缓存是jQuery中的又一核心设计,jQuery自身的很多东西都依赖于缓存,比如事件、一些中间变量、动画等。同时他还为用户提供接口了使用缓存的接口,方便用户在元素节点上保存自己的数据,并且帮助用户解决直接把数据保存到DOM元素是可能引起的内存泄漏、命名冲突等问题。
同时,html5提出了一种通过属性缓存元素数据的功能,就是data-*属性,他可以以字符串的形式保存数据,并且不会和元素固有属性冲突。jQuery的缓存提供了访问data-*的接口,与html5标准结合更加紧密,更加规范。
提问:jQuery不同版本的缓存实现原理是什么?
答:jQuery1.x与jQuery2.x、jQuery3.x是不同的。
jQuery1.x系列中,需要兼容ie6、ie7等早期的浏览器,在ie6、ie7这样的浏览器中,根据艾伦的博客,我们可以知道DOM元素与js对象相互引用,是会引起浏览器的内存泄漏问题。所以jQuery1.x中,最大的问题是要防止在ie6、ie7浏览器上出现内存泄漏。为了避免DOM元素与js对象相互引用而造成的内存泄漏,jQuery必须从设计解决对象循环引用的问题。所以jQuery1.x将需要缓存到元素上的数据,统一保存到了一个公共存储对象(jQuery.cache)中,jQuery.cache中的数据和缓存持有者之间再通过一uid关联起来。这个uid是从1开始自增的一个数,同时再生成一个key(jQuery.expando)将这个uid保存在缓存所有者对象上。这样元素对象就不会直接引用缓存的对象了,从而不会出现因循环引用而引起的内存泄漏。

而jQuery2.x、jQuery3.x中,因为不需要考虑ie6、ie7浏览器,因而不再为内存泄漏问题担心,所以设计上做出了调整,放弃了将缓存数据保存到jQuery.cache的设计,代替为使用生存一个唯一key,并创建一个json,将这个json以这个唯一key直接保存到缓存持有者中。

此外,一个和jQuery很相似的库——zepto,也提供了缓存系统。它是用html5的data-*属性,将用户缓存的对象序列化为字符串保存到data-*上面的,但是这样做的缺点是类型转换,无法保存function和object对象。相比之下,jQuery的缓存机制就没有这种缺陷。
提问:jQuery1.x的缓存已经设计的很好了,jQuery2.x(3.x)为什么要重新设计呢?
答:jQuery1.x的缓存设计同样存在内存泄漏的问题,主要是jQuery.cache是全局变量,所以jQuery.cache里面的引用的变量,如果引用不被解除,是不会被回收的。虽然缓存的变量不会像DOM对象那么占用内存空间,但是这种浪费同样是程序的一个隐患点。因此,必须在DOM对象对象被从文档移除的时候,再通过jQuery的API将jQuery.cache里面的缓存也会收掉。这样就会给jQuery的DOM操作API实现上增加了难度,每一个涉及到去除的节点对象的API都需要做去除缓存处理,导致了如html、replaceWith、empty等API设计变得更加复杂、执行效率也下降了。而且jQuery也无法保证,用户使用jQuery的API给元素对象设置了缓存后,还会使用jQuery的API将其移除,而不是其他方式。因为,将jQuery的API和原生DOM的API掺杂使用是经常发生的事情,jQuery1.x无法保证这种情况下不能发生内存泄漏问题,如:
var div = $("<div>"); //创建一个span,放入div中,并且给span一个缓存数据{"data": "test"} var span = $("<span>"); span.data("data", "test"); div.append(span); //清空div里面的元素,将span回收 span = null; div[0].innerHTML = ""; //直接使用innerHTML,会造成$.cache里面的{"data": "test"}未被清除,造成内存泄漏 //div.html(""); //如果使用jQuery的html,会清除$.cache里面的{"data": "test"}
所以jQuery2.x不在采用jQuery1.x的jQuery.cache,而是采用了更加简单的设计。
由于笔者查看的是jQuery2.2-stable版源码,所以以下源码分析如不指明版本,都是指jQuery2.x版本。
提问:jQuery的缓存实现的主要有哪些部分?
