《Java8 实战》读书笔记
第一章:Java8
1.1.2 流处理: java.util.strem 可以将代码思路改变成 从一个流到另外一个流,Java可以透明地将处理过程并行 拿到几个CPU内核上分别执行Stream操作流水线(简化并行操作的成本)
1.1.3 用行为参数化将代码传递给方法
1.1.3 流处理能力 要保证 不访问共享的可变数据
第二章: 通过行为参数化传递代码
1、 可通过参数 传递代码/行为: 创建一个函数式接口,接口中只能有一个抽象方法,皆空中可以拥有默认方法
可以在函数式接口上加@FunctionalInterface 标注某接口是函数式接口,编译器会进行检查 该函数是否符合函数式接口的定义
2、 多种行为,一个参数: 可通过不同的接口实现 定义多种行为
3、 可使用匿名类 避免啰嗦的接口实现
4、 可使用Lambda表达式 更简介地实现接口
第三章: Lambda表达式
- Lambda 表达式基本格式 (Apple a1,Apple a2)-> a1.getW().compare(a2.getW())
- 包括参数(类型,变量名)+ -> +Lambda主体
- 表达式不用带{} ,语句需要带{} ,例如:
- 1、(parameters)->expression
- 2、(parrameters)->{statements; }
- 参数可以为空
- 参数类型可以省略 编译器可以自己推断
- 当只有一个参数时 括号()也可省略
- Lambda表达式利用函数式接口的步骤
- 定义函数式接口(一般使用Java提供的即可)
- 利用函数式接口 将具体业务的函数 行为参数化
- 利用Lambda表达式 实现函数式接口
- 具体业务函数 执行函数式接口内定义的方法
- 常见默认函数式接口
- Predicted<T> : boolean test(T t)
- Comsumer<T>: void accept(T t)
- Fuction<T,R> : R apply(T t)
- 原始类型特化 : 避免装箱造成的代价(装箱后保存在堆中)
- 如 IntPredicate: boolean test(int t)
- 常见函数式接口


- Lambda 表达式自动类型检查的具体步骤:
- 找出使用Lambda表达式的函数对应的参数类型(是个函数式接口) 如Predicted<Apple>
- 找出这个函数式接口的方法,Lambda表达式的 参数要符合这个方法的参数
注意:同一个Lambda 可以对应不同的 函数式接口
- Lambda表达式 若使用局部变量 那局部变量必须是final型 或 事实上是final
- 局部变量保存在栈中
- 若Lambda使用新的线程去访问局部变量 实际是访问它的副本 若局部变量仅仅被赋值一次 就没什么影响
- 方法引用(更简洁地写Lambda语句)
- Apple::getWeight 等价于 (Apple a)->a.getWeight()
- 构造函数也可以使用方法引用 并可以使用带参数的构造函数
- Supplier<Apple> c1=Apple::new 返回Apple类型的对象 使用默认构造函数
- Supplier<Interger,Apple> c1=Apple::new 使用参数为Interger的构造函数
- 复合Lambda表达式
- 比较器复合
- 逆序 appleList.sort(comparing(Apple::getWeight).reversed());
- 比较器链: 按重量递减;一样重时按国家排序
- sort(comparing(Apple::getWeight).reversed()
- 比较器复合
.thenComparing(Apple::getCountry));
- 谓词复合 negate 非,and ,or (复合顺序从左向右 确定优先级)
- Predicate<Apple> redAndHeavyAppleOrGreen=redApple.and(a->a.getWeight()>150)
.or(a->”green”.euquals(a.getColor()));
- 函数复合
- andThen: f.andThen(g) 相当于 g(f(x))
- compose: f.compose(g) 相当于 f(g(x))
- Lambda表达式的用处
- 在环绕执行模式 可以利用Lambda提高灵活性和可重用性
- 环绕执行模式指的是:在一个方法所必须的代码中间,你需要执行一些操作
第四章: 流 Stream
- 流的概念: 从支持数据处处理操作的源 生成的元素序列P72
A stream is a sequence of elements from a source that supports data processing operations
- 流与集合的区别:
- 流中的元素是按需计算的,流就像一个延迟创建的集合,只有在消费者要求的时候才会计算
- 集合是内存中的数据结构 每个元素都需要先计算处理 才能添加到集合中
- 流只能遍历一次
- 内部迭代:流帮我们将迭代做了 这样流可以透明的并行处理 或 用更优化的顺序处理
- 中间操作: filter或 sorted 操作 会返回另外一个流,且只在触发终端操作后执行
- 终端操作: 从流的 流水线 生成结果,结果不含流
第五章: 使用流
5.1 筛选和切片
- 谓词筛选: 返回boolean的函数称为谓词; filter方法接收谓词 做出筛选
- 去重 distinct()
- 截断 只取n个元素 limit(n)
- 跳过 跳过前n个元素 skip(n)
5.2 映射 (一种类型 映射成另外一种类型)
- map() 将每个元素 映射成一个新的元素 如map(Dish::getName) 或 map(n->n*n)
- flatMap() 扁平化一个流
5.3 查找和匹配 (终端操作)
1、 allMatch 、anyMatch 、noneMatch、(加谓词 即可判断)
2、 findFirst、 findAny 需要使用Optional<T> 做返回值 因为可能结果不存在
3、 Optional 中的方法:
isPresent() 包含值时返回true;ifPresent(Consumer<T> block) 值存在时执行代码块
T get() 返回值,若不存在抛出NoSuchElement异常
T orElse(T other) 返回值 若不存在 返回默认值T

