要求
- 对源文件(*.txt,*.cpp,*.h,*.cs,*.html,*.js,*.java,*.py,*.php等)统计字符数、单词数、行数、词频,统计结果以指定格式输出到默认文件中,以及其他扩展功能,并能够快速地处理多个文件。
- 使用性能测试工具进行分析,找到性能的瓶颈并改进
- 对代码进行质量分析,消除所有警告
- 设计10个测试样例用于测试,确保程序正常运行(例如:空文件,只包含一个词的文件,只有一行的文件,典型文件等等)
- 使用Github进行代码管理
- 撰写博客
需求分析
1. 统计文件中的字符数、单词数、行数、词组数;
2. 因要求为统计文件目录下所有文件的以上参数,所以第一需要完成的功能便是遍历文件目录下所有文件,并获得地址数据;
3. 获得文件地址后,采用遍历每一行的方式,计算行数和字符数,同时需选用一种数据结构来存储单词数量;
PSP表格
| 项目内容 | 预计用时(h) | 实际用时(h) |
| 需求分析 | 0.5 | 0.5 |
| 编程思路 | 1 | 1.5 |
| 实现遍历功能 | 1 | 1.5 |
| 获得字符数、行数 | 2 | 3 |
| 获得单词数 | 1.5 | 3 |
| 高频单词列举 | 2 | 1 |
| 性能测试 | 1.5 | 2 |
| 报告撰写 | 1 | 1 |
| 合计 | 10.5 |
13.5 |
编程思路
利用findfirst和findnext函数遍历文件,用参数dir存储当前文件地址,搜索到一个文件后,便对其字符,行,单词数开始计数,并将单词储存,单词采用一结构体链表储存。
| best | key | times | next |
| ... | |||
