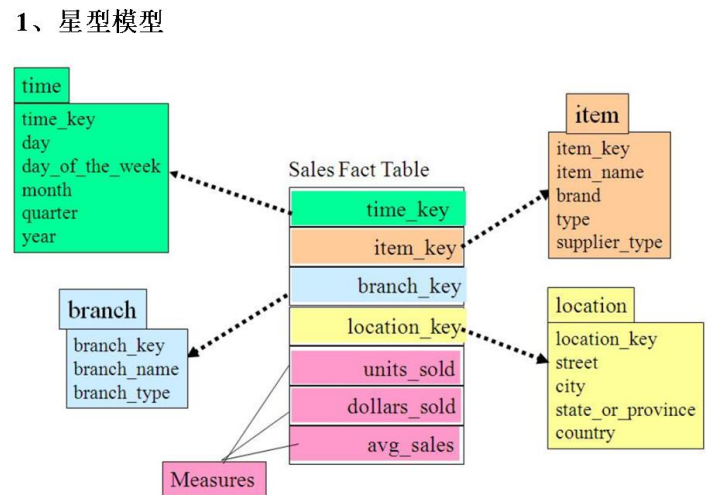
星型模型:事实表周围只有一层维度(join操作最少,冗余数最多)
雪花模型:两层维度以上
星座模型:多个事实表共用一个维度(星座模型和前两种模型不冲突)
一般采用星型模型,但呈现出来的是星座模型
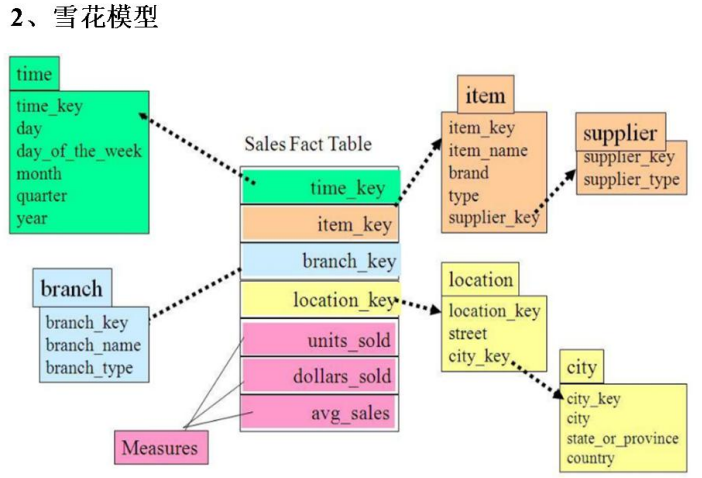

建模:
ods:
- 选择业务过程
- 声明粒度
- 确定事实表和维度表(事实表和ods层的表不会有太大差别)
- 维度退化(将与维度相关的表进行合并)
dws:
dwt:
ads: