Spark SQL 1.2
运行原理
case class方式
json文件方式
背景:了解到HDP也能够支持Spark SQL,但官方文档是版本1.2,希望支持传统数据库、hadoop平台、文本格式的整合处理
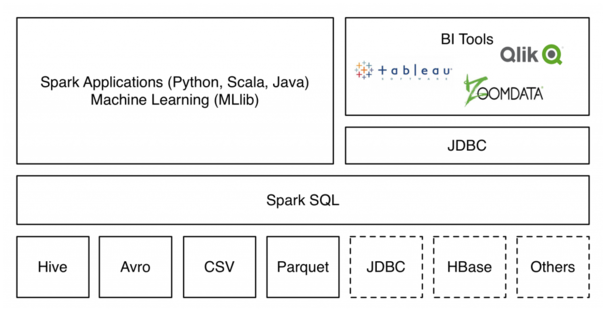
虚线表示还未实现。支持从现有Apache Hive表以及流行的Parquet列式存储格式中读取数据,数据源API通过Spark SQL提供了访问结构化数据的可插拔机制(接口需要自己实现,后面附有)。数据源 API可以作为Spark平台的统一数据接入。数据源API的另外一个优点就是不管数据的来源如何,用户都能够通过Spark支持的所有语言来操作这些数据,很容易的使用单一接口访问不同数据源的数据。访问Spark Packages 来获取最新的可用库列表。
以下从Spark SQL1.1初始版本来理解其运行原理。
SparkSQL引入了一种新的RDD——SchemaRDD,SchemaRDD由行对象(row)以及描述行对象中每列数据类型的schema组成;SchemaRDD很象传统数据库中的表。SchemaRDD可以通过RDD、Parquet文件、JSON文件、或者通过使用hiveql查询hive数据来建立。SchemaRDD除了可以和RDD一样操作外,还可以通过registerTempTable注册成临时表,然后通过SQL语句进行操作。
- Spark1.1在hiveContext中,hql()将被弃用,sql()将代替hql()来提交查询语句,统一了接口。
- 使用registerTempTable注册表是一个临时表,生命周期只在所定义的sqlContext或hiveContext实例之中。换而言之,在一个sqlontext(或hiveContext)中registerTempTable的表不能在另一个sqlContext(或hiveContext)中使用。
- spark1.1提供了两种语法解析器:sql语法解析器和hiveql语法解析器。
- hiveContext现在支持sql语法解析器和hivesql语法解析器,默认为hivesql语法解析器,用户可以通过配置切换成sql语法解析器,来运行hiveql不支持的语法,如select 1。
- sqlContext基础应用
- RDD
- parquet文件
- json文件
- hiveContext基础应用
- 混合使用
- 缓存之使用
- DSL之使用
下面介绍几种导入的方式:
创建RDD的形式,测试txt文本
spark://master:7077
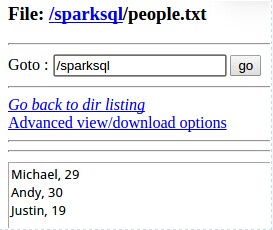
路径为hdfs上的相对路径。
./bin/spark-shell
scala> val sqlContext = new org.apache.spark.sql.SQLContext(sc)
sqlContext: org.apache.spark.sql.SQLContext = org.apache.spark.sql.SQLContext@2013f094
scala> import sqlContext.createSchemaRDD
import sqlContext.createSchemaRDD
scala> case class Person(name: String, age: Int)
defined class Person
scala> val people = sc.textFile("/user/p.txt").map(_.split(",")).map(p => Person(p(0), p(1).trim.toInt))
15/05/05 06:30:35 INFO storage.MemoryStore: ensureFreeSpace(190122) called with curMem=0, maxMem=278302556
15/05/05 06:30:35 INFO storage.MemoryStore: Block broadcast_0 stored as values in memory (estimated size 185.7 KB, free 265.2 MB)
15/05/05 06:30:35 INFO storage.MemoryStore: ensureFreeSpace(29581) called with curMem=190122, maxMem=278302556
15/05/05 06:30:35 INFO storage.MemoryStore: Block broadcast_0_piece0 stored as bytes in memory (estimated size 28.9 KB, free 265.2 MB)
15/05/05 06:30:35 INFO storage.BlockManagerInfo: Added broadcast_0_piece0 in memory on localhost:59627 (size: 28.9 KB, free: 265.4 MB)
15/05/05 06:30:35 INFO storage.BlockManagerMaster: Updated info of block broadcast_0_piece0
15/05/05 06:30:35 INFO spark.DefaultExecutionContext: Created broadcast 0 from textFile at <console>:17
people: org.apache.spark.rdd.RDD[Person] = MappedRDD[3] at map at <console>:17
scala> people.registerTempTable("people")
scala> val teenagers = sqlContext.sql("SELECT name FROM people WHERE age >= 3 AN
D age <= 19")
teenagers: org.apache.spark.sql.SchemaRDD =
SchemaRDD[6] at RDD at SchemaRDD.scala:108
== Query Plan ==
== Physical Plan ==
Project [name#0]
Filter ((age#1 >= 3) && (age#1 <= 19))
PhysicalRDD [name#0,age#1], MapPartitionsRDD[4] at mapPartitions at ExistingRDD.scala:36
