OOP:(Object Oriented Programming )面向对象编程
重用性、灵活性和扩展性
高内聚、低耦合
面向过程编程与面向对象编程的区别:举例,自己做饭吃与去饭馆吃,去饭馆只需要知道吃什么菜就行,不需要知道怎么做的
AOP
AOP:(Aspect Oriented Programming)面向切面编程
优点:降低模块之间的耦合度、可植入性强、简单易用
缺点:性能低

Spring AOP 实现过程:
1.首先启动spring切面自动代理 <aop:aspectj-autoproxyproxy-target-class="true"></aop:aspectj-autoproxy>
2.配置一个javaBean(与切点相关的类) ,
<bean id="count" class="com.zr.utils.Calculate"></bean>
3.配置一个JavaBean(切面),<bean id="testAspect" class="com.zr.utils.TestAspect"></bean>
4. 配置切点和通知
<aop:config>
<aop:aspect id="test" ref="testAspect">
<aop:pointcut id="calculate" expression="execution(* com.zr.utils.*.*(..))" />
<aop:before method="methodBefore" pointcut-ref="calculate"/>
<aop:after method="methodAfter" pointcut-ref="calculate"/>
<aop:after-returning method="methodAfterRunning" pointcut-ref="calculate" returning="result"/>
<aop:after-throwing method="methodAfterThrowing" pointcut-ref="calculate" throwing="exception"/>
</aop:aspect>
</aop:config>
通过XML配置联想注解配置
Java多线程
(1) 继承Thread类,重写run()方法;启动线程:start()实例方法
(2) 实现Runnable接口创建线程,实现run()方法,创建Thread对象,然后启动线程,
代码:new Thread(t).start(); 其中t为实现Runnable接口的对象
ThreadLocal
ThreadLocal为变量在每一个线程中创建了一个副本,那么每个线程可以访问自己内部的副本变量。因此,消耗资源,但相对其它线程而言是独立、互斥的。
线程锁
1) Synchronized,无法中断一个正在等候获得锁的线程,synchronzied修饰的方法或者语句块在代码执行完之后锁自动释放。
2) ReentrantLock,拥有锁投票、定时锁等候和可中断锁等候的一些特性,但需要我们手动释放锁。
3) ReadWriteLock读写锁,提高性能
4) Condition可以为多个线程间建立不同的condition
线程池
1) newCachedThreadPool创建一个可缓存线程池,如果线程池长度超过处理需要,可灵活回收空闲线程,若无可回收,则新建线程。
2) newFixedThreadPool创建一个定长线程池,可控制线程最大并发数,超出的线程会在队列中等待。
3) newScheduledThreadPool创建一个定长线程池,支持定时及周期性任务执行。
4) newSingleThreadExecutor创建一个单线程化的线程池,它只会用唯一的工作线程来执行任务,保证所有任务按照指定顺序(FIFO,LIFO,优先级)执行。另外,如果这个线程异常结束,会有另一个取代它,保证顺利执行。
Servlet
1)Servlet通过调用init()方法进行初始化,init方法只调用一次,它在第一次创建Servlet时 被调用,在后续每次用户请求时不再调用。
2)Servlet调用service()方法来处理客户端的请求;service()方法由容器调用,service方法在适当的时候调用doGet、doPost、doPut、doDelete等方法。
3)Servlet通过调用destroy()方法终止(结束)。destroy()方法只会被调用一次,在Servlet生命结束时被调用。
最后,Servlet是由JVM的垃圾回收器进行垃圾回收的
Servlet生命周期主要表现在三个阶段,初始化阶段会调用init()方法,例如用户第一次访问servlet的时候,会调用init()方法,再次调用servlet方法时不会再次调用init()方法。
如果我们给servlet设置启动优先级,那么容器初始化时就会调用servlet的init()方法,无论哪种,init()方法始终只会被调用一次。当用户向web程序发送请求时,首先请求会达到public的service()方法,service()方法将servletRequest和servletResponse对象转换成httpServletRequest对象和httpServletResponse对象,并且调用受保护的service()方法。再由受保护的service()方法根据用户的请求方式来决定转交给哪个方法进行处理,例如请求会转交doGet方法处理。
JSP
JSP(Java Server Pages) ,中文名叫Java服务器页面,其根本是一个简化Servler设计。JSP是一种动态页面技术,它的主要目的是将表示逻辑从Servlet中分离出来。
Servlet和jsp的区别:
Jsp有9大内置对象,内置对象和httpServletRequest、httpServletResponse、httpServlet对象有关系,Servlet没有内置对象。Jsp通常用于视图展现层,Servlet通常用于业务逻辑的控制,jsp的本质就是Servlet,JVM只能识别Java类,而不能识别jsp的代码,所以web容器会将jsp转换成Java类,再由Java虚拟机编译成能识别的class类。
Jsp九大内置对象:
