一.字符串
1.字符串常见操作
拼接字符串
采用"+"号来拼接字符串,但是不能直接与其他数据类型拼接,需要str()来转换。
num1 = 11111
str1 = 'heiheihei'
print(str1+str(num1))
'''
输出
heiheihei11111
'''
计算字符串长度
len(str)
截取字符
str[start:end:step]
分割字符
'''
语法:
str.split(sep,maxsplit)
sep:指定用来分隔的字符,可以指定多个,默认为None,即所有的空字符,(包括空格,换行符'
',制表符
' '等
'''
str="hello boy<[www.doiido.com]>byebye"
print(str.split("[")[1])
'''
输出
www.doiido.com]>byebye
'''
print(str.split("[")[1].split("]")[0])
'''
输出
www.doiido.com
'''
合并字符
'''
str_new = string.join[iterable]
string : 字符串类型,用于指定合并时的分隔符
iterable : 可迭代类型,被合并的对象
'''
list = ['baidu','taobao','jindong','tianmao']
str = '===='.join(list)
print(str)
'''
输出 baidu====taobao====jindong====tianmao
'''
2.检索字符串
count()方法
用于检索一个字符在另一个字符串中出现的次数,返回出现的次数,如果没有返回0
str.count(sub[,start[,end]])
'''
sub:要检索的字符
'''
find()方法
用于检索一个字符是否在另一个字符串中存在,如果存在返回首次出现的索引,如果没有返回-1
str.find(sub[,start[,end]])
index()方法
用法和find()一样,不同点,如果要检索的字符不存在,那么会抛出异常。
startswith()方法
用来检索某个字符串是否以某个字符开头
str.startswith(prefix[,start[,end]])
endswith()方法
用来检索某个字符串是否以某个字符结尾
str.endswith(suffix[,start[,end]])
3.字符大小写转换
lower()方法
将某个字符全部转换为小写字符
str.lower()
upper()方法
将某个字符全部转换为大写字符
str.upper()
4.去除字符串左右两侧的特殊字符
strip()方法
用于去掉字符串左右两侧的空格和特殊字符
str.strip([chars])
'''
chars: 可选参数,指定要去除左右两边的字符,默认为空格,换行符'
'等
'''
lstrip()和rstrip()方法
用于指定去除左侧或者右侧的特殊字符,用法和strip一样
5.字符串的格式化
format()方法
str.format(args)
'''
str : 模板
args : 要传入的参数
'''
demo
# 1、按照默认顺序,不指定位置
print("{} {}".format("hello","world") )
# 输出 hello world
# 2、设置指定位置,可以多次使用
print("{0} {1} {0}".format("hello","or"))
# 输出 hello or hello
# 3、使用字典格式化
person = {"name":"lc-snail","age":18}
print("My name is {name} . I am {age} years old .".format(**person))
#输出 My name is lc-snail . I am 18 years old .
# 4、通过列表格式化
stu = ["lc-snail","linux","js","Python"]
print("My name is {0[0]} , I love {0[3]} !".format(stu))
#输出 My name is lc-snail , I love Python !
二.编码
1.常见编码
| 编码 | 支持语言 | 大小 |
|---|---|---|
| ASCII | 英文 | 1个字节 |
| Unicode | 所有语言 | 2个字节(生僻字4个) |
| UTF-8 | 所有语言 | 1-6个字节,英文字母1个字节,汉字3个字节,生僻字4-6个字节 |
总结一下现在计算机系统通用的字符编码工作方式:
在计算机内存中,统一使用Unicode编码,当需要保存到硬盘或者需要传输的时候,就转换为UTF-8编码。
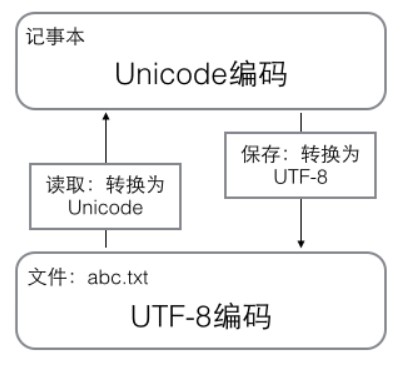
用记事本编辑的时候,从文件读取的UTF-8字符被转换为Unicode字符到内存里,编辑完成后,保存的时候再把Unicode转换为UTF-8保存到文件:
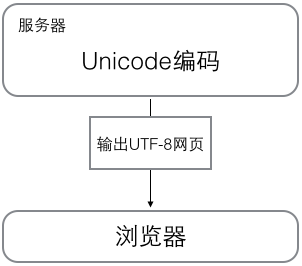
浏览网页的时候,服务器会把动态生成的Unicode内容转换为UTF-8再传输到浏览器:
2.python字符编码
Python的字符串类型是str,在内存中以Unicode表示,一个字符对应若干个字节。如果要在网络上传输,或者保存到磁盘上,就需要把str变为以字节为单位的bytes。
str 类型的数据类型带有双引号或者单引号;
'ABC'
bytes类型的数据用带b前缀的单引号或双引号表示;
b'ABC'
要注意区分'ABC'和b'ABC',前者和后者虽然内容显示得和前者一样,但bytes的每个字符都只占用一个字节。
encode()方法 —— 编码
encode()方法可以用指定编码方式把str转换成为bytes类型,也称为编码。
str.encode([encoding='编码方式'] [,errors='strict'])
'''
encoding: 用来指定编码方式,可以忽略encoding,直接写'编码方式'
errors:用来指定在遇到非法字符是的处理方式
'''
demo
str = '阿依希德鲁'
print(str.encode('utf-8'))
# utf-8 输出 b'xe9x98xbfxe4xbex9dxe5xb8x8cxe5xbexb7xe9xb2x81'
print(str.encode('gbk'))
# gbk 输出 b'xb0xa2xd2xc0xcfxa3xb5xc2xc2xb3'
反过来,如果我们从网络或磁盘上读取了字节流,那么读到的数据就是bytes。要把bytes变为str,就需要用decode()方法:
decode()方法 —— 解码
decode方发用于将二进制数据转换为字符串
str.decode([encoding='utf-8'] [,errors='strict'])
demo
bytA = b'xe9x98xbfxe4xbex9dxe5xb8x8cxe5xbexb7xe9xb2x81'
print(bytA.decode('utf-8')) #阿依希德鲁
bytB = b'xb0xa2xd2xc0xcfxa3xb5xc2xc2xb3'
print(bytB.decode('gbk')) #阿依希德