作者:Cilium 母公司 Isovalent 团队
译者:范彬,狄卫华,米开朗基杨注:本文已取得作者本人的翻译授权!
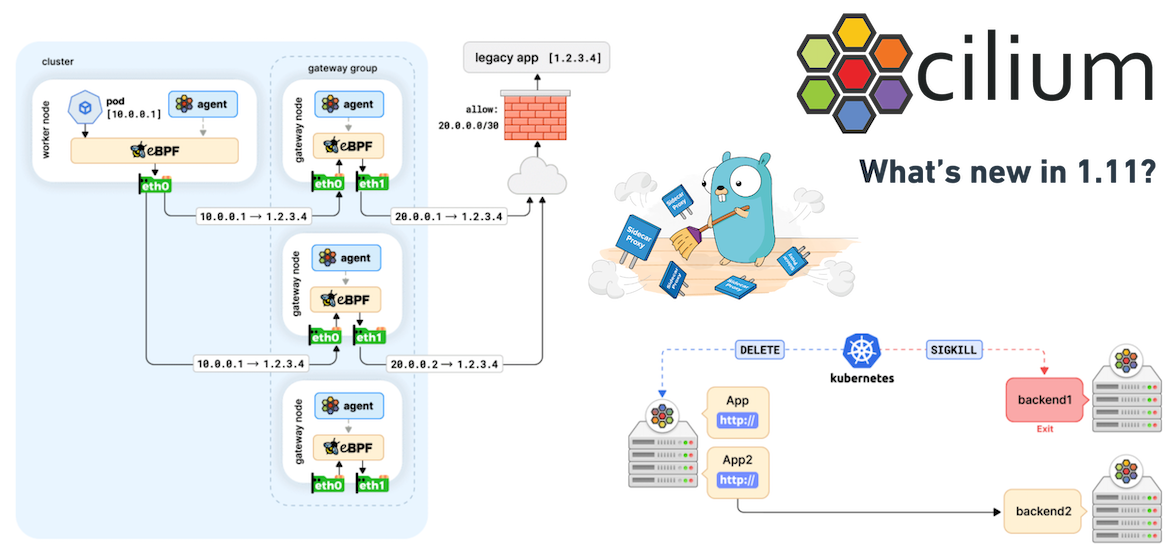
Cilium 项目已逐渐成为万众瞩目之星,我们很自豪能够成为该项目的核心人员。几天前,我们发布了具有诸多新功能的 Cilium 1.11 版本,这是一个令人兴奋的版本。诸多新功能中也包括了万众期待的 Cilium Service Mesh 的 Beta 版本。在本篇文章中,我们将深入探讨其中的部分新功能。
Service Mesh 测试版本(Beta)
在探讨 1.11 版本之前,让我们先了解一下 Cilium 社区宣布的 Service Mesh 的新功能。

- 基于 eBPF 技术的 Service Mesh (Beta)版本: 定义了新的服务网格能力,这包括 L7 流量管理和负载均衡、TLS 终止、金丝雀发布、追踪等诸多能力。
- 集成了 Kubernetes Ingress (Beta) 功能: 通过将 eBPF 和 Envoy 的强势联合,实现了对 Kubernetes Ingress 的支持。
Cilium 网站的一篇文章详细介绍了Service Mesh Beta 版本,其中也包括了如何参与到该功能的开发。当前,这些 Beta 功能是 Cilium 项目中的一部分,在单独分支进行开发,可独立进行测试、反馈和修改,我们期待在 2022 年初 Cilium 1.12 版本发布之前合入到 Cilium 主分支。
Cilium 1.11
Cilium 1.11 版本包括了 Kubernetes 额外功能,及独立部署的负载均衡器。
- OpenTelemetry 支持:Hubble L3-L7 可观测性数据支持 OpenTelemetry 跟踪和度量(Metrics)格式的导出。 (更多详情)
- Kubernetes APIServer 策略匹配:新的策略实体用于简单方便地创建进出 Kubernetes API Server 流量的策略模型。 (更多详情)
- 拓扑感知的路由:增强负载均衡能力,基于拓扑感知将流量路由到最近的端点,或保持在同一个地区(Region)内。 (更多详情)
- BGP 宣告 Pod CIDR:使用 BGP 在网络中宣告 Pod CIDR 的 IP 路由。(更多详情)
- 服务后端流量的优雅终止:支持优雅的连接终止,通过负载均衡向终止的 Pod 发送的流量可以正常处理后终止。(更多详情)
- 主机防火墙稳定版:主机防火墙功能已升级为生产可用的稳定版本。(更多详情)
- 提高负载均衡器扩展性:Cilium 负载均衡支持超过 64K 的后端端点。(更多详情)
- 提高负载均衡器设备支持:负载均衡的加速 XDP 快速路径现在支持 bond 设备(更多详情) 同时,可更普遍地用于多设备设置。 (更多详情)。
- Kube-Proxy-replacement 支持 istio:Cilium 的 kube-proxy 替代模式与 Istio sidecar 部署模式兼容。 (更多详情)
- Egress 出口网关的优化:Egress 网关能力增强,支持其他数据路径模式。 (更多详情)
- 托管 IPv4/IPv6 邻居发现:对 Linux 内核和 Cilium 负载均衡器进行了扩展,删除了其内部 ARP 库,将 IPv4 的下一跳发现以及现在的 IPv6 节点委托给内核管理。 (更多详情)
- 基于路由的设备检测:外部网络设备基于路由的自动检测,以提高 Cilium 多设备设置的用户体验。 (更多详情)
- Kubernetes Cgroup 增强:在 cgroup v2 模式下集成了 Cilium 的 kube-proxy-replacement 功能,同时,对 cgroup v1/v2 混合模式下的 Linux 内核进行了增强。 (更多详情)
- Cilium Endpoint Slices:Cilium 基于 CRD 模式能够更加高效地与 Kubernetes 的控制平面交互,并且不需要专有 ETCD 实例,节点也可扩展到 1000+。 (更多详情)
- 集成 Mirantis Kubernetes 引擎:支持 Mirantis Kubernetes 引擎。 (更多详情)
什么是 Cilium ?
