墙外通道:http://thinkiii.blogspot.com/2014/05/a-brief-introduction-to-per-cpu.html
per-cpu variables are widely used in Linux kernel such as per-cpu counters, per-cpu cache. The advantages of per-cpu variables are obvious: for a per-cpu data, we do not need locks to synchronize with other cpus. Without locks, we can gain more performance.
There are two kinds of type of per-cpu variables: static and dynamic. For static variables are defined in build time. Linux provides a DEFINE_PER_CPU macro to defines this per-cpu variables.
#define DEFINE_PER_CPU(type, name) static DEFINE_PER_CPU(struct delayed_work, vmstat_work);
Dynamic per-cpu variables can be obtained in run-time by __alloc_percpu API. __alloca_percpu returns the per-cpu address of the variable.
void __percpu *__alloc_percpu(size_t size, size_t align) s->cpu_slab = __alloc_percpu(sizeof(struct kmem_cache_cpu),2 * sizeof(void *));
One big difference between per-cpu variable and other variable is that we must use per-cpu variable macros to access the real per-cpu variable for a given cpu. Accessing per-cpu variables without through these macros is a bug in Linux kernel programming. We will see the reason later.
Here are two examples of accessing per-cpu variables:
struct vm_event_state *this = &per_cpu(vm_event_states, cpu); struct kmem_cache_cpu *c = per_cpu_ptr(s->cpu_slab, cpu);
Let's take a closer look at the behaviour of Linux per-cpu variables. After we define our static per-cpu variables, the complier will collect all static per-cpu variables to the per-cpu sections. We can see them by 'readelf' or 'nm' tools:
0000000000000000 D __per_cpu_start ... 000000000000f1c0 d lru_add_drain_work 000000000000f1e0 D vm_event_states 000000000000f420 d vmstat_work 000000000000f4a0 d vmap_block_queue 000000000000f4c0 d vfree_deferred 000000000000f4f0 d memory_failure_cpu ... 0000000000013ac0 D __per_cpu_end
[15] .vvar PROGBITS ffffffff81698000 00898000 00000000000000f0 0000000000000000 WA 0 0 16 [16] .data..percpu PROGBITS 0000000000000000 00a00000 0000000000013ac0 0000000000000000 WA 0 0 4096 [17] .init.text PROGBITS ffffffff816ad000 00aad000 000000000003fa21 0000000000000000 AX 0 0 16
You can see our vmstat_work is at 0xf420, which is within __per_cpu_start and __per_cpu_end. The two special symbols (__per_cpu_start and __per_cpu_end) mark the start and end address of the per-cpu section.
One simple question: there are only one entry of vmstat_work in the per-cpu section, but we should have NR_CPUS entries of it. Where are all other vmstat_work entries?
Actually the per-cpu section is just a roadmap of all per-cpu variables. The real body of every per-cpu variable is allocated in a per-cpu chunk at runt-time. Linux make NR_CPUS copies of static/dynamic varables. To get to those real bodies of per-cpu variables, we use per_cpu or per_cpu_ptr macros.
What per_cpu and per_cpu_ptr do is to add a offset (named __per_cpu_offset) to the given address to reach the read body of the per-cpu variable.
