声明:本文是站在回归分析角度讲的,分类的理解可能跟这有点不一样。
1.前言
随机森林也是集成方法的一种,是对Bagging算法的改进。
随机森林主要有两步组成:
1)有放回的随机抽取样本数据,形成新的样本集。这部分和Bagging算法一样,但是有两点需要注意:
a)新的样本集的大小和原始样本集的大小是一样的。假如原始样本有1000个数据,那么新样本集也要包括1000个数据,只是新样本集里面会含有部分重复的数据,这样可以避免过度拟合的问题。
b)每生成一个决策树,都需要重新对原始数据进行取样。假如进行k次训练(即生成k课树),那么就需要重复k次这个动作
2)无放回的随机抽取属性列。假如有12个属性(即12列),从这12个属性列中随机抽取无重复的n列(一般建议是总属性的1/3)进行运算。每次训练都需要重新抽取
2.算法实现思路
该算法的核心就是如何实现上述两个步骤,过程如下:
1)有放回的随机抽取样本数据
a)定义一个需要抽取的数据的索引列表
b)使用随机函数随机生成和数据集同样大小的数值填充到索引列表中
c)对数据索引列表排序
d)抽取包含在索引列表中的数据重新组成样本集,并抽取对应的标签值组成标签集
2)无放回的随机抽取属性列
a)定义一个需要抽取的属性的索引列表
b)使用随机函数随机生成和属性数量同样大小的数值填充到索引列表中
c)对属性索引列表排序
d)抽取包含在属性索引列表中的属性重新组成属性集
3)从新的样本集中按照新的属性集抽取样本数据集及标签值,然后进行分析
3.实现过程
实验数据还是使用分析红酒口感时使用的数据。原始数据来源
1)划分数据。
把数据划分成训练集和测试集,并把数据和标签拆分开。这里多说一点,在进行分析时,一定要把数据分成训练集和测试集,不能在训练集上训练出模型后,然后再用训练集得出的预测值用于后续分析。因为刚开始的时候对随机森林的理解有点偏差,所以没有划分训练集和测试集,结果反应均方误差随模型个数变化的曲线一直是波浪线。
import numpy as np import matplotlib.pyplot as plt import os from sklearn.tree import DecisionTreeRegressor import random ##运行脚本所在目录 base_dir=os.getcwd() data=np.loadtxt(base_dir+r"wine.txt",delimiter=";") dataLen = len(data) ##矩阵的长度:行数 dataWid = len(data[0]) ##矩阵的宽度:列数 ''' 第一步:划分训练集和测试集 ''' ##测试集大小:这里选择30%作为测试集,70%作为训练集 nSample = int(dataLen * 0.30) ##在0~dataLen直接随机生成nSample个点 idxTest = random.sample(range(dataLen), nSample) idxTest.sort() #定义训练集和测试集标签 xTrain = [] #训练集 xTest = [] #测试集 yTrain = [] #训练集标签 yTest = [] #测试集标签 ##划分数据:每行数据最后一个是标签值 for i in range(dataLen): row = data[i] if i not in idxTest: xTrain.append(row[0:dataWid-1]) yTrain.append(row[-1]) else : xTest.append(row[0:dataWid-1]) yTest.append(row[-1])
2)使用随机森林算法训练数据
这里还是使用sklearn包中的二元决策树函数DecisionTreeRegressor作为主要的分析函数。
另外还需要说两个随机函数(不是numpy里面的):
random.choice(range(n)):在range形成的列表里面随机抽取一个
random.sample(range(n),m):在range形成的列表里面无重复的随机抽取m个数
''' 第二步:使用随机森林算法训练数据 ''' modelList = [] ##模型列表:决策树的个数 predList = [] ##预测值列表 mse = [] ##均方差列表 allPredictions = [] ##预测值累加和列表 numTreesMax = 100 ##最大树数目 treeDepth = 12 ##每个树的深度 nAttr = 4 ##随机抽取的属性数目,建议值:回归问题1/3 ''' 随机森林思路: 对应每个决策树: 1.有放回的随机抽取和样本数据大小一样的数据集 2.无放回的随机抽取小于总属性个数的属性 ''' ''' 整个循环过程: 1.外层循环生成模型 2.