request--------------请求对象---------------作用域Request
response------------响应对象---------------作用域Page
pageContext-------页面上下文对象------作用域Page
session--------------会话对象---------------作用域Session
application---------应用程序对象---------作用域Application
out-------------------输出对象---------------作用域Page
config----------------配置对象---------------作用域Page
page-----------------页面对象----------------作用域Page
exception-----------例外对象----------------作用域Page
request对象封装了客户端的所有请求信息,所以可以通过request对象获得所有的请求信息,例如获取客户端的请求参数、IP信息等。获得客户端的信息后需要响应客户,而响应的信息都封装在request对象里。
session是指客户端与服务器端的一次会话,从客户端连接到服务器开始,到客户端断开连接结束。因为http请求时无状态的,所以session通常用于追踪客户的会话信息。
application对象实现了用户间数据的共享,可存放全局变量,它的生命周期和容器保持一致,它开始于服务器的启动,直到服务器的关闭。
out对象是jspWriter类的实例,是向客户端输出内容常用的对象,它和Servlet里面的printWriter对象有相同的功能。
exception对象是一个例外对象,当一个页面在运行过程中发生了异常,就产生这个对象。如果一个jsp页面要应用此对象,就必须把isErrorPage设置为true,否则无法编译。它实际上是java.lang.Throwable的对象。
Spring
优点:
1) 方便解耦,简化开发
2) AOP编程的支持
3) 声明式事务的支持
4) 方便集成各种优秀的框架
功能:
(1) Spring中的事务处理
(2) IOC容器在web容器中的启动
(3) Spring JDBC
(4) Spring MVC
(5) Spring AOP获取Proxy
(6) Spring声明式事务
(7) Spring AOP中对拦截器调用的实现
(8) Spring驱动Hibernate的实现
(9) Spring Acegi框架鉴权的实现
声明式事务
声明式事务的解释:
声明式事务管理建立在AOP之上的。其本质是对方法前后进行拦截,然后在目标方法之前创建或者加入一个事务,在执行完目标方法之后根据执行情况或者回滚事务。在执行完目标方法之后根据执行情况提交或者回滚,这样就不需要在业务逻辑代码中参杂事务管理的代码,只需在配置文件中做相关的事务规则声明(或通过基于@Transactional注解的方式),便可以将事务规则应用到业务逻辑中。
优缺点:
显然声明式事务管理要优于编程式事务管理,这正是spring倡导的非侵入式的开发方式。声明式事务管理使业务代码不受污染,一个普通的POJO对象,只要加上注释就可以获得完全的事务支持。和编程式事务相比,声明式事务唯一不足的地方是:最细粒度只能作用到方法级别,无法做到像编程式事务那样可以作用到代码块级别。但是即便有这样的需求,也存在很多变通的方法,比如,可以将需要进行事务管理的代码块独立为方法等等。
实现方式:
声明式事务管理也有两种常用的方式:一种是基于tx和aop名字空间的xml配置文件,另一种就是基于@Transactional注解。显然基于注解的方式更简单易用。
事务的传播行为:
1)PROPAGATION_REQUIRED如果当前没有事务,就新建一个事务,如果已经存在一个事务中,加入到这个事务中。这是最常见的选择。
2)PROPAGATION_SUPPORTS支持当前事务,如果当前没有事务,就以非事务方式执行。 3)PROPAGATION_MANDATORY使用当前的事务,如果当前没有事务,就抛出异常
4)PROPAGATION_REQUIRES_NEW新建事务,如果当前存在事务,把当前事务挂起
5)PROPAGATION_NOT_SUPPORTED以非事务方式执行操作,如果当前存在事务,就把当前事务挂起
6)PROPAGATION_NEVER以非事务方式执行,如果当前存在事务,则抛出异常
7)PROPAGATION_NESTED如果当前存在事务,则在嵌套事务内执行。如果当前没有事务,则执行与PROPAGATION_REQUIRED类似的操作。
IOC
IOC:(Inversion of Control)控制反转,减少程序的耦合性,spring框架的核心,缺点是耗性能。
控制反转分两种类型:1)依赖注入(Dependency Injection,简称DI)
2)依赖查找
依赖注入:就是由IOC容器在运行期间,动态地将某种依赖关系注入到对象之中
创建的JavaBean默认是单例(减少内存的消耗)
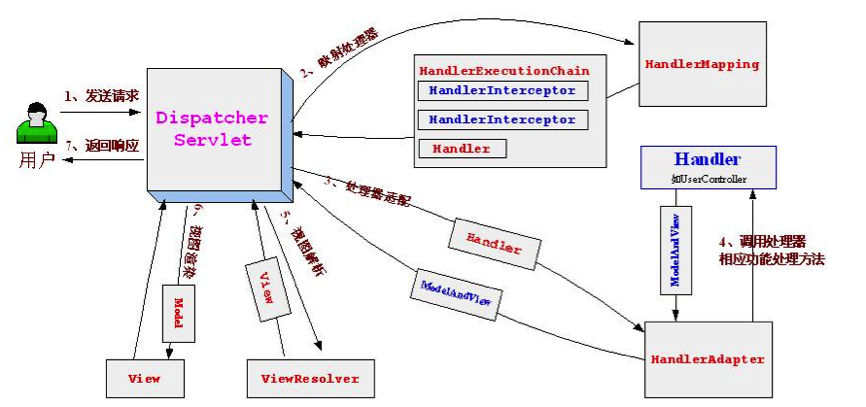
SpringMVC的工作原理、流程
1) 客户端发送http请求,web应用服务器接收请求,如果配置DispatcherServlet的映射路径(在web.xml中配置),web容器将该请求转交给DispatcherServlet处理;
2) DispatcherServlet根据请求的信息及HandlerMapping的配置找到处理该请求的controller;
3) Controller完成业务逻辑处理后,返回一个ModelAndView给DispatcherServlet;
4) DispatcherServlet借由ViewResolver完成ModelAndView中逻辑视图名到真实视图对象View的解析工作(ModelAndView返回的视图只是逻辑名,需要借助Spring提供的视图解析器ViewResoler在web应用中查找View对象);
5) DispatcherServlet根据ModelAndView中的数据模型对View对象进行视图渲染,最终客户端得到的响应消息可能是一个HTML页面,也可能是一个xml或json数据,甚至是一张图片或一个PDF文档等不同的媒体形式