scala> teenagers.map(t => "Name: " + t(0)).collect().foreach(println)
15/05/05 06:31:18 WARN shortcircuit.DomainSocketFactory: The short-circuit local reads feature cannot be used because libhadoop cannot be loaded.
15/05/05 06:31:18 INFO mapred.FileInputFormat: Total input paths to process : 1
15/05/05 06:31:18 INFO spark.DefaultExecutionContext: Starting job: collect at <console>:18
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Got job 0 (collect at <console>:18) with 2 output partitions (allowLocal=false)
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Final stage: Stage 0(collect at <console>:18)
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Parents of final stage: List()
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Missing parents: List()
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Submitting Stage 0 (MappedRDD[7] at map at <console>:18), which has no missing parents
15/05/05 06:31:18 INFO storage.MemoryStore: ensureFreeSpace(6400) called with curMem=219703, maxMem=278302556
15/05/05 06:31:18 INFO storage.MemoryStore: Block broadcast_1 stored as values in memory (estimated size 6.3 KB, free 265.2 MB)
15/05/05 06:31:18 INFO storage.MemoryStore: ensureFreeSpace(4278) called with curMem=226103, maxMem=278302556
15/05/05 06:31:18 INFO storage.MemoryStore: Block broadcast_1_piece0 stored as bytes in memory (estimated size 4.2 KB, free 265.2 MB)
15/05/05 06:31:18 INFO storage.BlockManagerInfo: Added broadcast_1_piece0 in memory on localhost:59627 (size: 4.2 KB, free: 265.4 MB)
15/05/05 06:31:18 INFO storage.BlockManagerMaster: Updated info of block broadcast_1_piece0
15/05/05 06:31:18 INFO spark.DefaultExecutionContext: Created broadcast 1 from broadcast at DAGScheduler.scala:838
15/05/05 06:31:18 INFO scheduler.DAGScheduler: Submitting 2 missing tasks from Stage 0 (MappedRDD[7] at map at <console>:18)
15/05/05 06:31:18 INFO scheduler.TaskSchedulerImpl: Adding task set 0.0 with 2 tasks
15/05/05 06:31:18 INFO scheduler.TaskSetManager: Starting task 0.0 in stage 0.0 (TID 0, localhost, ANY, 1293 bytes)
15/05/05 06:31:18 INFO scheduler.TaskSetManager: Starting task 1.0 in stage 0.0 (TID 1, localhost, ANY, 1293 bytes)
15/05/05 06:31:18 INFO executor.Executor: Running task 1.0 in stage 0.0 (TID 1)
15/05/05 06:31:18 INFO executor.Executor: Running task 0.0 in stage 0.0 (TID 0)
15/05/05 06:31:18 INFO rdd.HadoopRDD: Input split: hdfs://master:8020/user/p.txt:15+15
15/05/05 06:31:18 INFO rdd.HadoopRDD: Input split: hdfs://master:8020/user/p.txt:0+15
15/05/05 06:31:19 INFO executor.Executor: Finished task 0.0 in stage 0.0 (TID 0). 1755 bytes result sent to driver
15/05/05 06:31:19 INFO executor.Executor: Finished task 1.0 in stage 0.0 (TID 1). 1733 bytes result sent to driver
15/05/05 06:31:19 INFO scheduler.TaskSetManager: Finished task 1.0 in stage 0.0 (TID 1) in 750 ms on localhost (1/2)