| ... | |||
| ... |
其中best为最后输出的单词形式,key为全部转化为小写字母的单词形式,times为该单词出现形式,next链表的指针,指向下一个节点。
为了寻找频率最高的10个词汇,维持一个大小为10的结构体数组,其中包括目前频率最高10个词的频率和单词。
对词组来说可以使用,和词汇类似的方法,将相邻的两个单词组成一个词组,存储起来,数据结构和计数方式都和单词大同小异。
测试过程
测试文件遍历功能时,采用给出的newsample文件夹目录下文件进行测试,输出文件名,文件名输出测试成功后输出文件地址,文件地址输出成功,基本就能确认文件遍历的正确性,能够从文件中读取数据;
在编写完成字符数统计后,同样采用newsample文件夹进行测试,每一次测试约花费3-5分钟,除了前几次将与或关系弄反外,字符统计很快完成,并且能做到和无差别。
行数的统计目前仍与标准值有在万分之一范围内的误差,尚不清楚是怎么引起的,在自己创建的小数据样本面前,行数的统计没有问题。
行数和字符数一起计算时用时在5~6分钟左右。
单词数的测试,在小样本时能很快得出,但由于链表的劣势,每一次查询该单词是否出现时,都将遍历一次链表,这导致了运算效率极低,设单词数为N,时间复杂度为O(N^2),导致newsample数据一直无法跑出结果,这也是待修正的地方之一。
由于这样的问题,联想到数据结构课程中,在遍历很慢时,并且KEY值拥有一个大小判断,可以使用二叉排序树的方法来存储单词,单词频率,这样在遍历时会节省大量的时间。
将数据结构换成了二叉排序树后,在小样本时同样能运行处正确的结果,但是文件夹内容过多之后,会出现内存不够用的情况,从而停止程序的运行。具体情况如下图所示
