昨日内容回顾 迭代器 迭代:更新换代(基于上一次结果) 迭代取值的工具 特点:提供了一种不依赖于索引取值的方式 可迭代对象 内置有__iter__方法的对象都称之为可迭代对象 str list tuple dict set 文件对象 可迭代对象调用__iter__方法之后会有一个返回值,这个返回值就是一个迭代器对象 迭代器对象 既有__iter__又有__next__的对象称之为迭代器对象 文件对象本身就是迭代器对象 ps:为什么迭代器对象还需要有__iter__方法? 解:迭代器对象无论调用多少次__iter__得到的还是迭代器本身 因为for循环后面in(如果迭代器没有__iter__那么for循环当传入迭代器对象的时候会直接报错) 总结:迭代器对象肯定是可迭代对象,而可迭代对象不一定是迭代器对象 迭代器对象.__next__() 依次从迭代器中取值 ps: 1.如果__next__取完了迭代器对象中的值再取直接报错 报错类型StopIteration 2.只能从前往后取 不能往回 不能指定位置取 暂时了解:异常捕获(异常处理) 你拿不住几行代码可能会报错,你就可以用异常处理的方式来实时监测那几行代码 一旦报错类型与你之前猜测的类型一致,那么异常会自动被你的异常处理代码捕获 执行你事先写好的出错之后的代码逻辑 补充 __iter__() 等价于 iter() __len__() 等价于 len() __next__() 等价于 next() for循环内部原理 1.将in对面对象调用__iter__先装换成迭代器对象 2.调用__next__方法迭代取值 3.针对__next__采用异常捕获的方式 当报错直接结束整个for循环 range(10) for i in range(10): res = range(10).__iter__() while True: try: print(res.__next__) except StopIteration: break 生成器 本质就是迭代器,只不过这个生成器使我们自己自定义的迭代器 关键字 yield def index(): print('index') yield 111 yield 333 yield 444 yield 222 index.__iter__ index.__next__ print(index) 在调用内部有yield关键字的函数之前 该函数就是一个普普通通的函数 index() 函数内如果包含yield关键字 那么在加括号调用的时候 不会执行函数体代码 只会将函数初始化为生成器 res = index.__next__() print(res) # None >>> 111 yield 可以返回值 并且也支持返回多个 以元组的形式 可以保存函数运行状态 还可以接收外界传参(前提:必须先让代码运行至yield位置,才能够通过send传参) args = yield 111 喂狗的例子 可以执行多次yield,而return执行一次之后函数立刻结束 自定义range功能 def my_range(start,end,step=1): while start < end: yield start start += step 生成器表达式(时刻记在脑子里,当项目优化的时候 你应该能够想到这一点) res = (i**2 for i in [1,2,3,4,5,6,]) 不调用__next__方法 生成器内部代码一句都不会运行 生成器表达式通常用在获取较大容器类型数据的时候 内置函数 map zip filter reduce sorted max min sum dir abs chr ord all any oct hex bin eval exec enumerate callable isinstance(要判断的对象,类型) globals() locals() len list str int float set bool dict get open bytes(字符串,encoding='utf-8') str(bytes类型,encoding='utf-8') pow divmod 可以用在网站分页 round help 面向过程编程 面向过程变成就类似于设计一条流水线 将复杂的问题 流程化 进而简单化 可扩展性差(牵一发而动全身) 以注册功能为例 1.获取用户用户名和密码(前端) 2.对信息进行格式处理(后端) 3.保存到文件中(数据库)
异常处理:
