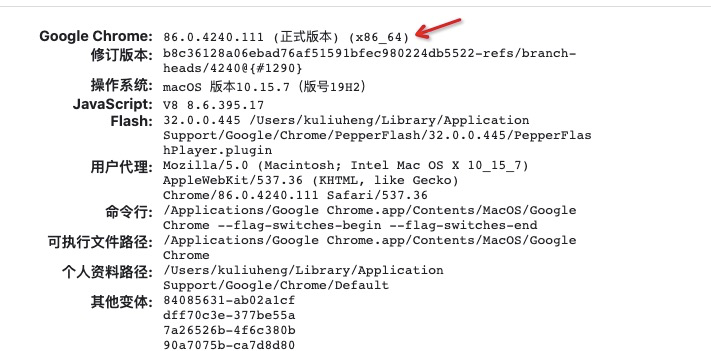
1. 查看Chrome版本
用Chrome打开地址:chrome://version/
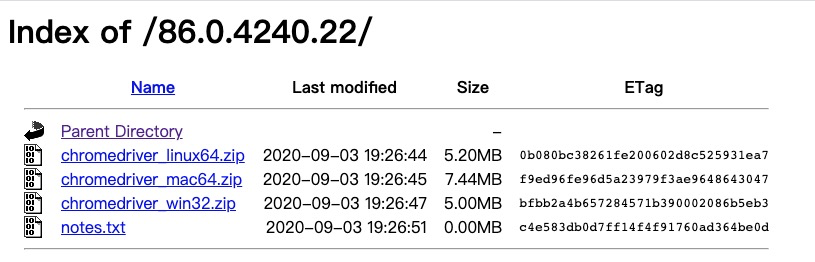
2. 打开ChromeDriver网站下载配套版本
http://chromedriver.storage.googleapis.com/index.html
3. 利用Python脚本驱动ChromeDriver遍历下载地址
脚本代码如下:
if __name__ == '__main__': CURRENT_PATH = os.path.split(os.path.realpath(__file__))[0] + os.sep + 'download' print(CURRENT_PATH) chrome_driver = '/Applications/Google Chrome.app/Contents/MacOS/chromedriver' target_url = 'http://bestor.auto.amap.com:14002/bestor_web/crashLog/show?downloadFlag=true&url=/bestor/data/save_log/4.5.0.600444/20200419000000000/dump_4.5.0.600444_57bc4576cb757b5cb15a3546899cc44c_20200421221956248_73593.zip' from selenium import webdriver from selenium.webdriver.chrome.options import Options from time import sleep option = Options() option.add_experimental_option("prefs", { "download.default_directory": CURRENT_PATH, # 默认下载路径 "profile.default_content_settings.popups": 1, # 设置为0禁止弹出窗口 # "profile.managed_default_content_settings.images": 2 #不加载图片的情况下,可以提升速度 }) option.add_argument("--window-size=1280,800") # 窗口大小 # 静默执行 # option.add_argument("--headless") option.add_experimental_option("excludeSwitches", ["enable-automation"]) option.add_experimental_option('useAutomationExtension', False) driver = webdriver.Chrome(executable_path=chrome_driver, options=option) login = False for url in url_set: # 已经准备好了的url列表 driver.get(url) print('DOWNLOAD: %s' % url) if not login: # 首次访问要有个身份验证的过程时间长一点 sleep(20)
login = True else: sleep(2) print('All done !') driver.quit()