1.sys模块
import sys
command=sys.argv #他会把你运行python文件的时候传入额参数,都放到这个argv里边,是一个list
if len(command)>1:
print('用例已经运行完成')
else:
print('运行这个python的时候,需要传入一个用例名称,例如:'
'python run_case.py case.xls')
在Terminal执行:python python文件名.py 命令
模块导入:
导入模块的顺序:
1.先去当前目录找这个python文件
2.当前目录没找到,就去python的环境变量去找这个python文件
print(sys.path)获取python环境目录
导入模块的实质:
把这个导入的模块的代码,从头到尾执行一次
name= 'haha'
def coon_db(name):
print('this is a func..',name)
现有a,b两个文件,以下是b文件的写入内容,然后在a导入
print('__name__',__name__)
if __name__ == '__main__':如果在当前文件,条件就为真,如果在其他文件,条件就为假
coon_db('b文件') #测试代码
#在其他python文件导入一个模块,它不会执行
#if __name__ == '__main__'下面的代码
#1、运行b文件,看看__name__的值,值为__main__
#2、运行a,文件,看看b文件的__name__打印的是啥 ,值为b
sys.path.append(r'E:xxxxxx')
#加入到环境变量里面,只对当次运行有效,下次要用的话还需要用代码添加
2.mongodb操作
import pymongo
client=pymongo.MongoClient(host='***.***.***.***',port=27017)
db=client['spz']#选择数据库,如果数据库不存在,会帮你创建
db['stu_info'].insert({'name':'jc','sex':'男'})传入一个字典,插入数据
# for d in db['stu_info'].find(): 查找数据,find里没有数据时,查找所有
# print(d)
collection=db['stu_info']#选择一个集合,就相当于mysql里的表
collection.delete_one({'name':'jc'})#如果有多条的话,只会帮你删一条
# collection.delete_many()#删除多条,需要传参数
# print(list(collection.find()))
# collection.update({'jd':'www.jd.com'},{'jc':'www.jd.com','addr':'亦庄'}) 修改数据,样式:把谁更新成什么
3.接口开发
mock服务,模拟一个服务
import flask
server=flask.Flask(__name__)#把当前这个python文件当做一个服务,固定写法
@server.route('/register',methods=['post'])装置器,在方法的上边添加,将方法定义成一个接口
def reg():
username=flask.request.values.get('username') 获取到请求参数,其中括号里边的值,就是在调用接口时传入的,即请求的key值
passwd = flask.request.values.get('passwd')
cpasswd = flask.request.values.get('cpasswd')
if username and passwd and cpasswd:
if passwd==cpasswd:
sql1="select * from nhy where name='%s';"%username
sql_res=my_db(sql1)
if sql_res:
res={'msg':'注册失败'}
else:
passwd=myMd5(passwd)
sql="insert into nhy (name,pwd) VALUE ('%s','%s');"%(username,passwd)
my_db(sql)
res={'msg':'注册成功'}
else:
{'msg': '两次密码不一致'}
else:
{'msg': '用户名和密码不能为空'}
return json.dumps(res, ensure_ascii=False)
server.run(debug=True)#启动服务,默认5000端口,可以加port=来修改端口,相同端口号的服务不能同时启动,加了debug=True,在修改接口后就可以不用重启服务了,可以自动重启
其他获取参数的方法:
json_data=flask.request.json.get('username') #这个获取入参是josn的
flask.request.cookies.get()#获取cookie
flask.request.headers.get()#获取header
4.程序分目录
当程序内容较多时,可以使用分目录的形式,以下就是一个程序的简单目录分级:
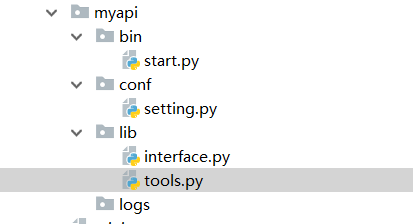
其中mypai是我的主目录,bin-start.py中放入的是我启动的主入口,conf-setting放入的是程序中所有的配置信息,lib-interface中放入的是我实现的一些方法,lib-tools放入的是一些工具类的方法,logs文件夹,则放入一些产生的日志文件,当然程序的目录不仅仅限于这些
那么这些目录之间的文件是怎么相互引用的呢:

右键根目录,选择截图中的选项,就可以实现本文件夹内所有文件的相互引用,引用示例如下:
from lib.tools import my_db,my_md5(from 文件夹.文件 import 方法) 引用过来的方法可以直接拿来用my_db(....)
from conf.setting import MYSQL_INFO 如果引用过来的是配置文件里的数据,可以用(**配置)引入配置参数,如(**MYSQL_INFO)这里用2个星号,就会把字典里边的k和v变成k=v的形式
如果,这个文件夹的程序在其他用户机器上运行,可能出现导入不成功的情况,那是因为其他人存放此文件夹的路径可能和你不一样,用以下方法,可以得到解决,即将当前用户主文件夹的目录添加到python的环境变量当中去,方法作用同上,建议用以下方法:
# print(__file__)#不管什么时候,__file__都是当前这个python文件的绝对路径
base_path=os.path.dirname(os.path.dirname(os.path.abspath(__file__)))
sys.path.insert(0,base_path)
#这里是加入环境变量的
#用abspath是因为分隔符不正确
5.压缩和解压文件
压缩:
import zipfile,os
def make_zip(source_dir, output_filename):
zipf = zipfile.ZipFile(output_filename, 'w') #指定压缩包的名称,以及压缩形式,r表示读已经存在的zip文件,w表示新建或者覆盖已经存在的zip文件,a表示对现在已有zip文件进行追加文件压缩
pre_len = len(os.path.dirname(source_dir)) #获取当前路径父目录的总长度
for parent, dirnames, filenames in os.walk(source_dir): #遍历所有文件,获得路径以及所有文件
for filename in filenames:
pathfile = os.path.join(parent, filename) #拼接每个文件的路径
arcname = pathfile[pre_len:].strip(os.path.sep) #取当前路径指定文件夹以及文件夹下包含的每个层级文件
zipf.write(pathfile,arcname) #传入打入压缩包的每个文件的路径,以及添加到zip文档之后保存的名称
zipf.close() #关闭打包状态,也可以用with zipfile.ZipFile() as zipf: 的写法,同读写文件,此时可以不写关闭
解压:
import zipfile
zipf = zipfile.ZipFile('test.zip') 默认为r状态
zipf.extractall('channel1')#将所有文件解压到channel1目录下