"""异常处理""" d=(i for i in range(5)) while True: try: d.__next__() except Exception: print('超出范围') break # Exception 万能异常 异常有两大类 1 语法结构错误 :需要你当场修改 异常无法捕获 # 第二类 逻辑错误 异常可以处理
什么是模块
模块:就是一系列功能的结合体
模块的三种来源:
1.内置的(python解释器自带) 2.第三方的(别人写的 3.自定义的(你自己写的)
模块的四种表现形式
1.使用python编写的py文件(也就意味着py文件也可以称之为模块:一个py文件也可以称之为一个模块)
2.已被编译为共享库或DLL的C或C++扩展(了解)
3.把一系列模块组织到一起的文件夹(文件夹下有一个__init__.py文件,该文件夹称之为包)包:一系列py文件的结合体
4.使用C编写并连接到python解释器的内置模块
为什么要用模块
1.用别人写好的模块(内置的,第三方的):典型的拿来主义,极大的提高开发效率
2.使用自己写的模块(自定义的):当程序比较庞大的时候,你的项目不可能只在一个py中
那么当多个文件中都需要使用相同的方法的时候 可以将该公共的方法写到一个py文件中
其他的文件以模块的形式导过去直接调用即可
ps:只要你能拿到函数名 无论在哪里都可以加括号调用 因为函数在定义阶段 名字的查找顺序就已经固定了 不会
因为你调用的位置变化而变化
如何使用模块
一定要区分哪个是执行文件,哪个是被导入文件
使用import 导入模块 访问名称空间的名字统一句式 : import 模块名 . 名字
import time time.time 用点就可以使用模块内的功能了
1 指名道姓的访问模块中的名字 永远不会和你文件的名字冲突
2 如果 你想访问模块中的名字 必须使用句式 文件名(模块名).名字
import 导入多次不会执行 只会执行第一次的导入结果
当模块名比较复杂的时候可以取别名来代替 例如 import time as t 之后你想调time里面的功能时候 就可以在t后加点来使用了
假如你想导入多个模块 可以使用 import 模块名,模块名 但是不推荐 只要当前几个模块有相同部分 或者 属于 同一个模块 可以使用以上方法
当几个模块没有联系的情况下 应该多次导入
import 函数名,函数名,函数名 import 模块名 import 模块名 import 模块名
模块的导入模式一般在文件的开头
使用 from...import.....句式来导入
同样多次导入不会执行 会沿用第一次的导入成果 可以导入 不同文件夹的模块 但是需要在同一目录下
使用from....import*句式可以一次性将模块中的所有名字加载出来 但是不推荐使用 因为你不知道有多少名字
使用__all___可以指定当所在py文件被当做模块导入的名字 可以限制导入者能够拿到的名字个数
__all__=['name',.......]
循环导入
如果出现循环导入问题 那么一定是你的程序设计的不合理 循环导入问题应该在程序设计阶段就应该避免 解决循环导入问题的方式
1.方式1
将循环导入的句式写在文件最下方()
2.方式2
函数内导入模块
__name__ 的用法 :
# print(__name__) # 当文件被当做执行文件执行的时候__name__打印的结果是__main__ # 当文件被当做模块导入的时候__name__打印的结果是模块名(没有后缀) if __name__ == '__main__': index1() index2() if __name__ == '__main__': # 快捷写法 main直接tab键即可 index1() index2()
模块的查找顺序
1.先从内存中找
2.内置中找
3.sys.path中找(环境变量):
一定要分清楚谁是执行文件谁是被导入文件(******)
是一个大列表,里面放了一对文件路径,第一个路径永远是执行文件所在的文件夹
注意py文件名不应该与模块名(内置的,第三方)冲突
import sys sys.path.append(r'D:Python项目day14dir1') 添加环境变量
绝对导入必须依据执行文件所在的文件夹路径为准
1.绝对导入无论在执行文件中还是被导入文件都适用
相对导入
.代表的当前路径
..代表的上一级路径
...代表的是上上一级路径
注意相对导入不能再执行文件中使用
相对导入只能在被导入的模块中使用,使用相对导入 就不需要考虑
执行文件到底是谁 只需要知道模块与模块之间路径关系
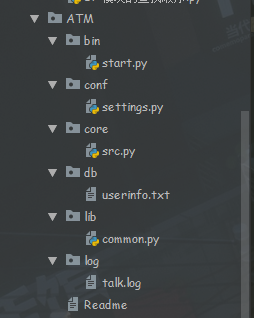
软件开发目录规范