Struts2
Struts2执行过程

result的type属性
1) dispatcher(默认)
请求转发,底层调用RequestDispatcher的forward()或include()方法,dispatcher是type属性的默认值,通常用于转发一个JSP。location指定JSP的位置,parse如果为false表示location的值不会当作OGNL解析,默认为true。
2) redirect:
重定向,新页面无法显示Action中的数据,因为底层调用response.sendRedirect(“”)方法,无法共享请求范围内的数据,参数与dispatcher用法相同。
3) redirect-action
重定向到另一个Action,参数与chain用法相同,允许将原Action中的属性指定新名称带入新Action中,可以在Result标签中添加<param name=”b”>${a}</param>,这表示原Action中的变量a的值被转给b,下一个Action可以在栈中使用b来操作,注意如果值是中文,需要做一些编码处理,因为Tomcat默认是不支持URL直接传递中文的。
4) velocity:
使用velocity模板输出结果,location指定模板的位置(*.vm),parse如果为false,location不被OGNL解析,默认为true。
5) xslt:
使用XSLT结果转换为XML输出,location指定*.xslt文件的位置,parse如果为false,location不被OGNL解析,默认为true。matchingPattern指定想要的元素模式,excludePattern指定拒绝的元素模式,支持正则表达式,默认为接受所有元素。
6) chain:
将action的带着原来的状态请求转发到新的action,两个action共享一个ActionContext,actionName指定转向的新的Action的名字。Method指定转向哪个方法,namespace指定新的名称空间,不写表示与原Action在相同的名称空间;skipActions指定一个使用,连接的Action的name组成的集合,一般不建议使用这种类型的结果。
7) stream:
直接向相应中发送原始数据,通常在用户下载时使用,contentType指定流的类型,默认为text/plain,contentLength以byte计算流的长度,contentDisposition指定文件的位置,通常filename=”文件的位置”,input指定InputStream的名字,例如:imageStream,bufferSize指定缓冲区大小,默认为1024字节。
8) plaintext:
以原始文本显示JSP或者HTML,location指定文件的位置,charSet指定字符集。
Struts2工作流程:
客户请求URL——>filter(如果路径匹配)——>action(如果匹配action标签中的name,就会去到class对应的控制层,且找到对应的方法,进行处理相应的逻辑业务,然后返回相应的值)——>根据返回值去匹配result标签的name(如果匹配)——>进行相应的操作,例如页面转发等
Struts2拦截器有三种:
Interceptor
AbstractInterceptor
MethodFilterInterception
拦截器的配置
<!-- 配置拦截器 -->
<interceptors>
<!-- 拦截器有三种 -->
<interceptor name="loginInterceptor" class="cn.zr.struts2.interceptor.LoginInterceptor"/>
<interceptor name="twoInterceptor" class="cn.zr.struts2.interceptor.TwoInterceptor"/>
<interceptor name="threeInterceptor" class="cn.zr.struts2.interceptor.ThreeInterceptor"/>
<interceptor-stack name="testStack">
<interceptor-ref name="defaultStack" />
<interceptor-ref name="loginInterceptor"/>
<interceptor-ref name="threeInterceptor"/>
<interceptor-ref name="twoInterceptor">
<param name="excludeMethods">thing</param>
<param name="includeMethods">update</param>
</interceptor-ref>
</interceptor-stack>
</interceptors>
<!-- 换掉默认拦截器 -->
<default-interceptor-ref name="testStack"/>
Struts2修改配置文件名称
<filter>
<filter-name>struts2</filter-name>
<filter-class>org.apache.struts2.dispatcher.ng.filter.StrutsPrepareAndExecuteFilter</filter-class>
<init-param>
<param-name>config</param-name>
<param-value>struts-default.xml,struts-plugin.xml,struts2.xml</param-value>
</init-param>
</filter>
Struts2每个节点的意义
节点:struts(Struts2中组件化的方式)
节点:package(包节点)——>name(可随意命名,但必须唯一)——>namespace(package命名空间,该命名空间影响到URL的地址)——>extends(继承的父package名称)
节点:interceptors
interceptor(拦截器)——>name(拦截器的名称)——>拦截器类路径
