W3School官方文档:http://www.w3school.com.cn/xpath/index.asp
我们使用xpath主要是获取网页数据的,之前一直是使用bs4,xpath也是最近了解到的,找了很多资料,感觉写的都不是很明白,这里我就把我的理解写一下。
首先,lxml是一款高性能的 Python HTML/XML 解析器,我们可以利用XPath,来快速的定位特定元素以及获取节点信息,效率也要别bs4(关于bs4我有一篇beautifulshou的博客可以参考一下)高些。
使用这个就是快速的将html中我们需要的数据找出来。
在使用之前我们需要安装lxml解析器
pip install lxml
安装了之后,我们要对需要获取数据的网页数据进行解析
网页数据的解析
解析分为两种方式
解析html字符串
使用“lxml.etree.HTML( )”进行解析。etree.tostring( )方法可以将htmlelement元素转化成字符串,可以正常打印出来。示例代码如下:
from lxml import etree html = ''' <html> <head> <meta name="content-type" content="text/html; charset=utf-8" /> <title>友情链接查询 - 站长工具</title> <!-- uRj0Ak8VLEPhjWhg3m9z4EjXJwc --> <meta name="Keywords" content="友情链接查询" /> <meta name="Description" content="友情链接查询" /> </head> <body> <h1 class="heading">Top News</h1> <p style="font-size: 200%">World News only on this page</p> Ah, and here's some more text, by the way. <p>... and this is a parsed fragment ...</p> <a href="http://www.cydf.org.cn/" rel="nofollow" target="_blank">青少年发展基金会</a> <a href="http://www.4399.com/flash/32979.htm" target="_blank">洛克王国</a> <a href="http://www.4399.com/flash/35538.htm" target="_blank">奥拉星</a> <a href="http://game.3533.com/game/" target="_blank">手机游戏</a> <a href="http://game.3533.com/tupian/" target="_blank">手机壁纸</a> <a href="http://www.4399.com/" target="_blank">4399小游戏</a> <a href="http://www.91wan.com/" target="_blank">91wan游戏</a> </body> </html> ''' html_element = etree.HTML(html) print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
解析html文件
使用“lxml.etree.parse( )”进行解析,该方法默认使用的是“XML”解析器。
from lxml import etree html_element = etree.parse('./demo.html') print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
如果碰到不规范的html文件时就会解析错误,报错代码如下:

这个时候就要自己创建html解析器,增加参数‘parser',示例如下
from lxml import etree parser = etree.HTMLParser(encoding="utf-8") html_element = etree.parse('./demo.html', parser=parser) print(etree.tostring(html_element, encoding='utf-8').decode('utf-8'))
数据提取
在上面完成了数据的解析,下面就要开始主要的内容取数据了。再开始之前,给大家推荐一个Chrome的一个插件:XPath Helper,可以到谷歌商城中下载。这个在分析阶段能够很方便地去查找。
下面列一下最常使用的
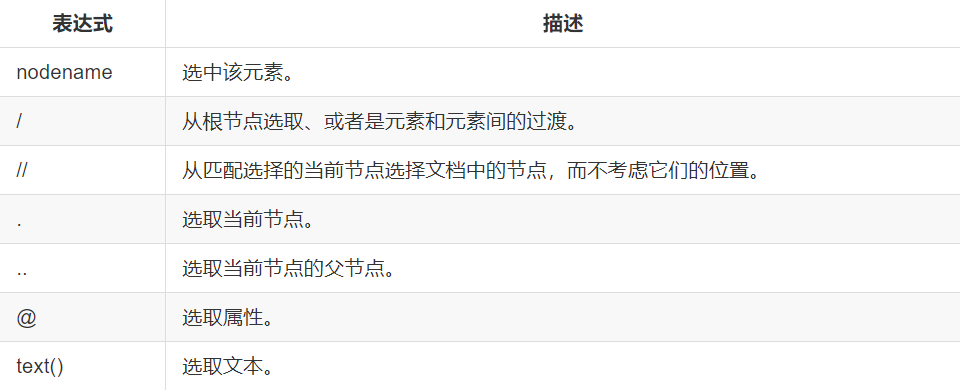
例子:

查找指定节点
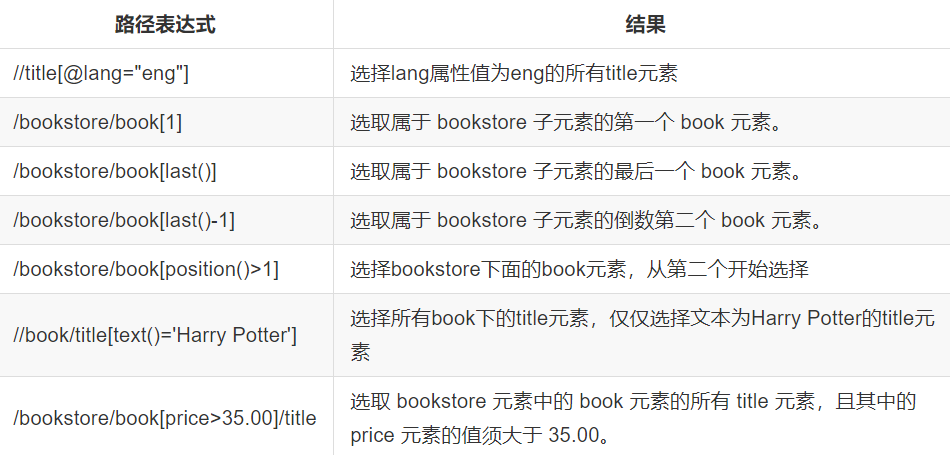
注意点: 在xpath中,第一个元素的位置是1,最后一个元素的位置是last(),倒数第二个是last()-1
选取未知节点
XPath 通配符可用来选取未知的 XML 元素。
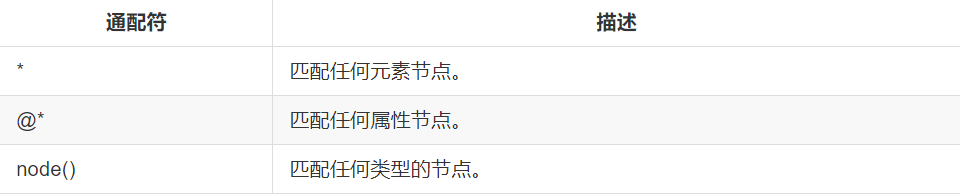
例如

选取若干条路径