Cilium 是一个开源软件,为基于 Kubernetes 的 Linux 容器管理平台上部署的服务,透明地提供服务间的网络和 API 连接及安全。
Cilium 底层是基于 Linux 内核的新技术 eBPF,可以在 Linux 系统中动态注入强大的安全性、可见性和网络控制逻辑。 Cilium 基于 eBPF 提供了多集群路由、替代 kube-proxy 实现负载均衡、透明加密以及网络和服务安全等诸多功能。除了提供传统的网络安全之外,eBPF 的灵活性还支持应用协议和 DNS 请求/响应安全。同时,Cilium 与 Envoy 紧密集成,提供了基于 Go 的扩展框架。因为 eBPF 运行在 Linux 内核中,所以应用所有 Cilium 功能,无需对应用程序代码或容器配置进行任何更改。
请参阅 [Cilium 简介] 部分,了解 Cilium 更详细的介绍。
OpenTelemetry 支持
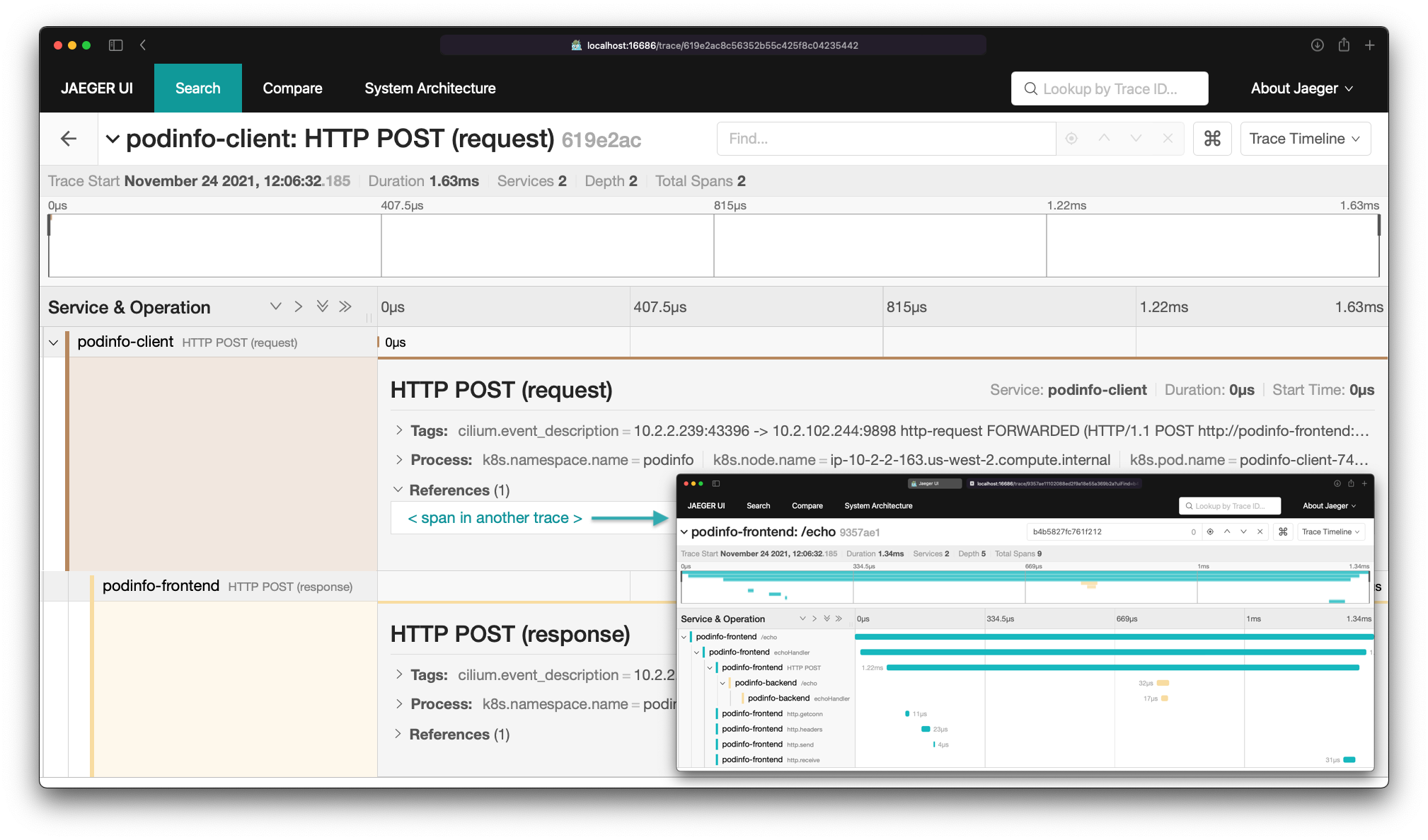
新版本增加了对 OpenTelemetry 的支持。
OpenTelemetry 是一个 CNCF 项目,定义了遥测协议和数据格式,涵盖了分布式跟踪、指标和日志。该项目提供了 SDK 和运行在 Kubernetes 上的收集器。通常,应用程序直接检测暴露 OpenTelemetry 数据,这种检测最常使用 OpenTelemetry SDK 在应用程序内实现。OpenTelemetry 收集器用于从集群中的各种应用程序收集数据,并将其发送到一个或多个后端。CNCF 项目 Jaeger 是可用于存储和呈现跟踪数据的后端之一。
支持 OpenTelemetry 的 Hubble 适配器是一个附加组件,可以部署到运行 Cilium 的集群上(Cilium 版本最好是 1.11,当然也应该适用于旧版本)。该适配器是一个嵌入了 Hubble 接收器的 OpenTelemetry 收集器,我们推荐使用 OpenTelemetry Operator 进行部署(详见用户指南)。Hubble 适配器从 Hubble 读取流量数据,并将其转换为跟踪和日志数据。
Hubble 适配器添加到支持 OpenTelemetry 的集群中,可对网络事件和应用级别遥测提供有价值的可观测性。当前版本通过 OpenTelemetry SDK 提供了 HTTP 流量和 spans 的关联。
感知拓扑的负载均衡
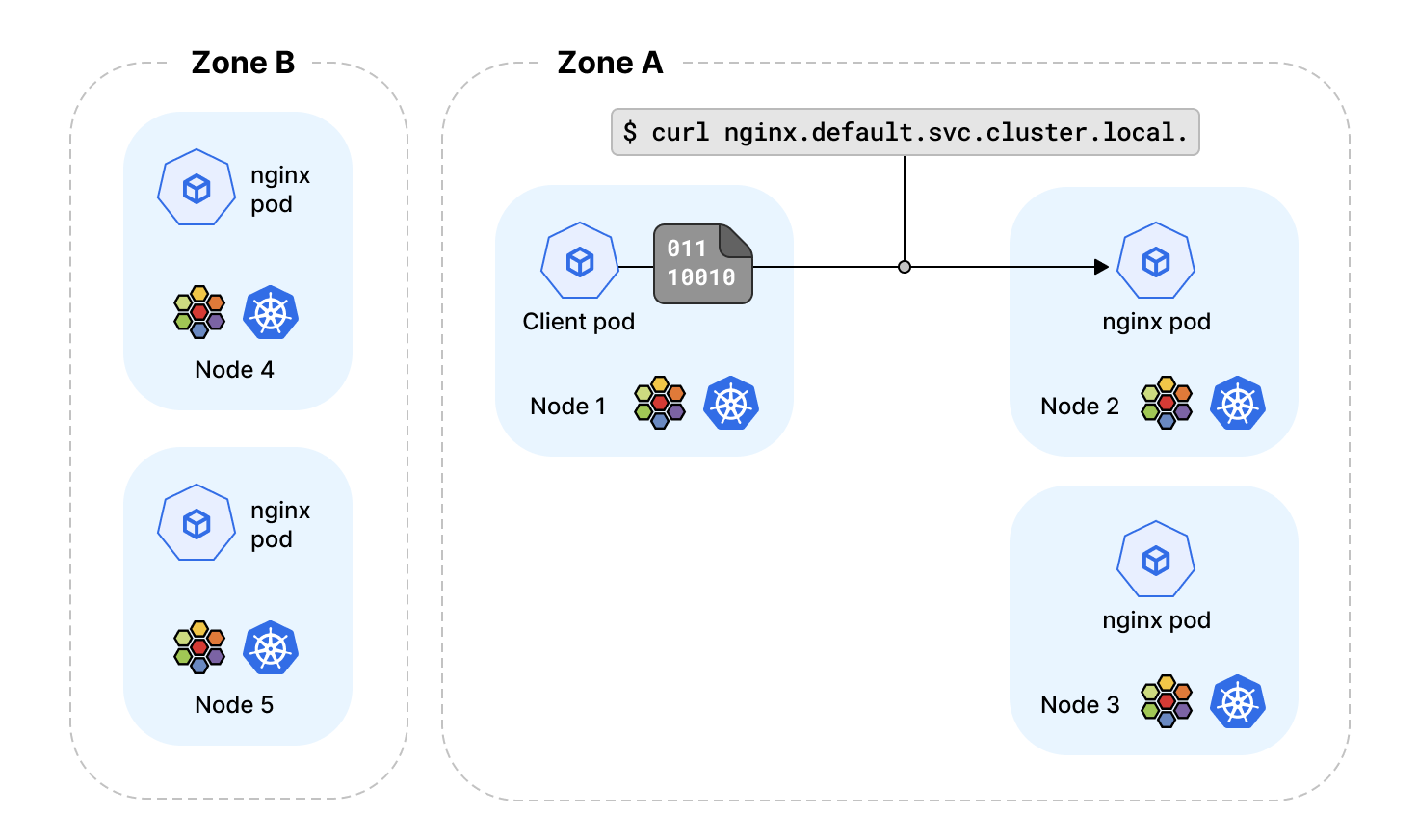
Kubernetes 集群在跨多数据中心或可用区部署是很常见的。这不仅带来了高可用性好处,而且也带来了一些操作上的复杂性。