注: 函数描述符指的是 操作中 lambda函数的参数类型;有状态指的是 该操作会存储中间状态
5.4 规约 reduce
- 求和
- reduce(0,(a,b)->a+b) 或 reduce(0,Integer::sum);
- 不使用初值时返回为Optinal<Integer>
- 最值
- reduce(Interger::min) 或 reduce((x,y)->x<y?x:y)
5.6 数值流
- 为避免装箱造成的额外成本 存在IntStream DoubleStream 和LongStream 三个数值流,分别将元素特化为int、long、double
- 使用mapToInt mapToDouble mapToLong 可将流 映射到数值流
- 使用.boxed() 将数值流 映射到 流
- 用特化的OptinalInt OptinalDouble OptionalLong 来存储结果,orElse(1) 可提供默认值
- 使用rangeClosed(start,end) 或 range(start,end+1) 产生[start,end] 的数
5.7 构建流
- 由值创建流 of(“v1”,”v2”)
- 由数组创建流stream(new int[] {2,4,5})
- 由文件生成流 Stream<String> lines=Files.lines() P127
- 由函数生成流 (可生成无限流)iterate() 和 generate() P128
- iterate(0,n->n+2)
- generate(Math::random)
第六章:用流收集数据 collect
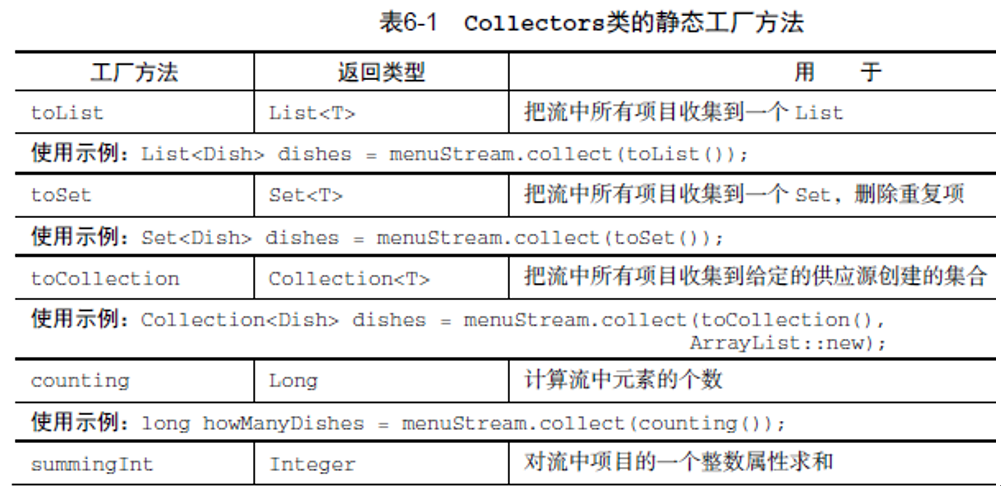


收集器 用函数式编程的方式 将交易按货币分组的例子,避免了指令式风格冗长的代码
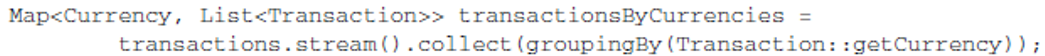
- 预定义收集器 Collectors 实现了 一些预定义的收集器: 如表6-1所示
- 收集器 都可以用reducing工厂方法定义规约过程reducing(初值,转换函数,合并操作)
- reduce 旨在将两个值 结合起来生成一个新值 是一个不可变的归约
- collect 改变容器 积累要输出的结果
- 分组groupingBy
- 按类型分组 groupingBy(Dish::getType)
- 自定义分组 groupingBy(dish->{if(xxx) return TYPE1;else return TYPE2;})
- 多级分组 groupingBy(Dish::getType1,groupingBy(Dish::getType2))
- 按组收集数据groupingBy(Dish::getType,countting())
- 将收集器的结果转化成另外一种类型 groupingBy(Dish::getType,collectingAndThen(maxBy(xx),Optinal::get))P144
- 分区 partitioningBy (实际上是 通过谓词进行分组 组别为true false)
- 自定义Collector P156
- Collector接口:T要收集的数据类型 ;A累加器的类型 ;R返回值的类型

- supplier() 建立累加器实例;accumulator() 将数据累加到累加器
- finisher() 将累加器 转换成 返回值; combiner() 合并 并行结果
- characteristic() 定义收集器的行为
- UNORDERED 归约结果不受遍历和累加顺序影响
- CONCURRENT accumulator()可并行
- IDENTITY_FINISH : A可以直接转换成R
第七章: 并行数据处理与性能

- range 操作比 iterate 更快 因为不用装箱且数据可分段
- 利用 parallel() 命令可以将 顺序流转为 并行流
- sequential() 命令 将并行流 转为顺序流 可以在流水线上 结合这两个命令 实现精细化控制并行
- 并行流中 使用默认的ForkJoinPool ,默认线程数为处理器数量
- Java8 中加入了Spliterator 可分迭代器 用于并行遍历数据源中的数据
- 重写Spliterator的例子P178
实践:1 求两个数组的交集 https://leetcode-cn.com/problems/intersection-of-two-arrays/
return Arrays.stream(nums1)
.filter(n1->Arrays.stream(nums2).anyMatch(n2->n2==n1))
.distinct()
.parallel()
.toArray();