interceptor-stack(拦截器的栈)——>name(栈的名称)
interceptor-ref(关联拦截器)——>name(被关联拦截器的名称)
default-interception-ref(默认关联的拦截器)——>name(取代默认拦截器的拦截器名称)
节点:global-results(全局results配置)
节点:action——>name(action的名称,该命名与URL访问地址相关)——>class(对应的类的路径)——>method(调用Action中的方法名)
节点:result——>name(result名称和Action中返回的值相同)——>type(result类型)
Struts2校验(略)
Springmvc与Struts2对比
1) Struts2是类级别的拦截,一个类对应一个request上下文,springmvc是方法级别的拦截,一个方法对应一个request上下文
2) 拦截器实现机制上,Struts2有以自己的interceptor机制,springmvc用的是独立的AOP方式,这样导致Struts2的配置文件量还是比springMVC大
3) SpringMVC的入口是servlet,而Struts2是filter
4) 从项目的管理和安全上比较,SpringMVC比Struts2要高
5) SpringMVC开发效率和性能高于Struts2
Mybatis
Mybatis是对dao层操作的框架,半自动
Mybatis缓存机制
一级缓存是Sqlsession级别的缓存。在操作数据库时需要构造sqlSession对象,在对象中有一个(内存区域)数据结构(HashMap)用于存储缓存数据。不同的sqlSession之间的缓存数据区域(HashMap)是互相不影响的。
一级缓存的作用域是同一个SqlSession,在同一个sqlSession中两次执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。当一个sqlSession结束后该sqlSession中的一级缓存也就不存在了。Mybatis默认开启一级缓存
二级缓存是mapper级别的缓存,多个sqlSession去操作同一个Mapper的sql语句,多个sqlSession去操作数据库得到数据会存在二级缓存区域,多个sqlSession可以共用二级缓存,二级缓存是跨SqlSession的。
二级缓存是多个SqlSession共享的,其作用域是mapper的同一个namespace,不同的sqlSession两次执行相同namespace下的sql语句且向sql中传递参数也相同即最终执行相同的sql语句,第一次执行完毕会将数据库中查询的数据写到缓存(内存),第二次会从缓存中获取数据将不再从数据库查询,从而提高查询效率。Mybatis默认没有开启二级缓存需要在setting全局参数中配置开启二级缓存。二级缓存在进行多表操作时,会出现脏读。
Hibernate
一.Hibernate是对JDBC进一步封装
原来没有使用hibernate做持久层开发时,存在很多冗余,如:各种JDBC语句,connection的管理,所以出现了hibernate把JDBC封装了一下,我们不用操作数据,直接操作它就可以。
二.从分层角度出发
经典的三层架构:表示层,业务层,还有持久层。Hibernate也是持久层的框架,而且持久层的框架还有很多。
三.Hibernate是一个开源的ORM(对象关系映射)框架
ORM,即Object-Relation Mapping,它的作用就是在关系型数据库和对象之间做了一个映射。从对象(object)映射到关系(Relation),再从关系映射到对象。这样,我们在操作数据库的时候,不需要再去和复杂SQL打交道,只要像操作对象一样操作它就可以了(把关系数据库的字段在内存中映射成对象的属性)。
Hibernate的核心
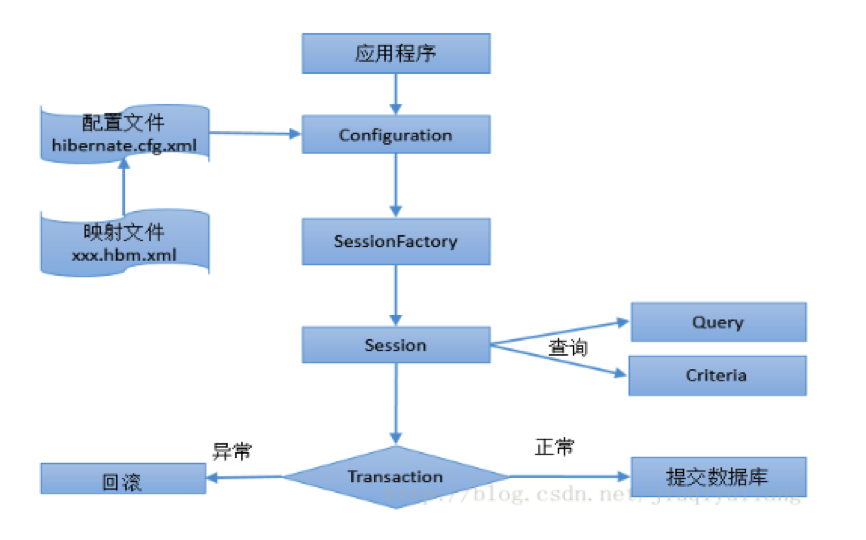
从上图中,我们可以看出hibernate六大核心接口,两个主要配置文件,以及他们直接的关系。Hibernate的所有内容都在这了。那我们从上而下简单的认识下。
- Configuration接口:负责配置并启动hibernate
- SessionFactory接口:负责初始化hibernate
- Session接口:负责持久化对象的CRUD操作
- Transaction接口:负责事务
- Query接口和criteria接口:负责执行各种数据库查询
注意:Configuration实例是一个启动期间的对象,一旦sessionFactory创建完成它就被丢弃了。
Hibernate的优缺点:
优点:
- 更加对象化,以对象化的思维操作数据库,我们的只需要操作对象就可以了,开发更加对象化。
- 可移植性强,因为hibernate做了持久层的封装,你就不知道数据库,你写的所有代码都具有可复用性。
- Hibernate是一个没有侵入式的框架,没有侵入性的框架称为轻量级框架。对比Struts2的Action和ActionForm,都需要继承,离不开Struts2.hibernate不需要继承任何类,不需要实现任何接口。这样的对象叫POJO对象。
- Hibernate代码测试方便。
- 提高效率,提高生产力。
缺点:
- 使用数据库特性的语句,将很难调优
- 对大批量数据更新存在问题
- 系统中存在大量的攻击查询功能
映射文件说明:
类层次:class
l 主键:id
l 基本类型:property
l 实体引用类型:many-to-one | one-to-one
l 集合:set | list | map | array
- one-to-many
- many-to-many
l 子类:subclass | joined-subclass
l 其它:component | any 等
注意一下主键生成器
站在持久化的角度,hibernate把对象分为4种状态:持久化状态,临时状态,游离状态、删除状态

Solr
Solr是一个独立的企业级搜索应用服务器,它对外提供类似于web-service的API接口。用户可以通过http请求,向搜索引擎服务器提交一定格式的XML格式,生成索引;也可以通过http get操作提出查找请求,并得到xml格式返回结果。