答:jQuery缓存相关的主要部分及API如下:
|
名称 |
对外暴露 |
作用 |
|
Data |
否 |
一个缓存的操作接口类,所有缓存操作都是通过Data的实例完成的,Data实例会自动为缓存所属对象创建保存缓存的json对象。 每个Date的实例会生成一个uid,我们称之为expando,并且会将这个expando的值为缓存对象的集合在缓存持有者上面命名,这样即使同一个对象,不同Data实例为之保存的数据是不会冲突的 |
|
dataPriv |
否 |
一个Data实例,保存jQuery内部的数据,如果jQuery的事件、动画等数据都由这个访问器保存和获取 |
|
dataUser |
否 |
一个Data实例,保存用户通过jQuery的API存储的数据 |
|
jQuery.expando |
是 | jQuery自身的id,理论上每个jQuery的expando都不一样,用于生成访问器Data实例的expando |
|
jQuery.hasData |
是 | 判断DOM元素对象、js对象是否有缓存数据(包括通过dataPriv缓存和dataUser缓存) |
|
jQuery.data |
是 | 直接调用dataUser的access |
|
jQuery.removeData |
是 |
直接调用dataUser的removeData |
|
jQuery._data |
是 | 直接调用dataPriv的access |
|
jQuery._removeDat |
是 | 直接调用dataPriv的removeData |
|
acceptData |
是 |
判断对象能不能有缓存,jQuery认为只有普通对象和元素节点需要缓存数据,非元素(Element)和document外DOM元素,都不能缓存数据 |
|
jQuery.fn.data |
是 | 先获取元素的html5的data-*里面的数据,如果没有再调用dataUser |
|
jQuery.fn.removeData |
是 |
循环调用dataUser.remove方法,删除key对应的缓存数据 |
jQuery缓存部分的核心的就是缓存操作接口Data类,这是所有jQuery缓存操作的底层实现。这个类有两个实例——dataPriv和dataUser。dataPriv是供jQuery自身使用,dataUser是供用户缓存数据使用。对外,jQuery暴露的API中,最核心的两个就是jQuery.data和jQuery.fn.data,前者操作普通js对象和DOM对象(jQuery仅支持元素对象),后者操作jQuery对象。
提问:expando的生成算法是什么?
答:我们先看jQuery.expando:
jQuery.extend( { // Unique for each copy of jQuery on the page expando: "jQuery" + ( version + Math.random() ).replace( /D/g, "" ), }
生成jQuery.expando的算法包含了jQuery的版本和随机数,这样尽可能地保证了同一window下的多个jQuery实例不会冲突。
再看访问器Data的构造函数:
function Data() { this.expando = jQuery.expando + Data.uid++; }
Data中有一个公有属性——uid,每创建一个Data实例的时候,都会给这个uid加一,并且通过这个uid和jQuery.expando一同生成Data实例的expando。这样最大限度的保证了一个页面中多个jQuery实例各自的多个Data实例彼此也不会冲突。
提问:Data是如何工作的?
答:Data的主要功能包括如下:
1.给指定对象创建一个保存缓存的Object对象,并将这个map对象用Data.expando作为key赋值到这个指定对象中。并通过acceptData,对于非元素类型和document的DOM对象,Data实例是不会为其缓存数据的。
function acceptData( owner ) { // Accepts only: // - Node // - Node.ELEMENT_NODE // - Node.DOCUMENT_NODE // - Object // - Any return owner.nodeType === 1 || owner.nodeType === 9 || !( +owner.nodeType ); }
2.提供了get、set等对key、value操作的API,并且通过了重载setter和getter的access。需要注意的是,一些浏览不支持删除DOM对象的成员变量,所以jQuery使用赋值undefined来代替delete操作
// Remove the expando if there's no more data if ( key === undefined || jQuery.isEmptyObject( cache ) ) { // Support: Chrome <= 35-45+ // Webkit & Blink performance suffers when deleting properties // from DOM nodes, so set to undefined instead // https://code.google.com/p/chromium/issues/detail?id=378607 if ( owner.nodeType ) { owner[ this.expando ] = undefined; } else { delete owner[ this.expando ]; } }
提问:jQuery的Data已经做了冲突处理,那我们在使用jQuery时候,需要再考虑缓存冲突的情况吗?
答:答案是需要的,因为我们不能自己创建Data实例,用户能够使用缓存都只能由dataUser这个Data实例执行,所以jQuery的Data防冲突机制仅是给jQuery内部用的,我们无法享用。所以我们在使用jQuery的jQuery.data和jQuery.fn.data接口时,是需要自己做防止冲突的处理的。尤其是对于开发jQuery插件的时候,不希望插件的缓存与插件的使用者的缓存key冲突,所以必须要加命名空间,笔记建议用插件在jQuery的名称做前缀,如:
(function ($, global, undefined) { $.fn.extend({ myPlugin : function (option) { return this.each(function () { //开发插件时候,如果要用data保存数据,原有key前面要加上控件的名字,以防止冲突 $(this).data("myPlugin:key",pluginData); }) } }) })(jQuery,window)
提问:jQuery.data和jQuery.fn.data具体有什么区别?