目前为止,Kubernetes 还没有一个内置的结构,可以基于拓扑级别描述 Kubernetes service 端点的位置。这意味着,Kubernetes 节点基于服务负载均衡决策选择的 service 端点,可能与请求服务的客户在不同的可用区。 这种场景下会带来诸多副作用,可能是云服务费用增加,通常由于流量跨越多个可用区,云提供商会额外收取费用,或请求延迟增加。更广泛地说,我们需要根据拓扑结构定义 service 端点的位置, 例如,服务流量应该在同一节点(node)、同一机架(rack)、同一故障分区(zone)、同一故障地区(region)、同云提供商的端点之间进行负载均衡。
Kubernetes v1.21 引入了一个称为拓扑感知路由的功能来解决这个限制。通过将 service.kubernetes.io/topology-aware-hints 注解被设置为 auto ,在 service 的 EndpointSlice 对象中设置端点提示,提示端点运行的分区。分区名从节点的 topology.kubernetes.io/zone 标签获取。 如果两个节点的分区标签值相同,则被认为处于同一拓扑级别。
该提示会被 Cilium 的 kube-proxy 替代来处理,并会根据 EndpointSlice 控制器设置的提示来过滤路由的端点,让负载均衡器优先选择同一分区的端点。
该 Kubernetes 功能目前处于 Alpha 阶段,因此需要使用--feature-gate 启用。更多信息请参考官方文档。
Kubernetes APIServer 策略匹配
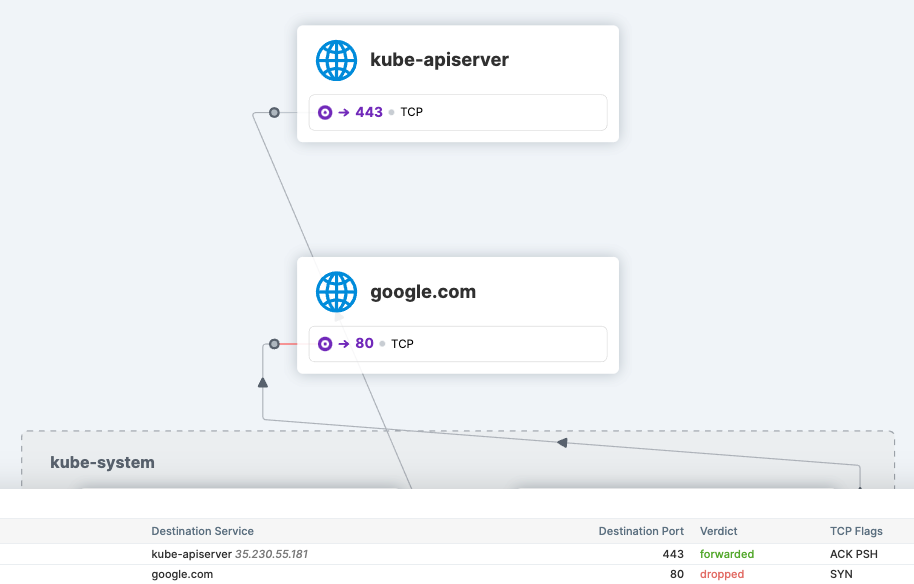
托管 Kubernetes 环境,如 GKE、EKS 和 AKS 上,kube-apiserver 的 IP 地址是不透明的。在以前的 Cilium 版本中,没有提供正规的方式来编写 Cilium 网络策略,定义对 kube-apiserver 的访问控制。这涉及一些实现细节,如:Cilium 安全身份分配,kube-apiserver 是部署在集群内,还是部署在集群外。
为了解决这个问题,Cilium 1.11 增加了新功能,为用户提供一种方法,允许使用专用策略对象定义进出 apiserver 流量的访问控制。该功能的底层是实体选择器,能够解析预留的 kube-apiserver 标签含义, 并可自动应用在与 kube-apiserver 关联的 IP 地址上。