Solr与Lucene并不是竞争对立关系,恰恰相反solr依存于Lucene,因为solr底层的核心技术是使用Lucene来实现的,solr和Lucene的本质区别有以下三点:搜索服务器,企业级和管理。Lucene本质是搜索库,不是独立的应用程序,而solr是。Lucene专注于搜索底层的建设,而solr专注于企业应用。Lucene不负责支撑搜索服务所必须的管理,而solr负责。所以说,一句话概括solr:solr是Lucene面向企业搜索应用的扩展。
Solr搭建:
- 其官网下载solr
- 找到solr.war后进行解压,然后放在ROOT文件夹中
- 把相关的配置文件拷到home文件夹下
- 使用Tomcat将ROOT目录下的程序跑起来
注意:具体搭建可参考http://www.cnblogs.com/lantu1989/p/6743455.html
- 可配置Schema.xml(添加Field)来创建索引
- 配置solrconfig.xml,配置文件的主要内容有:使用的lib配置,包含依赖的jar和solr的一些插件;组件信息配置;索引配置和查询配置。
- Solr可加入中文分词器(中文分词器默认没有开启,需要配置)。目前可用的分词器有smartcn,IK,Jeasy,庖丁。
注意:要在solrconfig.xml中加一句应用analysis-extras的配置,这样我们自己加入的分词器才会引到solr中。
- 分词器的安装:下载相应jar包,在schema.xml中添加相应的配置
- solr功能应用
² SolrInputDocument对象,主要操作是给文档添加字段和值
² 查询通配符”*”表示匹配任意字符;”?”表示匹配出现的位置
² 可进行权重查询,可以在代码里手动实现,也可以在配置文件中实现
² 可进行分组查询和分组统计
² 可实现高亮显示
数据库相关
常见函数:
1)数值常用函数
ceil(n) ---大于或等于数值n的最小整数
floor(n) ---小于等于数值n的最大整数
mod(n) ---m除以n的余数,若n=0,则返回m
power(m,n) ---m的n次方
round(n,m) ---将n四舍五入,保留小数点后m位
sign(n) ---若n=0,则返回0,否则,n>0,则返回1,n<0,则返回-1
sqrt(n) ---n的平方根
2)常用字符函数
Initcap(char) ---把每个字符串的第一个字符换成大写
lower(char) ---整个字符串换成小写
replace(char,str1,str2) ---字符串中所有str1换成str2
substr(char,m,n) ---取出从m字符开始的n个字符的子字符串
length(char) ---求字符串的长度
3)日期函数
sysdate ---当前日期和时间
last_day ---本月最后一天
to_date ---将字符串转化为ORACLE中的一个日期
4)分析函数
avg ---求平均值
count ---统计数目
max ---求最大值
min ---求最小值
sum ---求和
索引有哪几种?索引有几大准则?哪些字段是不能使用索引的?
索引分为:普通索引,唯一索引,全文索引,单列索引,组索引等,常用的,有普通索引,唯一索引,创建唯一索引时,最好时根据表中的主键进行创建索引,这样可以保证索引以及主键的唯一性;
不能使用索引的字段有,当我们的字段涉及到人的姓名,性别时,是不能使用索引,因为汉字是不能建立索引的。其次,性别,因为只有男女之分,所以创建出的索引有重复
关于建立索引的几个准则:
1、合理的建立索引能够加速数据读取效率,不合理的建立索引反而会拖慢数据库的响应速度。
2、索引越多,更新数据的速度越慢。
3、尽量在采用MyIsam作为引擎的时候使用索引(因为MySQL以BTree存储索引),而不是InnoDB。但MyISAM不支持Transcation。
4、当你的程序和数据库结构/SQL语句已经优化到无法优化的程度,而程序瓶颈并不能顺利解决,那就是应该考虑使用诸如memcached这样的分布式缓存系统的时候了。
5、习惯和强迫自己用EXPLAIN来分析你SQL语句的性能。
游标
优点:
游标允许应用程序对查询语句select 返回的行结果集中每一行进行相同或不同的操作,而不是一次对整个结果集进行同一种操作;它还提供对基于游标位置而对表中数据进行删除或更新的能力。
缺点:
处理大数据量时,效率低下,占用内存大
一般来说,能使用其他方式处理数据时,最好不要使用游标,除非是当你使用while循环,子查询,临时表,表变量,自建函数或其他方式都无法处理某种操作的时候,再考虑使用游标
存储过程与函数的区别:
本质上没区别。只是函数有如:只能返回一个变量的限制。而存储过程可以返回多个。而函数是可以嵌入在sql中使用的,可以在select中调用,而存储过程不行。执行的本质都一样。
函数限制比较多,比如不能用临时表,只能用表变量.还有一些函数都不可用等等.而存储过程的限制相对就比较少
1.一般来说,存储过程实现的功能要复杂一点,而函数的实现的功能针对性比较强。
2.对于存储过程来说可以返回参数,而函数只能返回值或者表对象。
3.存储过程一般是作为一个独立的部分来执行(EXEC执行),而函数可以作为查询语句
的一个部分来调用(SELECT调用),由于函数可以返回一个表对象,因此它可以在查
询语句中位于FROM关键字的后面。
4.当存储过程和函数被执行的时候,SQL Manager会到procedure cache中去取相应的
查询语句,如果在procedure cache里没有相应的查询语句,SQL Manager就会对存
储过程和函数进行编译。
数据库的优化:
1) 增加数据库连接的最大量
2) 修改数据库缓存大小
3) 分表、表分区
4) 结合第三方缓存(MySQL5.6以后可以集成Memcached)
5) 数据库主从复制+读写分离(amoeba)
6) 数据库集群
7) 尽量不要出现select*语句,用到哪个字段就写哪个字段
8) 尽量避免在列上做运算,会导致索引失效(前提是这个字段做了索引)
9) 使用join时,应该用小的结果驱动大的结果
10) 注意like模糊查询的使用,避免使用%%,可以使用后面带%,双%不走索引的。