答:他们是不同维度的两个API,一个操作的是jQuery对象,一个是js对象(Object和DOM对象),具体的用法为:
//jQuery.fn.data: $(object).data(cacheKey,cacheValue) //会在object对象上创建dataUser.expando //jQuery.data: $.data(object, cacheKey, cacheValue) //会在object对象上创建dataUser.expando
上述代码,两者的作用基本相同,但是还是存在区别:
1.jQuery.fn.data除了会查询通过dataUser缓存的对象外,还会访问html5的data-*数据,但只能读,不能修改。优先级为:如果指定key在dataUser存在数据,会优先返回dataUser的数据,否则才会查看属性为data-*中对应key的数据。同时,为了和html5的data-*缓存方式相互匹配,Data会自动将“x-x-x”这种key形式转换为“xXX”这种驼峰命名形式。而这些功能仅jQuery.fn.data有,jQuery.data是没有的。
2.jQuery.fn.data做赋值操作时候,会遍历jQuery对象封装的所有js对象(element对象),为其赋值,而jQuery.data仅能对单个对象使用。同时jQuery.fn.data符合jQuery的链式操作,返回jQuery对象,而jQuery.data则是赋值的值。
需要注意的是,使用jQuery.data函数时候,不应该用jQuery对象做参数,如下:
$.data($(object), cacheKey, cacheValue) //会在$(object)对象上创建dataUser.expando,这样调用是错误的
dataUser.expando会被创建在$(object)这个对象上,而不是object对象,以后再调用$.data($(object), cacheKey)是取不出缓存的,这是我们不希望的。造成这个现象的原因是两次$(object)不是同一个对象,但是缓存实际操作中大多数都是无法保证可以使用同一jQuery对象,因此要避免这么使用。
提问:那么使用这两个接口设置的数据,能相互访问吗?
答:答案当然是肯定的,因为两个api最终都是通过dataUser这个Data实例去访问object对象的缓存,所以肯定是可以相关访问的。
var div = $("<div>"); div.data("a", "a"); $.data(div[0], "b", "b"); console.log(div.data("b")) //结果b console.log($.data(div[0],"a")) //结果a
但是如果key是x-x-x这种形式,jQuery.fn.data会自动转为驼峰命名发,而jQuery.data不会:
var div = $("<div>"); div.data("x-x-x", "test1"); $.data(div[0], "x-x-x", "test2");
console.log(div.data());
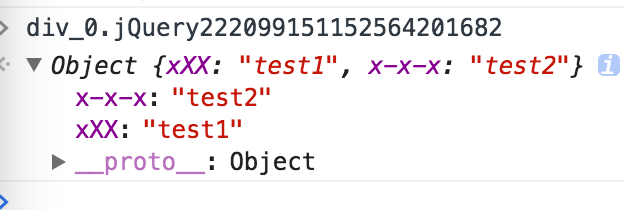
从上图可以看出test1的key被转为驼峰命名法,而test2却没有,这也是两者的一个区别。
提问:jQuery.hasData为什么也检查dataPriv中是否存在数据?
hasData: function( elem ) { return dataUser.hasData( elem ) || dataPriv.hasData( elem ); },
根据jQuery缓存的设计来讲,用户的数据都在dataUser里面,dataPriv缓存的数据应该是对用户透明的,用户不关心dataPriv是否有数据。那为什么jQuery.hasData还会去调用dataPriv的hasData呢?
答:之所以这么做,是为了和jQuery1.x在API功能上面保持兼容,因为jQuery1.x系列jQuery内部缓存和用户缓存都放到了一个对象中,而hasData的功能就是检测是否存在这个对象。jQuery2.x做了防冲突处理,缓存变成了两个对象——dataUser和dataPriv,但为了两个版本对外暴露的API尽量保持一致,所以没有重新设计jQuery.hasData的功能,而是保留了jQuery1.x的功能设计。在jQuery3.x中同样延续了这个功能定义,而不是重构为更合理的仅检测dataUser的设计方案。
API在升级的时候功能保持一致,虽然不利于API功能的优化,但是满足了里氏替换原则,方便使用者升级版本。