作业的要求来自于:https://edu.cnblogs.com/campus/gzcc/GZCC-16SE2/homework/2894
给定一篇新闻的链接newsUrl,获取该新闻的全部信息
标题、作者、发布单位、审核、来源
发布时间:转换成datetime类型
点击:
- newsUrl
- newsId(使用正则表达式re)
- clickUrl(str.format(newsId))
- requests.get(clickUrl)
- newClick(用字符串处理,或正则表达式)
- int()
整个过程包装成一个简单清晰的函数。
尝试去爬取一个你感兴趣的网页。
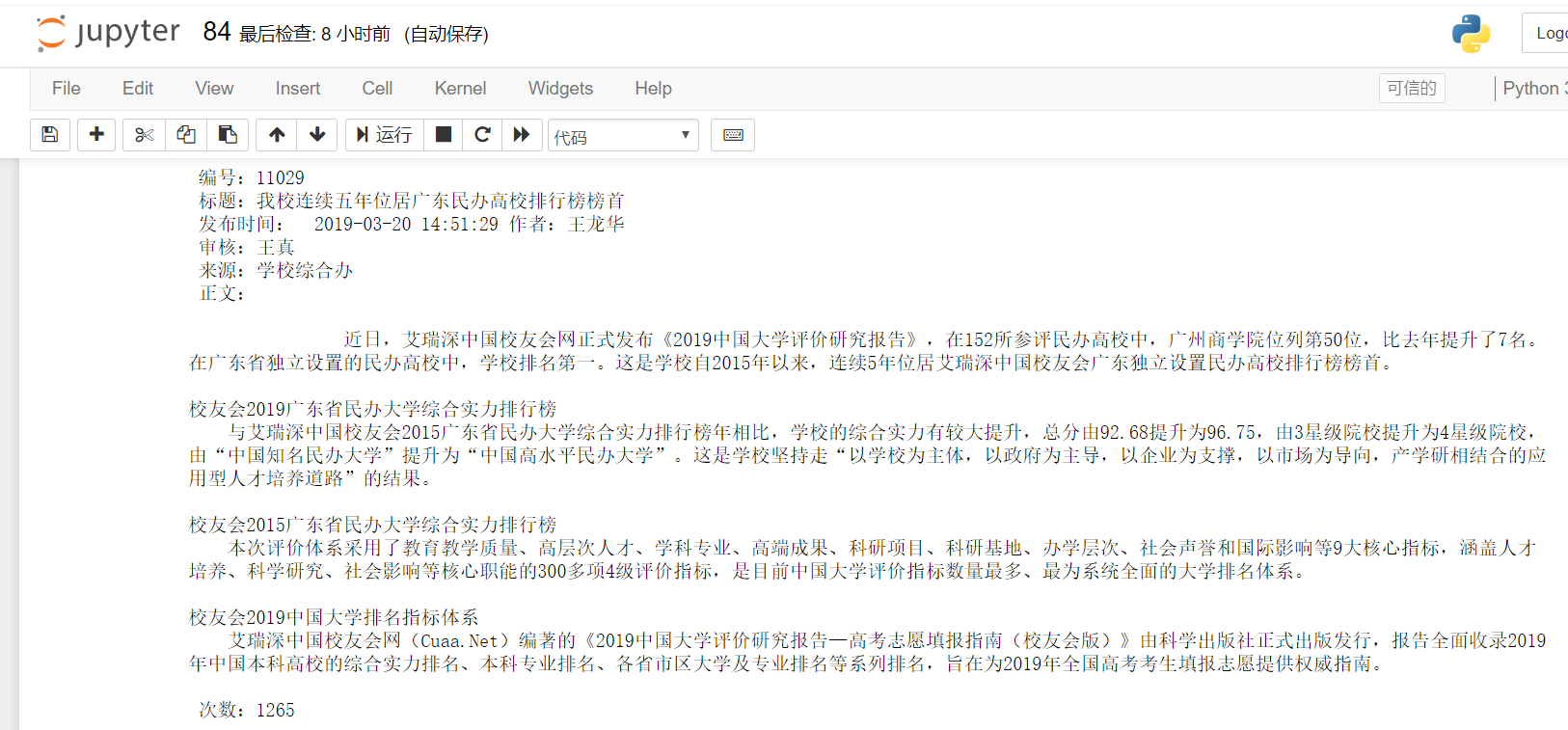
#获取一篇新闻的全部信息 import re import requests from bs4 import BeautifulSoup from datetime import datetime url="http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/11029.html" anews(url) #获取新闻编号 def newsnum(url): newsid=re.match('http://news.gzcc.cn/html/2019/xiaoyuanxinwen_0320/(.*).html',url).group(1) return newsid #发布时间:转换成datetime类型 def newstime(soup): newsdate=soup.select('.show-info')[0].text.split()[0].split(':')[1] newstime=soup.select('.show-info')[0].text.split()[1] time=newsdate+' '+newstime time=datetime.strptime(time,'%Y-%m-%d %H:%M:%S') return time #获取点击次数 def click(url): id=re.findall('(d{1,5})',url)[-1] clickUrl='http://oa.gzcc.cn/api.php?op=count&id={}&modelid=80'.format(id) res=requests.get(clickUrl) click=res.text.split('.html')[-1].lstrip("('").rstrip("');") return click def anews(url): res=requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') title=soup.select('.show-title')[0].text#标题 author=soup.select('.show-info')[0].text.split()[2]#作者 auditor=soup.select('.show-info')[0].text.split()[3]#审核 comefrom=soup.select('.show-info')[0].text.split()[4]#来源 detail=soup.select('.show-content')[0].text#内容 newsid=newsnum(url)#新闻编号id time=newstime(soup)#发布时间 clicktime=click(url)#点击次数 p=print(" 编号:"+newsid+' '" 标题:"+title+' '+' 发布时间: ',time,author+' ',auditor+' ',comefrom+' '" 正文:"+detail+" 次数:"+clicktime) return p