在循环内部 a)有放回的在训练集上重新生成样本数据索引列表idxList b)根据idxList生成样本数据 c)无放回的随机抽取属性值索引列表attList d)根据idxList、attList生成用户训练的数据 e)进行训练 f)在测试集上执行类似步骤,并进行预测 g)测试集上产生的预测值加入列表待用 ''' for iTrees in range(numTreesMax): ##定义决策树 modelList.append(DecisionTreeRegressor(max_depth=treeDepth)) ##随机抽取的样本数据集和标签集 xList = [] yList = [] ##进行随机抽取时样本数据集的索引列表和属性索引列表 idxList = [] attList = [] ##构造随机样本数据集的索引列表 for idx in range(len(xTrain)): idxList.append(random.choice(range(len(xTrain)))) idxList.sort() ##记得排序 ##构造随机样本数据集 for idx in idxList: xList.append(xTrain[idx]) yList.append(yTrain[idx]) ##构造随机属性列表:dataWid-1,是因为最后一列是标签值 attList = random.sample(range(dataWid-1),nAttr) attList.sort() ##记得排序 ##构造测试数据集 xTrain1 = [] yTrain1 = [] for i in range(len(xList)): ##只读取抽取到的列 row = [xList[i][j] for j in attList] xTrain1.append(row) ##yList每行只有一个标签值 yTrain1.append(yList[i]) ##开始训练 modelList[-1].fit(xTrain1, yTrain1) ##获取预测值 ---测试集需要抽取相同的列进行预测 xTest1 = [] for i in range(len(xTest)): ##只读取抽取到的列 row = [xTest[i][j] for j in attList] xTest1.append(row) latestOutSamplePrediction = modelList[-1].predict(xTest1) ##预测值添加到列表 predList.append(list(latestOutSamplePrediction))
3)通过误差累加和寻找最佳树数目
筛选方法:不断累加模型在测试集上的误差值,直到这个和值基本保持不变了(即图像尾部区域直线),此时的模型个数是最优的模型个数。为了方便理解下面循环,用个图解释下:

(图1)
测试集经过在所有的模型上计算后,会形象一个二维的列表(如上图1所示)。每一行代表一个模型的预测结果。第一次循环就是n1的数据,第二次循环是n1+n2的值,第三次循环存储的是n1+n2+n3的值,依次类推,直到把模型列表循环完成。
这里有一点需要说明:因为是随机抽取样本数据和随机抽取属性,所以最优解时的模型的数目不是固定的。
##通过累积均方误差观察随机森林性能 for iModels in range(len(modelList)): prediction = [] ##此循环的目的:每个模型都是把前面的所有的模型的对应列的预测值加起来,形成一个新列表 ##说明:len(xTest) 每个模型的预测都会生成len(xTest)列的一行数据,这里len(xTest) 和len(yTest)是一样的 for iPred in range(len(xTest)): prediction.append(sum([predList[i][iPred] for i in range(iModels + 1)]) / (iModels + 1)) ##添加到列表 allPredictions.append(prediction) ##计算新的离差 errors = [(yTest[i] - prediction[i]) for i in range(len(yTest))] ##均方差:即离差的平方和的平均数 mse.append(sum([e * e for e in errors]) / len(yTest)) print('Minimum MSE') print(min(mse)) ##0.372633316412 print(mse.index(min(mse))) ## 不确定
4)绘图观察误差平方随模型数目变化的曲线
''' 第四步:绘图观察误差平方随模型数目变化的曲线 ''' ####模型个个数+1,绘图用:即模型列表中的从0开始的下标变成从1开始 的编号 nModels = [i + 1 for i in range(len(modelList))] ##绘图 plt.plot(nModels,mse) plt.axis('tight') plt.xlabel('Number of Trees in Ensemble') plt.ylabel('Mean Squared Error') plt.ylim((0.0, max(mse))) plt.show()