#define per_cpu(var, cpu) (*SHIFT_PERCPU_PTR(&(var), per_cpu_offset(cpu))) #define per_cpu_offset(x) (__per_cpu_offset[x])
It's easier to understand the idea by a picture:
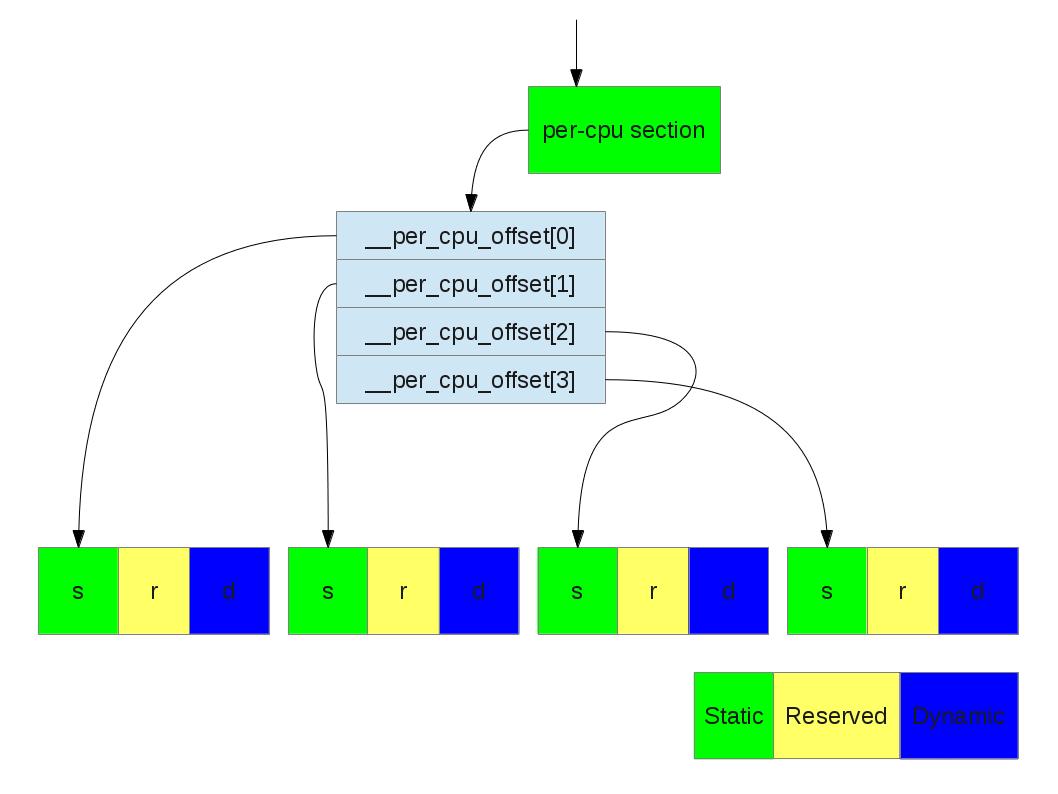
Translating a per-cpu variable to its real body (NR_CPUS = 4)
Take a closer look:
There are three part of an unit: static, reserved, and dynamic.
static: the static per-cpu variables. (__per_cpu_end - __per_cpu_start)
reserved: per-cpu slot reserved for kernel modules
dynamic: slots for dynamic allocation (__alloc_percpu)
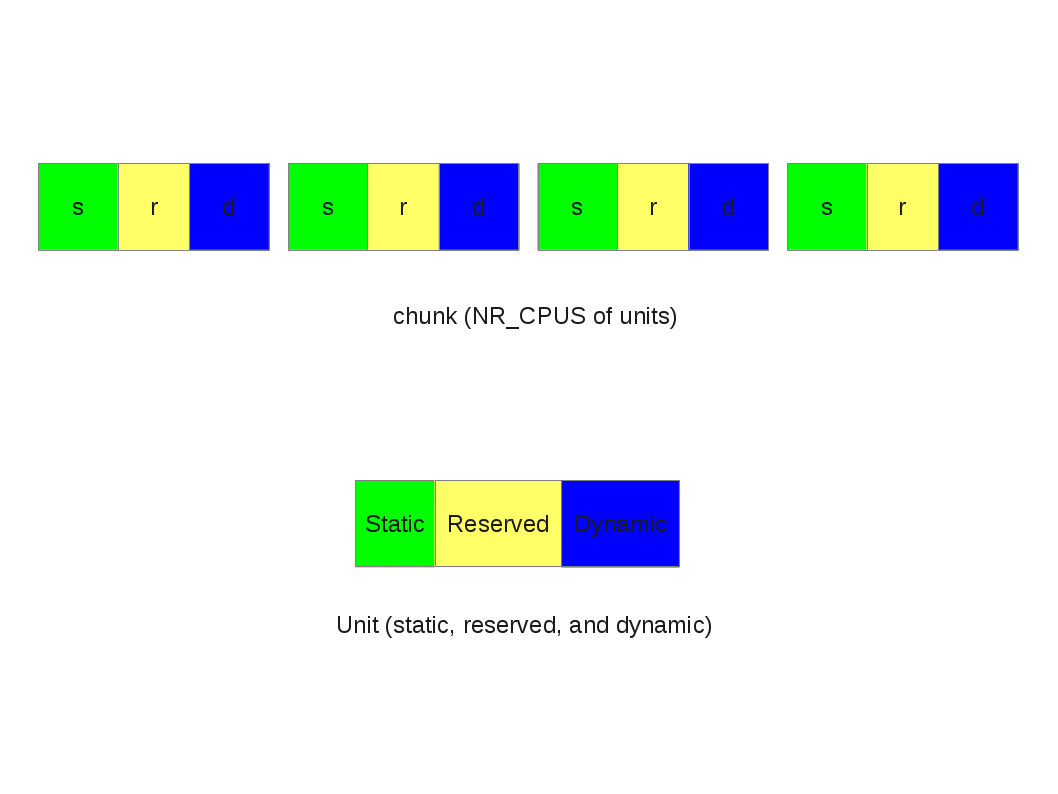
Unit and chunk
static struct pcpu_alloc_info * __init pcpu_build_alloc_info( size_t reserved_size, size_t dyn_size, size_t atom_size, pcpu_fc_cpu_distance_fn_t cpu_distance_fn) { static int group_map[NR_CPUS] __initdata; static int group_cnt[NR_CPUS] __initdata; const size_t static_size = __per_cpu_end - __per_cpu_start; +-- 12 lines: int nr_groups = 1, nr_units = 0;---------------------- /* calculate size_sum and ensure dyn_size is enough for early alloc */ size_sum = PFN_ALIGN(static_size + reserved_size + max_t(size_t, dyn_size, PERCPU_DYNAMIC_EARLY_SIZE)); dyn_size = size_sum - static_size - reserved_size; +--108 lines: Determine min_unit_size, alloc_size and max_upa such that-- }