15/05/05 06:31:19 INFO scheduler.DAGScheduler: Stage 0 (collect at <console>:18) finished in 0.782 s
15/05/05 06:31:19 INFO scheduler.TaskSetManager: Finished task 0.0 in stage 0.0 (TID 0) in 772 ms on localhost (2/2)
15/05/05 06:31:19 INFO scheduler.TaskSchedulerImpl: Removed TaskSet 0.0, whose tasks have all completed, from pool
15/05/05 06:31:19 INFO scheduler.DAGScheduler: Job 0 finished: collect at <console>:18, took 0.860763 s
Name: kang
Name: wu
Name: liu
Name: zhang
2. json文件方式
sqlContext可以从jsonFile或jsonRDD获取schema信息,来构建SchemaRDD,注册成表后就可以使用。这里又更详细的例子
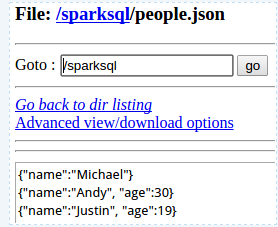
官网上文档
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
val df = sqlContext.jsonFile("examples/src/main/resources/people.json")
// Displays the content of the DataFrame to stdout
df.show()
val sc: SparkContext // An existing SparkContext.
val sqlContext = new org.apache.spark.sql.SQLContext(sc)
// Create the DataFrame
val df = sqlContext.jsonFile("examples/src/main/resources/people.json")
// Show the content of the DataFrame
df.show()
// age name
// null Michael
// 30 Andy
// 19 Justin
// Print the schema in a tree format
df.printSchema()
// root
// |-- age: long (nullable = true)
// |-- name: string (nullable = true)
// Select only the "name" column
df.select("name").show()
// name
// Michael
// Andy
// Justin
// Select everybody, but increment the age by 1
df.select("name", df("age") + 1).show()
// name (age + 1)
// Michael null
// Andy 31
// Justin 20
// Select people older than 21
df.filter(df("name") > 21).show()
// age name
// 30 Andy
// Count people by age
df.groupBy("age").count().show()
// age count
// null 1
// 19 1
// 30 1
测试:
./spark-shell
scala>val sqlContext = new org.apache.spark.sql.SQLContext(sc)
scala>val df = sqlContext.jsonFile("/user/j.json")
scala>df.show()
scala>df.printSchema()
root
|-- age: long (nullable = true)
|-- name: string (nullable = true)
scala>df.filter(df("name") > 21).show()
scala>df.groupBy("age").count().show()
age count
null 1
19 1
30 1
---------------------------------------------华丽分割线--------------------------------------------------------------------------------------------------
继续调研测试Spark SQL对关系型数据库的支持
数据源API通过Spark SQL提供了访问结构化数据的可插拔机制。数据源不仅仅有了简便的途径去进行数据转换并加入到Spark 平台。
使用数据源和通过SQL访问他们一样简单(或者你喜爱的Spark语言)
CREATE TEMPORARY TABLE episodes USING com.databricks.spark.avro OPTIONS (path "episodes.avro")
数据源API的另外一个优点就是不管数据的来源如何,用户都能够通过Spark支持的所有语言来操作这些数据 。例如,那些用Scala实现的数据源,pySpark用户不需要其他的库开发者做任何额外的工作就可以使用。此外,Spark SQL可以很容易的使用单一接口访问不同数据源的数据。
json格式与parquet

经过调研,Spark只支持文本格式导入,如果要实现与jdbc/odbc连接关系型数据库,需要自己实现
参考:Spark SQL External Data Sources JDBC简易实现 该Github源码:https://github.com/luogankun/spark-jdbc
实现了对MySQL/Oracle/DB2的查询 支持类型string&int&long×tamp&date 还需要测试hive和hbase即可
这样可以实现基本功能,利用自己实现的连接和临时表共同查询的方式,但自己实现相对比较简单不完善。
所以还是接着看能不能HDP2.2融合Spark1.3 实在不行单独安装Spark1.3