注意:like容易造成全盘扫描,也会导致索引失效
11) 使用批量插入节省交互(当如果使用存储过程来处理批量的sql各种逻辑是更好的选择)
例如:
insert into student(id,name,age) values(100,’lf’,26),(101,’zlf’,25)
12) 不要使用rand函数获取多条随机记录
13) 避免使用null
14) 不要使用count(id),使用count(*)
15) 不要做无谓的排序操作,而应该使用索引完成排序(尽量使用创建索引的字段来排序)
Oracle与MySQL的区别
1.Oracle是用来存储数据量大的数据库,MySQL是用来存储数据量处于中,小的数据库;
2.Oracle在执行数据的增、删、改时,需要手动提交事务。MySQL则是自动提交事务;
3.Oracle在某些字段属性上与MySQL不同,例如:Oracle中有NUMBER(),而MySQL中则是用INT来修饰数字的字段属性;
4.Oracle在存储字符串时,最大可存储4000个字节;MySQL则比较小;
5.Oracle在分页上,使用ROWNUM结合使用"<"或">"来实现分页,MySQL则是通过一个limit关键字就可以实现;
Nginx+Tomcat实现集群
1)安装Nginx
2)配置多个Tomcat,在server.xml中修改端口(端口不出现冲突即可)
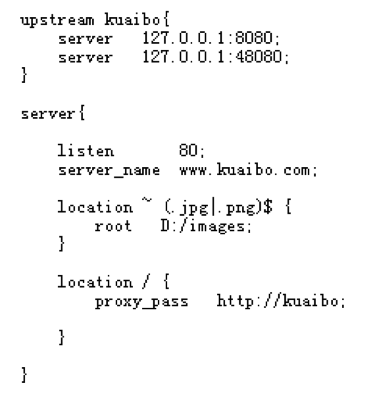
3)在nginx.conf文件中配置负载均衡池,具体配置如下:

Nginx+Tomcat集群+session共享
为什么要实现共享,如果你的网站是存放在一个机器上,那么是不存在这个问题的,因为会话数据就在这台机器,但是如果你使用了负载均衡把请求分发到不同的机器呢?这个时候会话id在客户端是没有问题的,但是如果用户的两次请求到了两台不同的机器,而它的session数据可能存在其中一台机器,这个时候就会出现取不到session数据的情况,于是session的共享就成了一个问题。
1)安装Nginx
2)配置多个Tomcat,在server.xml中修改端口(端口不出现冲突即可)
3)在nginx.conf文件中配置负载均衡池,具体配置如下:
4)在Tomcat的server.xml文件中找到<Engine>或<Host>标签,然后添加集群的子标签(<Cluster>),具体配置可到官网查看
5)在程序的web.xml中添加<distributable/>表签
6)启动Tomcat和Nginx即可实现
基于Nginx动静分离
(1) 安装Nginx
(2) 在Nginx配置文件中配置拦截路径(例如拦截所有的.png和.jpg图片的后缀,或者是视频的后缀),如果是这些后缀就到服务器指定的目录下找,便可实现动静分离
动静分离可提高性能,减少并发访问量。
Webservice
Web service就是一个应用程序,它向外界暴露出一个能够通过Web进行调用的API。其中,简单对象访问协议(SOAP)提供了标准的RPC方法来调用Web service。
Webservice的实现方式:
1) Axis2
Axis是Apache下一个开源的webservice开发组件,出现比较早,也比较成熟。
2) Apche CXF
CXF 开发webservice比较方便和简单,它和spring的集成可以说非常好
3) JDK开发webservice
4) xfire
基于JDK实现过程:
1) 使用@webservice注解标注一个Java类,使用@WebMethod 注解标注Java类中定义的方法
2) 使用Endpoint(终端)类发布webservice
代码如下:

基于spring框架集成的webservice
1) 在配置文件中添加JavaBean,告诉暴露接口的地址(IP)和端口号

2) 创建一个接口和实现类,并添加@service注解,交给spring管理
3) 使用@webservice注解标注实现类,使用@WebMethod 注解标注实现类中定义的方法
代码如下:

HTTP请求
1) 打开和URL之间的连接
2) 设置通用的请求属性
3) 建立实际的连接
4) 将输入流转化成BufferedReader,再转化成stringBuffer类型
5) 关闭相应的资源
C3P0连接池
JDBC与c3p0对比:
普通的jdbc数据连接库连接使用DriverManager来获取,每次向数据库建立连接的时候都要将Connection加载到内存中。需要数据库连接的时候,就向数据库要求一个,执行完成后再断开连接。这样的方式会消耗大量的资源和时间。数据库的连接资源并没有得到,很好的重复利用。
数据库连接池的基本思想就是为数据库连接建立一个“缓冲池”。预先在缓冲池中放入一定数量的连接,当需要建立数据库连接时,只需从“缓冲池”中取出一个,使用完毕之后再放回去。
数据库连接池技术的优点:
(1) 资源重用:由于数据库连接得以重用,避免了频繁创建,释放连接引起的大量性能开销。在减少系统消耗的基础上,另一方面也增加了系统运行环境的平稳性。
(2) 更快的系统反应速度:数据库连接池在初始化过程中,往往已经创建了若干数据库连接置于连接池备用。此时连接的初始化工作均已完成。对于业务请求处理而言,直接利用现有可用连接避免了数据库连接初始化和释放过程的时间开销,从而减少了系统的响应时间。
(3) 统一的连接管理,避免数据库连接泄露在较为完善的数据库连接池实现中,客根据预先的占用超时设定,强制回收被占用连接,从而避免了常规数据库连接操作中可能出现的资源泄露。
Spring集成Quartz定时器
基于注解方式的实现

1) 导入相关的jar包
2) 添加@Component注解,交给spring去管理
3) 添加@Configuration注解,声明当前类是一个配置类,相当于一个Spring配置的xml文件。
4) 添加@EnableAsync注解,开启异步方法的支持
5) 添加@EnableScheduling注解,开启计划任务的支持
6) 在方法中添加@Scheduled注解,进行定时,并设置相应的时间参数
信息与邮件的发送
(1) 到第三方平台去注册账号(如阿里大于、sendCould等平台)
(2) 可创建模板发送
(3) 获取相关参数(如API_KEY、SECRET等)