安全团队将对这个新功能特别感兴趣,因为它提供了一个简单的方法来定义对 pod 的 Cilium 网络策略,允许或禁止访问 kube-apiserver。下面 CiliumNetworkPolicy 策略片段定义了 kube-system 命名空间内的所有 Cilium 端点允许访问 kube-apiserver, 除此之外的所有 Cilium 端点禁止访问 kube-apiserver。
apiVersion: cilium.io/v2
kind: CiliumNetworkPolicy
metadata:
name: allow-to-apiserver
namespace: kube-system
spec:
endpointSelector: {}
egress:
- toEntities:
- kube-apiserver
BGP 宣告 Pod CIDR
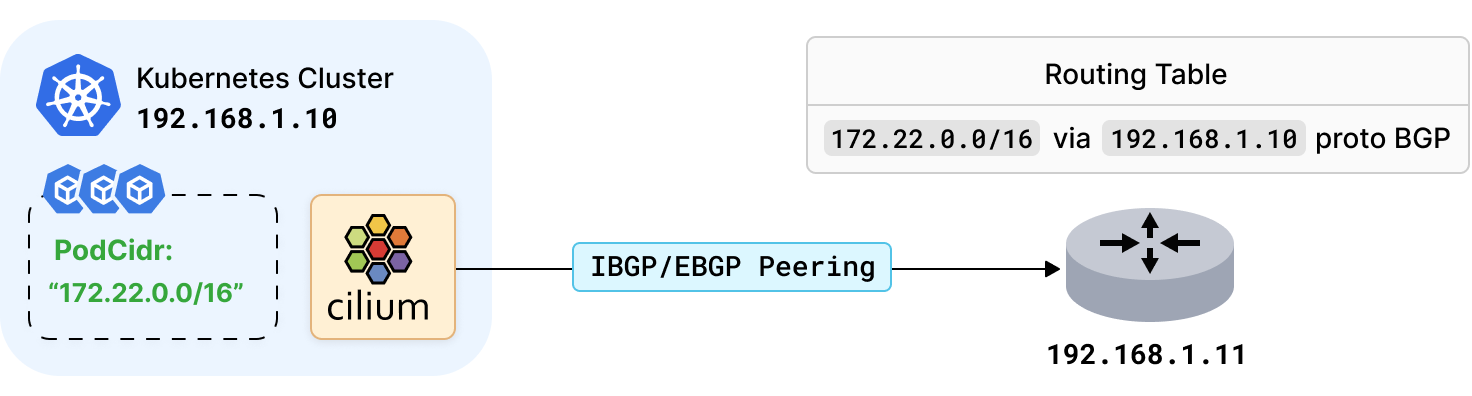
随着私有 Kubernetes 环境的日益关注,我们希望与现存的数据中心网络基础设施很好地集成,它们通常是基于 BGP 协议进行路由分发的。 在上一个版本中,Cilium agent 已经开始集成了 BGP 协议, 可以通过 BGP 向 BGP 路由器发布负载均衡器的 service 的 VIP。
现在,Cilium 1.11 版本还引入了通过 BGP 宣告 Kubernetes Pod 子网的能力。Cilium 可与任何下游互联的 BGP 基础设施创建一个 BGP 对等体,并通告分配的 Pod IP 地址的子网。这样下游基础设施就可以按照合适方式来分发这些路由,以使数据中心能够通过各种私有/公共下一跳路由到 Pod 子网。
要开始使用此功能,运行 Cilium 的 Kubernetes 节点需要读取 BGP 的 ConfigMap 设置:
apiVersion: v1
kind: ConfigMap
metadata:
name: bgp-config
namespace: kube-system
data:
config.yaml: |
peers:
- peer-address: 192.168.1.11
peer-asn: 64512
my-asn: 64512
同时,Cilium 应该使用以下参数进行安装 :
$ cilium install \
--config="bgp-announce-pod-cidr=true"
Cilium 安装完后,它将会向 BGP 路由器发布 Pod CIDR 范围,即 192.168.1.11。
下面是最近的 Cilium eCHO episode 完整演示视频。
如果想了解更多,如:如何为 Kubernetes service 配置 LoadBalancer IP 宣告,如何通过 BGP 发布节点的 Pod CIDR 范围,请参见 docs.cilium.io。