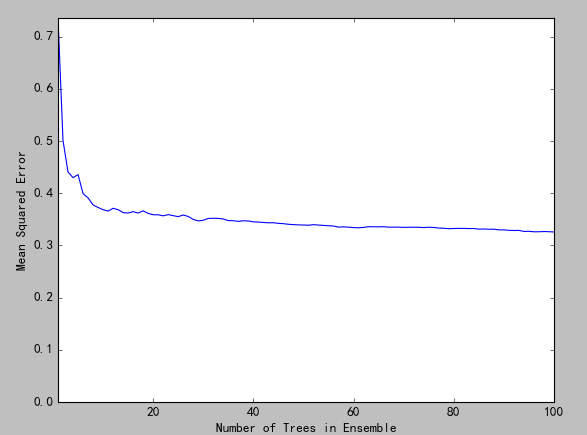
此次运行结果大概在90以后曲线区域平缓。
4.使用RandomForestRegressor函数实现上述过程
RandomForestRegressor是sklearn包中提供的实现随机森林算法的函数。下面还会用到另外一个函数:train_test_split。这两个函数的其他参数很容易理解,重点是说下参数:random_state,这个值在实际环境中取默认值None即可,但是在开发环境中需要指定一个任意固定值,是让内部的随机生成器生成的结果固定,方便研究其他变量引起的变化。
from sklearn.model_selection import train_test_split from sklearn import ensemble from sklearn.metrics import mean_squared_error import numpy as np import matplotlib.pyplot as plt import os ##运行脚本所在目录 base_dir=os.getcwd() data=np.loadtxt(base_dir+r"wine.txt",delimiter=";") dataLen = len(data) ##矩阵的长度:行数 dataWid = len(data[0]) ##矩阵的宽度:列数 ''' 第一步:把训练数据和标签数据分开 ''' xList = [] ##样本数据集 yList = [] ##标签集 ##划分数据:样本数据集和标签集 for i in range(dataLen): row = data[i] xList.append(row[0:dataWid-1]) yList.append(row[-1]) ##把列表转成数组 X = np.array(xList) Y = np.array(yList) ##取30%的数据作为测试集,70%的数据作为训练集 ##random_state设置成固定值是为了多次运行代码保持一致的结果,在开发阶段调整模型。真实环境设置默认值;None xTrain, xTest, yTrain, yTest = train_test_split(X, Y, test_size=0.30, random_state=0) ##树的数目:建议是尝试值100~500 nTreeList = range(1, 100, 1) ##均方误差 mse = [] for iTrees in nTreeList: depth =12 ##树最大深度,为了保持跟上面实验一致设为12,建议设置:None maxFeat = 4 ##最大属性值个数 ##定义模型 wineRFModel = ensemble.RandomForestRegressor(n_estimators=iTrees, max_depth=depth, max_features=maxFeat,random_state=0) ##开始训练 wineRFModel.fit(xTrain,yTrain) #计算测试集上的预测值 prediction = wineRFModel.predict(xTest) ##计算均方差并加入到列表 mse.append(mean_squared_error(yTest, prediction)) print('Minimum MSE') print(min(mse)) #0.378757382093 print(mse.index(min(mse))) #45 #绘制均方误差随模型数目的变化曲线 plt.plot(nTreeList, mse) plt.xlabel('Number of Trees in Ensemble') plt.ylabel('Mean Squared Error') plt.ylim([0.0, 1.1*max(mse)]) plt.show()
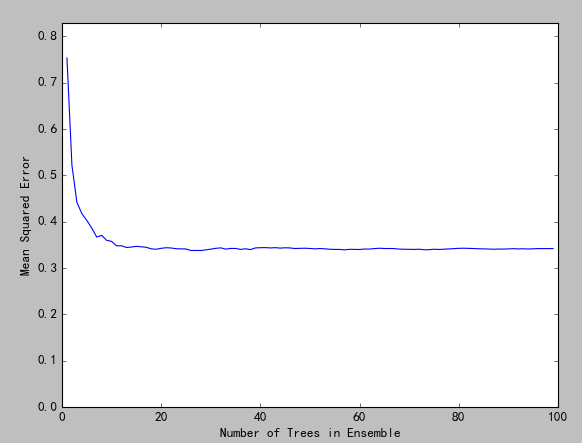
按照上面的设置每次生成的最佳模型数目都是27,但是random_state改成None后,最优解时的树的数目也不固定了。
5.总结
上述两种方法使用的数据一样,参数也尽可能保持一致,生成的结果就均方误差而言也基本一致。但是第一种方法最佳模型数目是99时所需要的时间也远远少于第二种方法模型数目是27的所需的时间。其时间比大概是1:4的样子,也就是说后者所需时间是前者所需时间的4倍,所以针对一些可以自己动手写代码的部分,并且不会产生太大偏差的时候,还是自己写代码比较好。这个例子告诉我们:并不是所有的现成类库的性能都优于自己写的代码性能。