(4) 下载相关的SKD
(5) 按照开发文档配置一下即可
itext生成PDF报表
itext.jar
1) 创建document对象
2) 建立PDFWriter(书写器)à(输出的路径)
4)设置文档相关的参数(如文档页面的大小、背景色、以及页面横向/纵向等属性、边距)
5)设定文档属性(设定文档的标题、主题、作者、关键字、装订方式、创建者、生产者、创建日期等属性)
6) 通过书写器来设置安全保护性(设定文档的用户口令、只读、可打印等属性)
7) 打开文档document.open()
8)添加文档内容:
a)文本块(Chunk)
b)短语(Phrase)
c)段落(paragraph)
d) 表格(Table)
e) 图像( Graphic)
9)关闭文档。document.close();
10)另外,要甚至中文字体(否则无法显示中文字体),别忘了分页处理
具体实现可参考:http://www.cnblogs.com/lantu1989/p/6691772.html
生成exel报表(基于Apache的框架实现的)
1) 创建HSSFWorkbook对象;
2) 创建一个表HSSFSheet
3) 创建行HSSFRow
4) 创建单元格(Cell)HSSFCell
5) 写出去
代码如下:
// 初始化一个HSSFWorkbook对象
HSSFWorkbook workbook = new HSSFWorkbook();
// 创建一个表
HSSFSheet sheet = workbook.createSheet("李矾");
// 创建行
HSSFRow row = sheet.createRow(0);
// 创建单元格
HSSFCell cell0 = row.createCell(0);
// 给单元格写入内容
cell0.setCellValue(new HSSFRichTextString("姓名"));
// 写出去
workbook.write(outputStream);
具体实现可参考: http://www.cnblogs.com/lantu1989/p/6695086.html
http://www.cnblogs.com/lantu1989/p/6792831.html
第三方缓存redis(基于mybatis二级缓存实现第三方缓存)
1) 下载redis,并安装
2) 导入相关jar包
3) 开启mybatis的二级缓存
4) 实现mybatis的Cache接口
5) 实体类实现系列化接口(Serializeble)
6) 使用spring管理redis(具体配置如下代码:)
<!-- 配置redis 单机版 -->
<!-- redis数据源 -->
<bean id="poolConfig" class="redis.clients.jedis.JedisPoolConfig">
<!-- 最大空闲数 -->
<property name="maxIdle" value="${redis.maxIdle}" />
<!-- 最大空闲数 -->
<property name="maxTotal" value="${redis.maxActive}" />
<!-- 最大等待时间 -->
<property name="maxWaitMillis" value="${redis.maxWait}" />
<!-- 返回连接时,检测连接是否成功 -->
<property name="testOnBorrow" value="${redis.testOnBorrow}" />
</bean>
<!-- Spring-redis连接池管理工厂 -->
<bean id="jedisConnectionFactory" class="org.springframework.data.redis.connection.jedis.JedisConnectionFactory">
<!-- IP地址 -->
<property name="hostName" value="${redis.host}" />
<!-- 端口号 -->
<property name="port" value="${redis.port}" />
<!-- 超时时间 -->
<property name="timeout" value="${redis.timeout}" />
<property name="poolConfig" ref="poolConfig" />
</bean>
<!-- redis模板类,提供了对缓存的增删改查 -->
<bean id="redisTemplate" class="org.springframework.data.redis.core.RedisTemplate">
<property name="connectionFactory" ref="jedisConnectionFactory" />
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.JdkSerializationRedisSerializer" />
</property>
</bean>
<!-- StrRedisTemplate -->
<bean id="strRedisTemplate" class="org.springframework.data.redis.core.StringRedisTemplate">
<property name="connectionFactory" ref="jedisConnectionFactory" />
<property name="keySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="valueSerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
<property name="hashKeySerializer">
<bean class="org.springframework.data.redis.serializer.StringRedisSerializer" />
</property>