托管 IPv4/IPv6 邻居发现
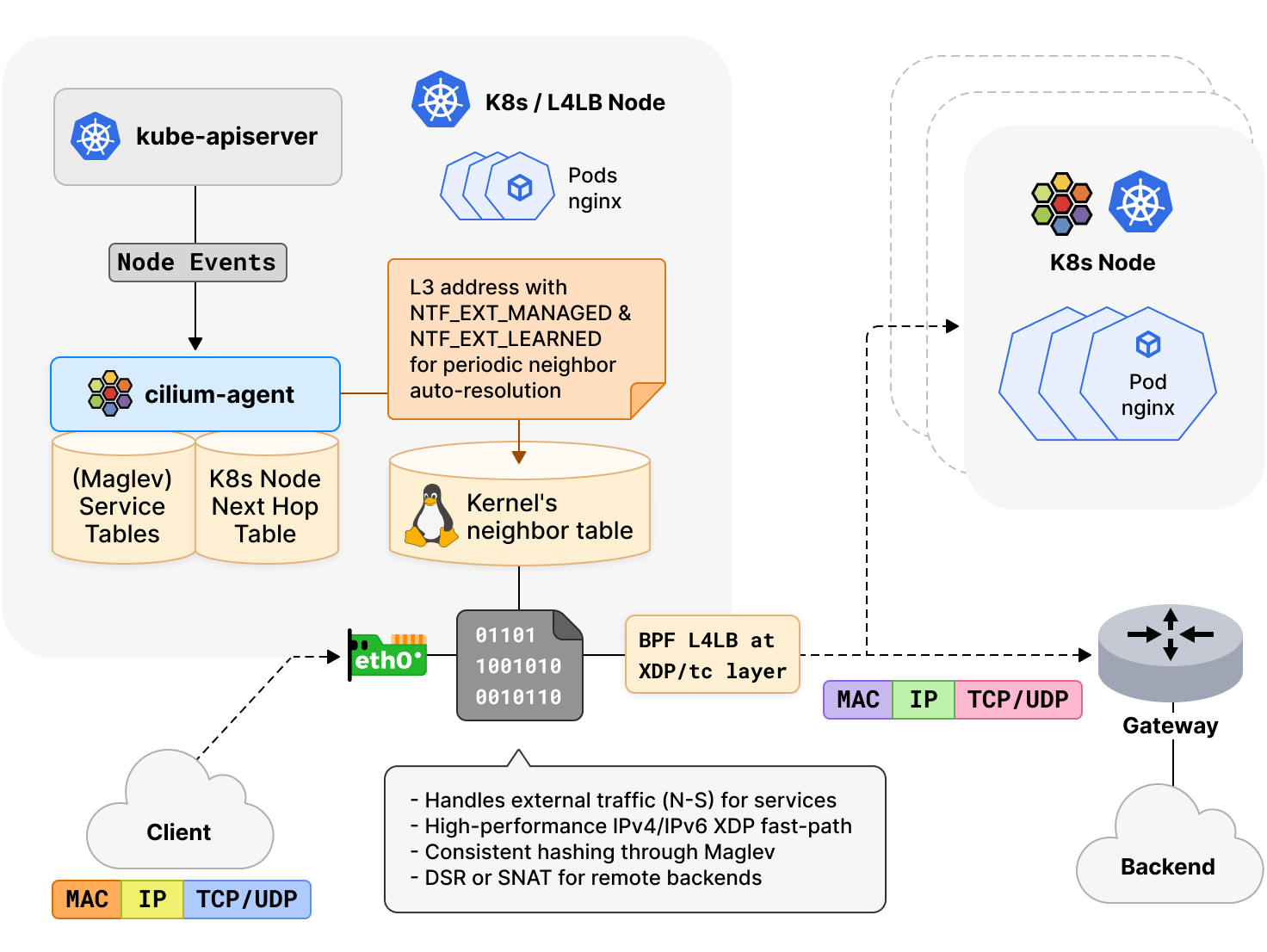
当 Cilium 启用 eBPF 替代 kube-proxy 时,Cilium 会执行集群节点的邻居发现,以收集网络中直接邻居或下一跳的 L2 地址。这是服务负载平衡所必需的,eXpress Data Path (XDP) 快速路径支持每秒数百万数据包的可靠高流量速率。在这种模式下,在技术上按需动态解析是不可能的,因为它需要等待相邻的后端被解析。
在 Cilium 1.10 及更早版本中,cilium agent 本身包含一个 ARP 解析库,其控制器触发发现和定期刷新新增集群节点。手动解析的邻居条目被推送到内核并刷新为 PERMANENT 条目,eBPF 负载均衡器检索这些条目,将流量定向到后端。cilium agent 的 ARP 解析库缺乏对 IPv6 邻居解析支持,并且,PERMANENT 邻居条目还有许多问题:举个例子,条目可能变得陈旧,内核拒绝学习地址更新,因为它们本质上是静态的,在某些情况下导致数据包在节点间被丢弃。此外,将邻居解析紧密耦合到 cilium agent 也有一个缺点,在 agent 启停周期时,不会发生地址更新的学习。
在 Cilium 1.11 中,邻居发现功能已被完全重新设计,Cilium 内部的 ARP 解析库已从 agent 中完全移除。现在 agent 依赖于 Linux 内核来发现下一跳或同一 L2 域中的主机。Cilium 现在可同时支持 IPv4 和 IPv6 邻居发现。对于 v5.16 或更新的内核,我们已经将今年 Linux Plumbers 会议期间共同组织的 BPF & Networking Summit 上,提出的“管理”邻居条目工作提交到上游(part1, part2, part3)。在这种情况下,agent 将新增集群节点的 L3 地址下推,并触发内核定期自动解析它们对应的 L2 地址。
这些邻居条目作为“外部学习”和“管理”邻居属性,基于 netlink 被推送到内核中。虽然旧属性确保在压力下这些邻居条目不会被内核的垃圾收集器处理,但是 "管理" 邻居属性会,在可行的情况下,内核需要自动将这些邻居属性保持在 REACHABLE 状态。这意思是,如果节点的上层堆栈没有主动向后端节点发送或接收流量,内核可以重新学习,将邻居属性保持在 REACHABLE 状态,然后通过内部内核工作队列定期触发显式邻居解析。对于没有 "管理" 邻居属性功能的旧内核,如果需要,agent controller 将定期督促内核触发新的解决方案。因此,Cilium 不再有 PERMANENT 邻居条目,并且在升级时,agent 将自动将旧条目迁移到动态邻居条目中,以使内核能够在其中学习地址更新。