After determining the size of the unit, the chunk is allocated by the memblock APIs.
int __init pcpu_embed_first_chunk(size_t reserved_size, size_t dyn_size, size_t atom_size, pcpu_fc_cpu_distance_fn_t cpu_distance_fn, pcpu_fc_alloc_fn_t alloc_fn, pcpu_fc_free_fn_t free_fn) { +-- 20 lines: void *base = (void *)ULONG_MAX;--------------------------------- /* allocate, copy and determine base address */ for (group = 0; group < ai->nr_groups; group++) { struct pcpu_group_info *gi = &ai->groups[group]; unsigned int cpu = NR_CPUS; void *ptr; for (i = 0; i < gi->nr_units && cpu == NR_CPUS; i++) cpu = gi->cpu_map[i]; BUG_ON(cpu == NR_CPUS); /* allocate space for the whole group */ ptr = alloc_fn(cpu, gi->nr_units * ai->unit_size, atom_size); if (!ptr) { rc = -ENOMEM; goto out_free_areas; } /* kmemleak tracks the percpu allocations separately */ kmemleak_free(ptr); areas[group] = ptr; base = min(ptr, base); } +-- 60 lines: Copy data and free unused parts. This should happen after all--- }
static void * __init pcpu_dfl_fc_alloc(unsigned int cpu, size_t size, size_t align) { return memblock_virt_alloc_from_nopanic( size, align, __pa(MAX_DMA_ADDRESS)); }