</bean>
<!-- 使用中间类解决RedisCache.jedisConnectionFactory的静态注入,从而使MyBatis实现第三方缓存 -->
<bean id="redisCacheTransfer" class="sysone.zr.com.utils.RedisCacheTransfer">
<property name="jedisConnectionFactory" ref="jedisConnectionFactory"/>
</bean>
<!-- //End 单机版Redis集成 -->
具体实现可参考:http://www.cnblogs.com/lantu1989/p/6800279.html
http://www.cnblogs.com/lantu1989/p/6802747.html
多线程下载:
1) 开辟N个线程
2) 根据N个线程计算出每个线程下载的起点和结束点
3) 开启下载
4) 下载结束后,将N个文件进行拼接
5) 删除临时文件
具体实现可参考: http://www.cnblogs.com/lantu1989/p/6729534.html
微信项目
1)注册微信公众号
2)配置URL
3)Token验证
4)验签(sha1加密)
5)获取access_token,其中需要appid和secret两个参数,向微信服务器发送http请求(GET)
6)将菜单对象转成json数据,向微信服务器发送http请求(POST)
7)获取模板id,获取相应的微信号,向微信服务器发送http请求(POST)
8)用户发送消息,先到达微信服务器,微信服务器向程序发送post请求,响应的数据是XML格式,解析xml,获取相关的信息,再向微信服务器发送post请求(数据格式为xml格式),微信服务器转发给客户,便实现了自动回复消息。
9)is_to_all如果为true,则全部(所有关注该公众号的用户)发送,tag_id分组群发;向微信服务器发送http请求(post),数据格式为json格式
附加:
6、基于Spring、SpringMVC、MyBatis集成的通用BaseControl层,实现登录流程,登录采用异步(ajax),异步输出JSON数据,输出方法放在BaseControl,获取用户IP,在BaseControl方法里获取用户IP。登录采用前台数据格式校验(bootstrapvalidate)、后台数据格式校验(正则表达式---->正则表达式工具类),前台数据传输之前进行加密。
①封装BaseConrol的心德
通用性,其它控制层也要使用,只要继承BaseControll就可以直接使用,统一管理,便于维护
②JSON---->fastjson、gson------>心德
都不依赖其它jar,使用也简单方便
Gson的应用主要为toJson与fromJson两个转换函数,无依赖,不需要例外额外的jar,能够直接跑在JDK上。而在使用这种对象转换之前需先创建好对象的类型以及其成员才能成功的将JSON字符串成功转换成相对应的对象。
类里面只要有get和set方法,Gson完全可以将复杂类型的json到bean或bean到json的转换,是JSON解析的神器。
Gson在功能上面无可挑剔,但是性能上面比FastJson有所差距。
FastJson在复杂类型的Bean转换Json上会出现一些问题,可能会出现引用的类型,导致Json转换出错,需要制定引用。FastJson采用独创的算法,将parse的速度提升到极致,超过所有json库。
③获取用户IP----->用来做什么?意义?
做异地登陆的判断,或者统计ip访问次数等
④前台校验----->bootstrapvalidate实现身份证号、手机号、。。。。。(10个数据格式校验)---->前台加密---->发送数据
⑤前台加密的意义
防止传输过程中被拦截,如果是明文,别人轻而易举可得到明文的内容;如果是加密后,即时拦截了,也只是到得一串字符串。因此,提高了安全性。
⑥后台加密---->正则表达式的使用方法------>后台校验的意义----->我的做法的优势和好处
即时前端加密了,还是可以在拦截在传输过程中进行拦截,通过拦截得到加密后的数据去访问服务器,还是可以获得数据;为了避免这个问题,后台再次进行加密,可以解决此问题,提高系统的安全性
后台校验比较常见的验证码验证,可以防止恶意登陆注册,防止脚本进行批量操作
解决高并发:
在面对大量用户访问、高并发请求方面,基本的解决方案集中在这样几个环节:使用高性能的服务器、高性能的数据库、高效率的编程语言、还有高性能的Web容器。
从低成本、高性能和高扩张性的角度出发
1、HTML静态化
大家都知道,效率最高、消耗最小的就是纯静态化的html页面,所以我们尽可能使我们的网站上的页面采用静态页面来实现,这个最简单的方法其实也是最有效的方法。但对于大量内容并且频繁更新的网站,我们无法全部手动去挨个实现
2、图片、视频服务器分离(或者动静分离)
图片是最消耗资源的,于是我们有必要将图片与页面进行分离,这是基本上大型网站都会采用的策略,他们都有独立的图片服务器,甚至很多台图片服务器。这样的架构可以降低提供页面访问请求的服务器系统压力,并且可以保证系统不会因为图片问题而崩溃,在应用服务器和图片服务器上,可以进行不同的配置优化,比如apache在配置ContentType的时候可以尽量少支持,尽可能少的LoadModule,保证更高的系统消耗和执行效率。
3、数据库集群和库表散列
大型网站都有复杂的应用,这些应用必须使用数据库,那么在面对大量访问的时候,数据库的瓶颈很快就能显现出来,这时一台数据库将很快无法满足应用,于是我们需要使用数据库集群或者库表散列。
4、缓存
Apache提供了自己的缓存模块,也可以使用外加的Squid模块进行缓存,这两种方式均可以有效的提高Apache的访问响应能力。 网站程序开发方面的缓存,Linux上提供的Memory Cache是常用的缓存接口,可以在web开发中使用,比如用Java开发的时候就可以调用MemoryCache对一些数据进行缓存和通讯共享,一些大型社区使用了这样的架构。另外,在使用web语言开发的时候,各种语言基本都有自己的缓存模块和方法
5、负载均衡
负载均衡将是大型网站解决高负荷访问和大量并发请求采用的终极解决办法。