此外,在多路径路由的情况下,agent 会做负载均衡,它现在可以在路由查找中查看失败的下一跳。这意味着,不是替代所有的路由,而是通过查看相邻子系统信息来避免失败的路径。总的来说,对于 Cilium agent 来说,这项修正工作显著促进了邻居管理,并且在网络中的节点或下一跳的邻居地址发生变化时,数据路径更易变化。
XDP 多设备负载均衡器
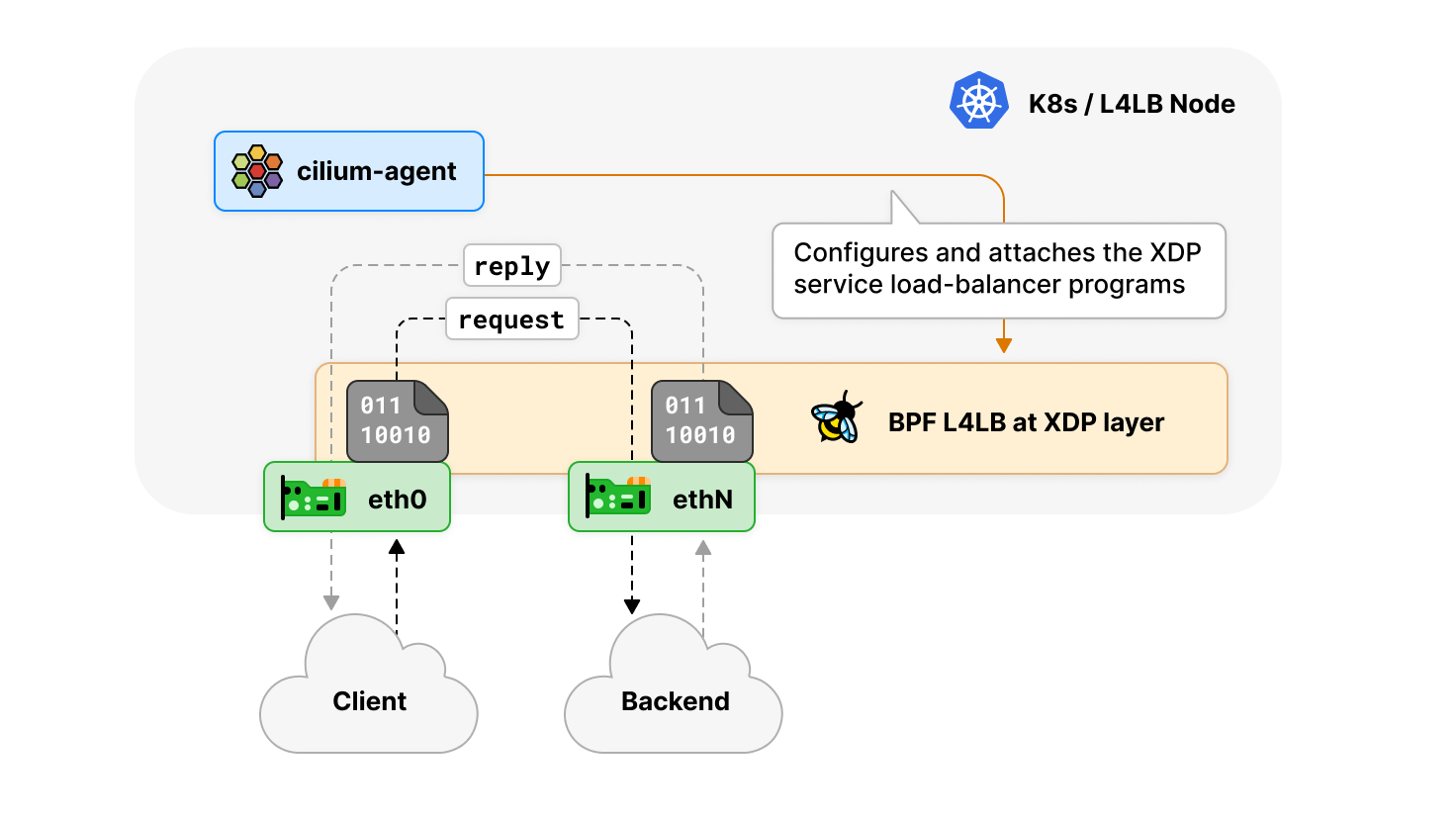
在此版本前,基于 XDP 的负载均衡器加速只能在单个网络设备上启用,以发夹方式(hair-pinning)运行,即数据包转发离开的设备与数据包到达的设备相同。这个最初的限制是在基于 XDP 层的 kube-proxy 替代加速中加入的,原因是在 XDP(XDP_REDIRECT)下对多设备转发的驱动支持有限,而同设备转发(XDP_TX)是 Linux 内核中每个驱动的 XDP 都支持的。
这意味着多网络设备的环境下,我们需要使用 tc eBPF 机制,所以必须使用 Cilium 的常规 kube-proxy 替代。这种环境的一个典型例子是有两个网络设备的主机,其中一个是公网,接受来自外部对 Kubernetes service 的请求,而另一个是私有网络,用于 Kubernetes 节点之间的集群内通信。
由于在现代 LTS Linux 内核上,绝大多数 40G 和 100G 以上的上游网卡驱动都支持开箱即用的 XDP_REDIRECT,这种限制终于可以解除,因此,这个版本在 Cilium 的 kube-proxy 替代,及 Cilium 的独立负载均衡器上,实现了 XDP 层的多网络设备的负载均衡,这使得在更复杂的环境中也能保持数据包处理性能。
XDP 透明支持 bond 设备

在很多企业内部或云环境中,节点通常使用 bond 设备,设置外部流量的双端口网卡。随着最近 Cilium 版本的优化,如在 XDP 层的 kube-proxy 替代 或独立负载均衡器,我们从用户那里经常收到的一个问题是 XDP 加速是否可以与 bond 网络设备结合使用。虽然 Linux 内核绝大多数 10/40/100Gbit/s 网络驱动程序支持 XDP,但它缺乏在 bond(和 802.3ad)模式下透明操作 XDP 的能力。