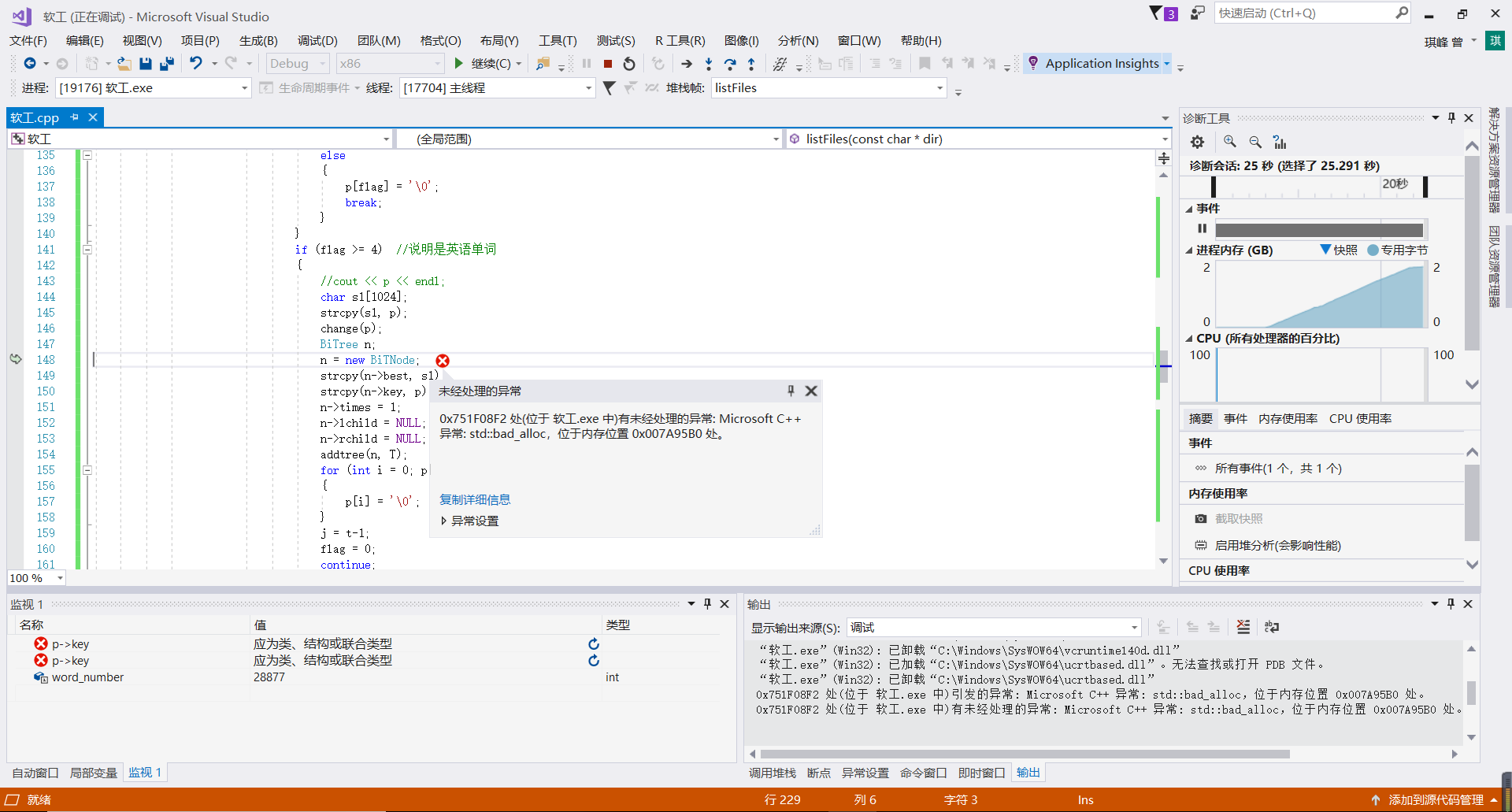 而在文件夹大小为6MB左右时,能够在10s左右得出结果,而在能手动查证的范围内,不出现错误。如下图所示
而在文件夹大小为6MB左右时,能够在10s左右得出结果,而在能手动查证的范围内,不出现错误。如下图所示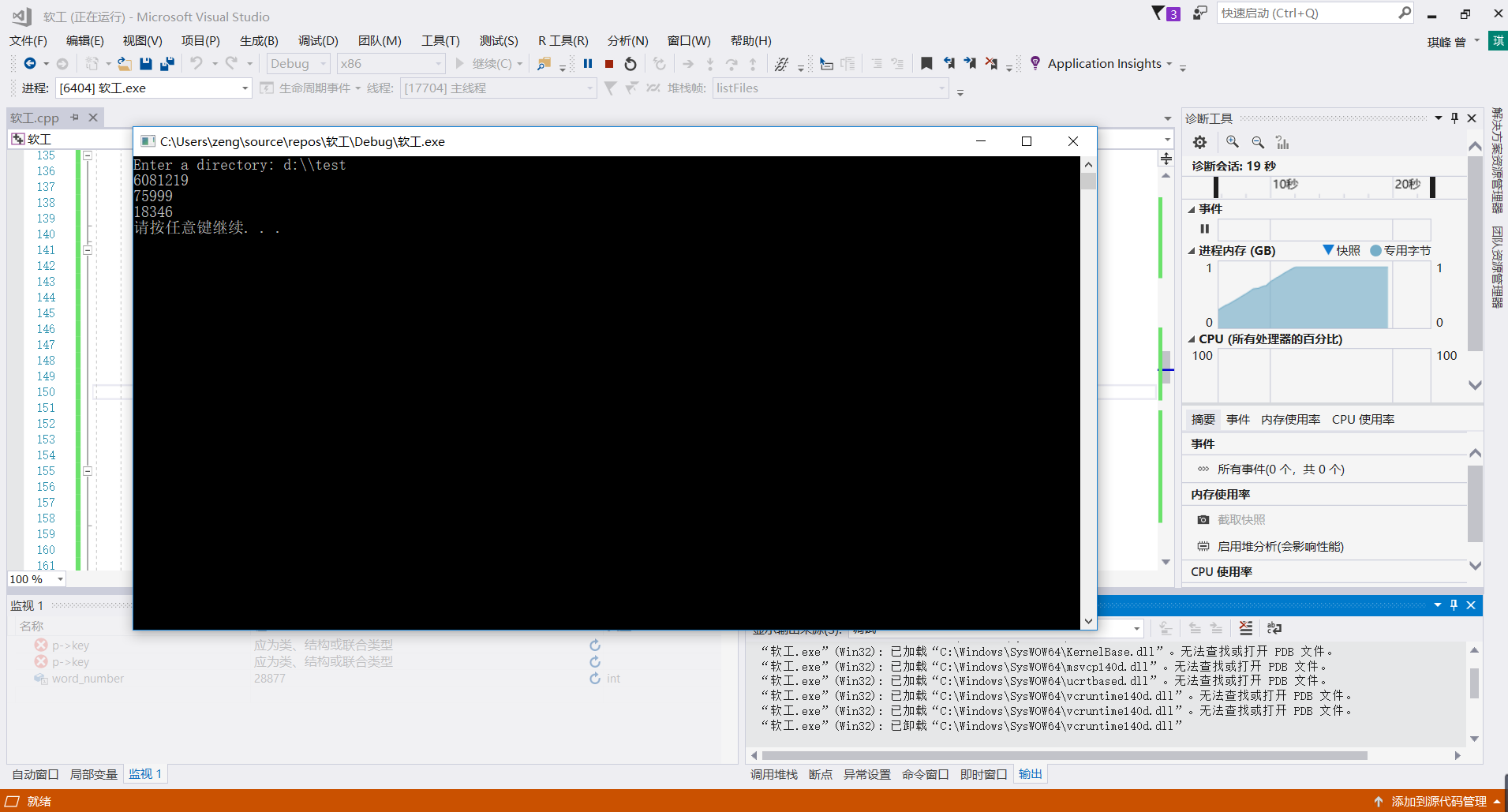 如果将数组的大小调小的话,能处理更多的数据,但是在不越界的情况下,仍然无法处理样例170M的数据。
如果将数组的大小调小的话,能处理更多的数据,但是在不越界的情况下,仍然无法处理样例170M的数据。
——————————————————————————————————————————————————————————————————————————————————分界线
在多次尝试修改数组长度为了完成newsample测试集无果后,我对采用的数据结构进行了分析,发现主要空间占用在每一个二叉树节点的字符数组,之前的代码中,我设置了两个字符数组分别储存字典顺序最高的值和统一转化的key值。分析发现,统一转化的key值可以在函数中直接完成,从而节省了一半的空间。修改后的程序能够完成newsample的统计,除了词组,单词数,和个别高频词外,和给出的Result只有个位数差距。
完成newsample(175MB)的文件统计需要10分钟左右的时间。
二叉树节点结构
| lchid | rchild | times | best |
收获的经验
对程序作需求分析,并明确选用的数据类型编程思路,比直接开始动手编程有更高的效率;
在需要处理的数据大小变化时,不同的算法有完全不同的效果;
团队协作有着重要的作用和意义。