其中的一个选择是在用户空间实现 802.3ad,并在 XDP 程序实现 bond 负载均衡,但这对 bond 设备管理是一个相当颇为繁琐努力,例如:对 netlink 链路事件的观测,另外还需要为编排器的本地和 bond 分别提供单独的程序。相反,本地内核实现解决了这些问题,提供了更多的灵活性,并且能够处理 eBPF 程序,而不需要改变或重新编译它们。内核负责管理 bond 设备组,可以自动传播 eBPF 程序。对于 v5.15 或更新的内核,我们已经在上游(part1, part2)实现了 XDP 对 bond 设备的支持。
当 XDP 程序连接到 bond 设备时,XDP_TX 的语义等同于 tc eBPF 程序附加到 bond 设备,这意味着从 bond 设备传输数据包使用 bond 配置的传输方法来选择从属设备。故障转移和链路聚合模式均可以在 XDP 操作下使用。对于通过 XDP_TX 将数据包从 bond 设备上回传,我们实现了轮循、主动备份、802.3ad 以及哈希设备选择。这种情况对于像 Cilium 这样的发夹式负载均衡器来说特别有意义。
基于路由的设备检测
1.11 版本显著的提升了设备的自动检测,可用于 使用 eBPF 替代 kube-proxy、带宽管理器和主机防火墙。
在早期版本中,Cilium 自动检测的设备需要有默认路由的设备,和有 Kubernetes NodeIP 的设备。展望未来,现在设备检测是根据主机命名空间的所有路由表的条目来进行的。也就是说,所有非桥接的、非 bond 的和有全局单播路由的非虚拟的设备,现在都能被检测到。
通过这项改进,Cilium 现在应该能够在更复杂的网络设置中自动检测正确的设备,而无需使用 devices 选项手动指定设备。使用后一个选项时,无法对设备名称进行一致性的命名规范,例如:无法使用共同前缀正则表达式对设备命名。
服务后端流量的优雅终止
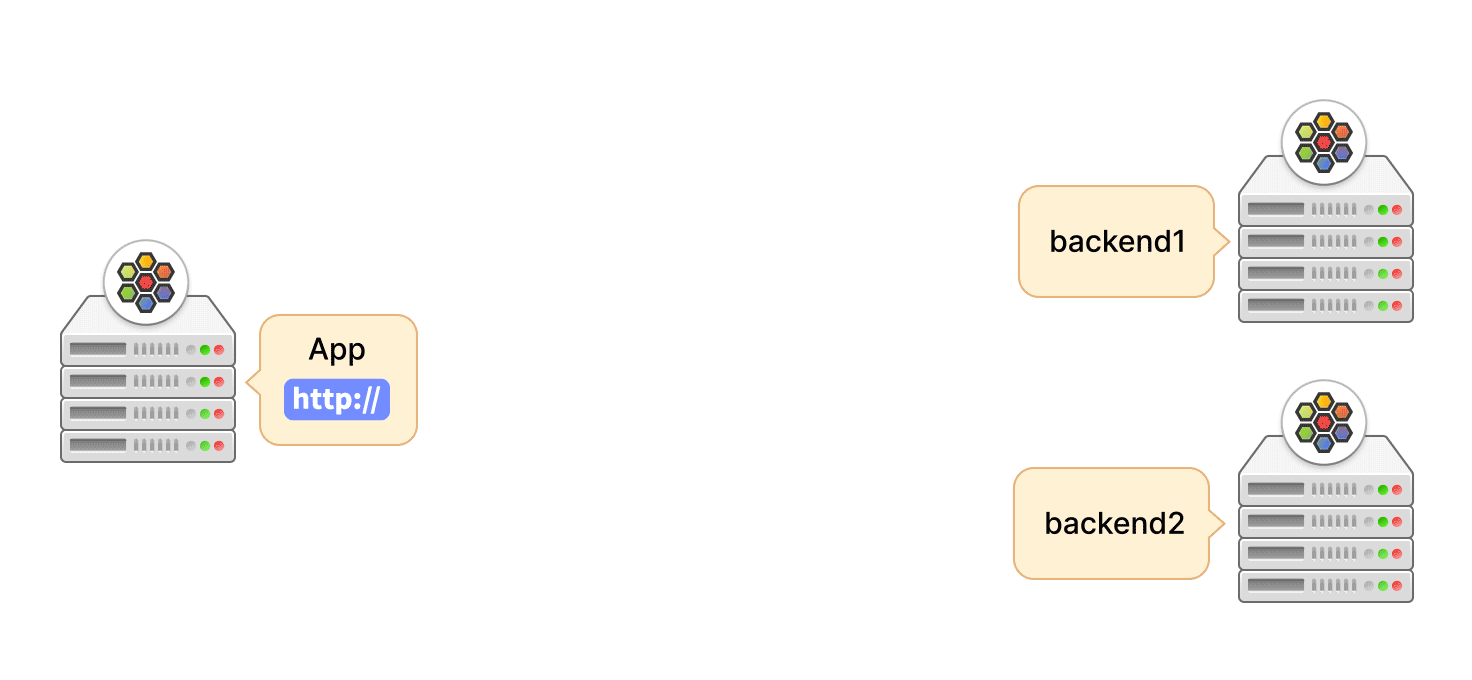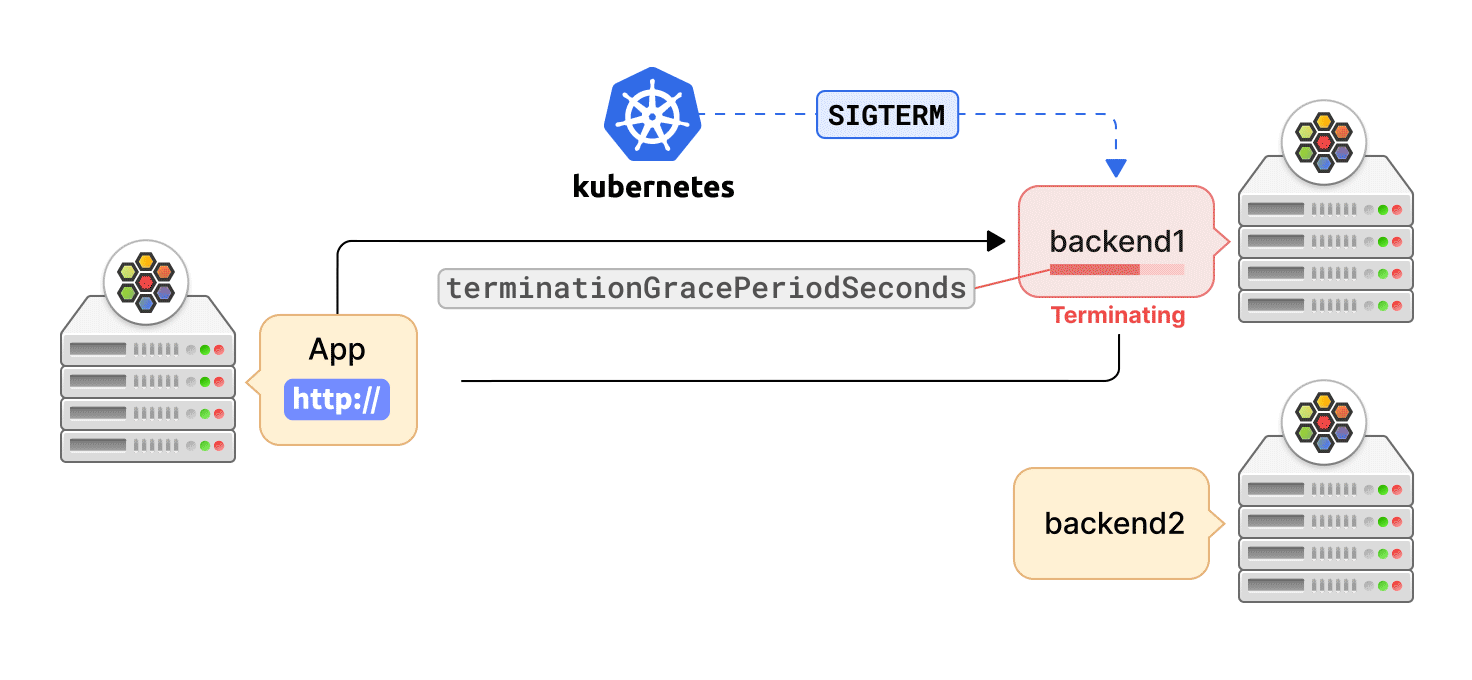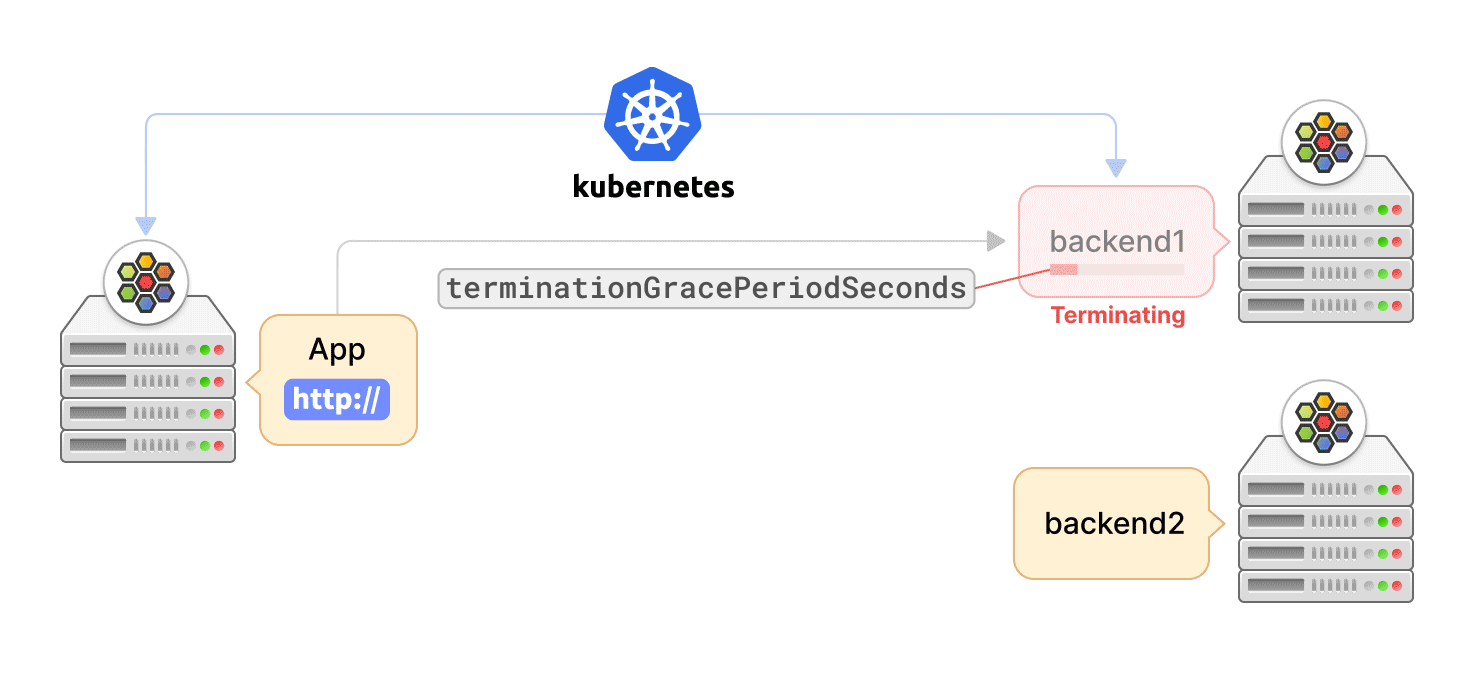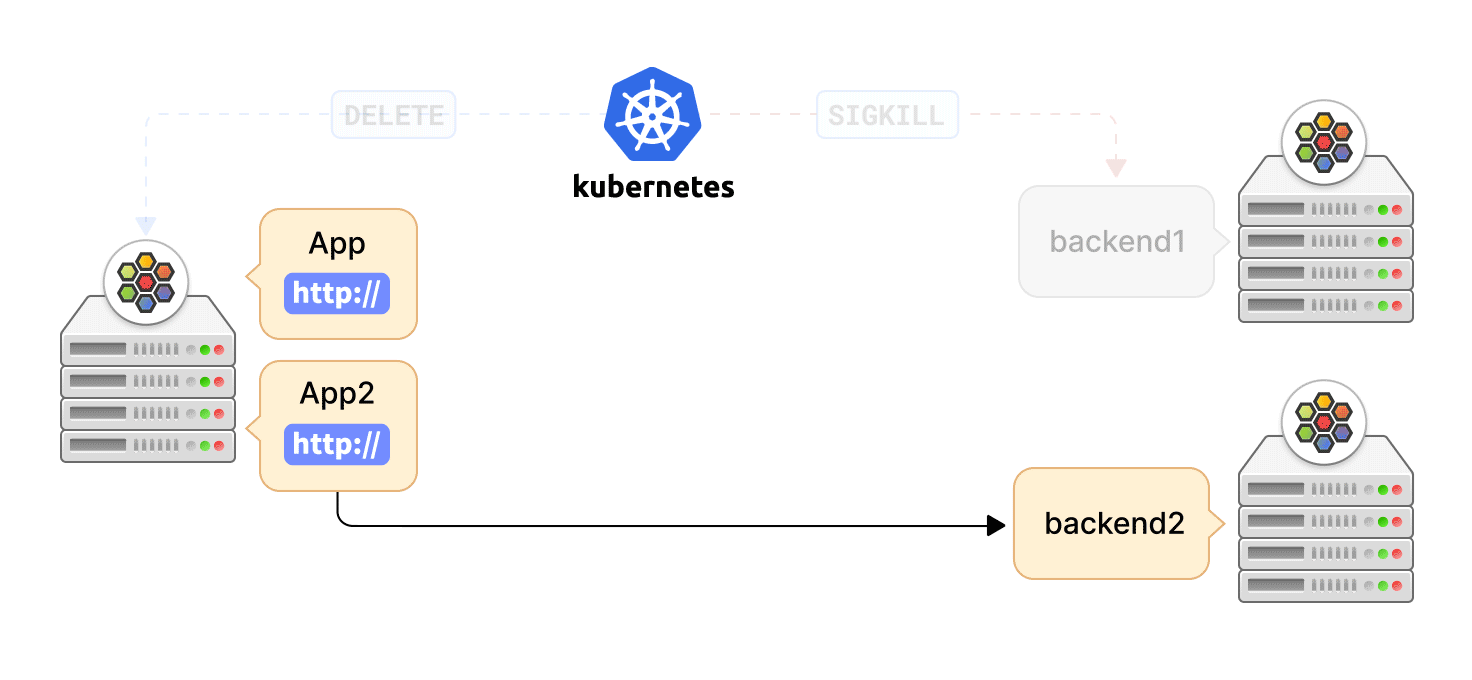
Kubernetes 可以出于多种原因终止 Pod,如滚动更新、缩容或用户发起的删除。在这种情况下,重要的是要优雅地终止与 Pod 的活跃连接,让应用程序有时间完成请求以最大程度地减少中断。异常连接终止会导致数据丢失,或延迟应用程序的恢复。
Cilium agent 通过 "EndpointSlice" API 监听 service 端点更新。当一个 service 端点被终止时,Kubernetes 为该端点设置 terminating 状态。然后,Cilium agent 删除该端点的数据路径状态,这样端点就不会被选择用于新的请求,但该端点正在服务的当前连接,可以在用户定义的宽限期内被终止。
同时,Kubernetes 告知容器运行时向服务的 Pod 容器发送 SIGTERM 信号,并等待终止宽限期的到来。然后,容器应用程序可以启动活跃连接的优雅终止,例如,关闭 TCP 套接字。一旦宽限期结束,Kubernetes 最终通过 SIGKILL 信号对仍在 Pod 容器中运行的进程触发强制关闭。这时,agent 也会收到端点的删除事件,然后完全删除端点的数据路径状态。但是,如果应用 Pod 在宽限期结束前退出,Kubernetes 将立即发送删除事件,而不管宽限期设置。
更多细节请关注 docs.cilium.io 中的指南。
Egress 出口网关的优化
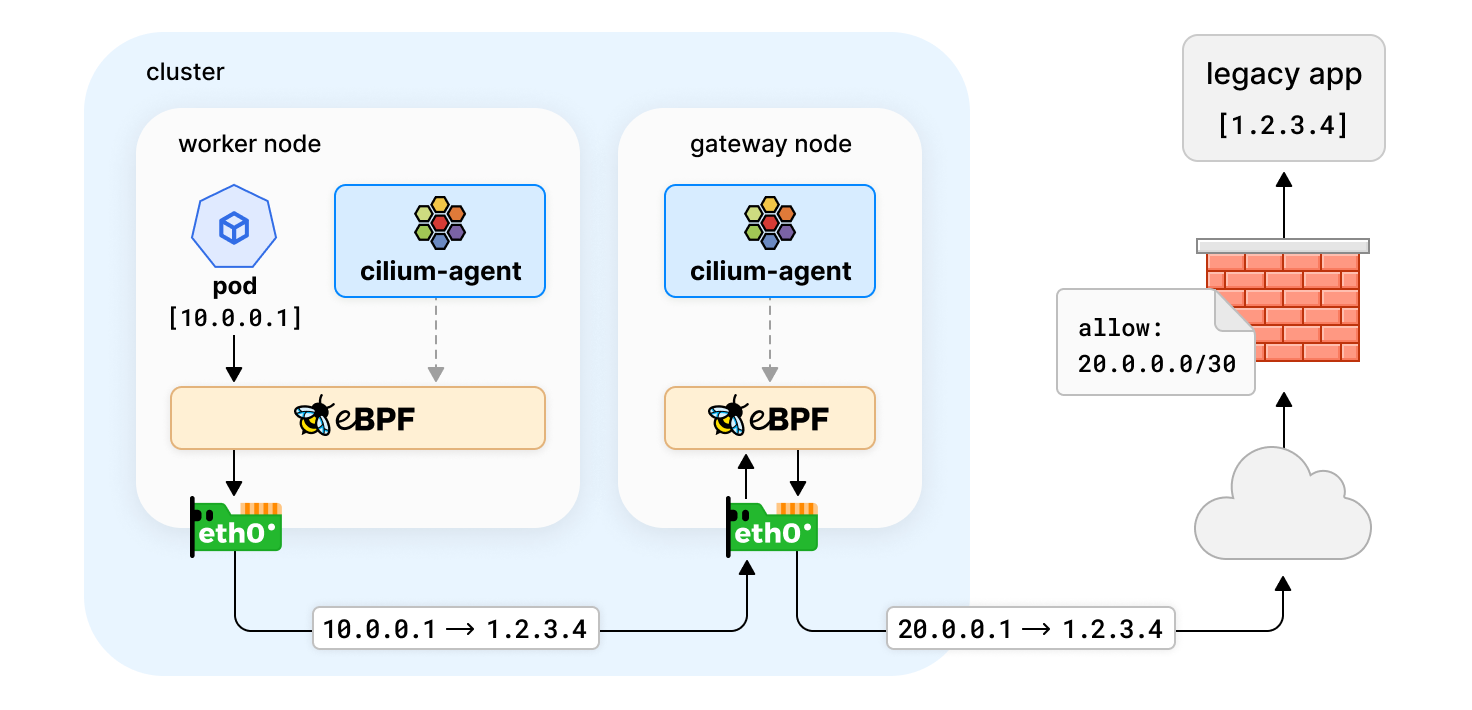
简单的场景中,Kubernetes 应用只与其他 Kubernetes 应用进行通信,因此流量可通过网络策略等机制进行控制。但现实世界情况并非总是如此,例如:私有部署的一些应用程序没有被容器化,Kubernetes 应用程序需要与集群外的服务进行通信。这些传统服务通常配置的是静态 IP,并受到防火墙规则的保护。那么在此种情况下,应该如何对流量控制和审计呢?
Egress 出口 IP 网关功能在 Cilium 1.10 中被引入,通过 Kubernetes 节点充当网关用于集群出口流量来解决这类问题。用户使用策略来指定哪些流量应该被转发到网关节点,以及如何转发流量。这种情况下,网关节点将使用静态出口 IP 对流量进行伪装,因此可以在传统防火墙建立规则。
apiVersion: cilium.io/v2alpha1
kind: CiliumEgressNATPolicy
metadata:
name: egress-sample
spec:
egress:
- podSelector:
matchLabels:
app: test-app
destinationCIDRs:
- 1.2.3.0/24
egressSourceIP: 20.0.0.1
在上面的示例策略中,带有 app: test-app 标签的 Pod 和目标 CIDR 为 1.2.3.0/24 的流量,需要通过 20.0.0.1 网关节点的出口 IP(SNAT)与集群外部通信。
在 Cilium 1.11 开发周期中,我们投入了大量精力来稳定出口网关功能,使其可投入生产。现在,
出口网关现在可以工作在直接路由,区分内部流量(即 Kubernetes 重叠地址的 CIDR 的出口策略)及在不同策略中使用相同出口 IP下。一些问题,如回复被错误描述为出口流量和其他等已经修复,同时测试也得到了改进,以便及早发现潜在的问题。
Kubernetes Cgroup 增强
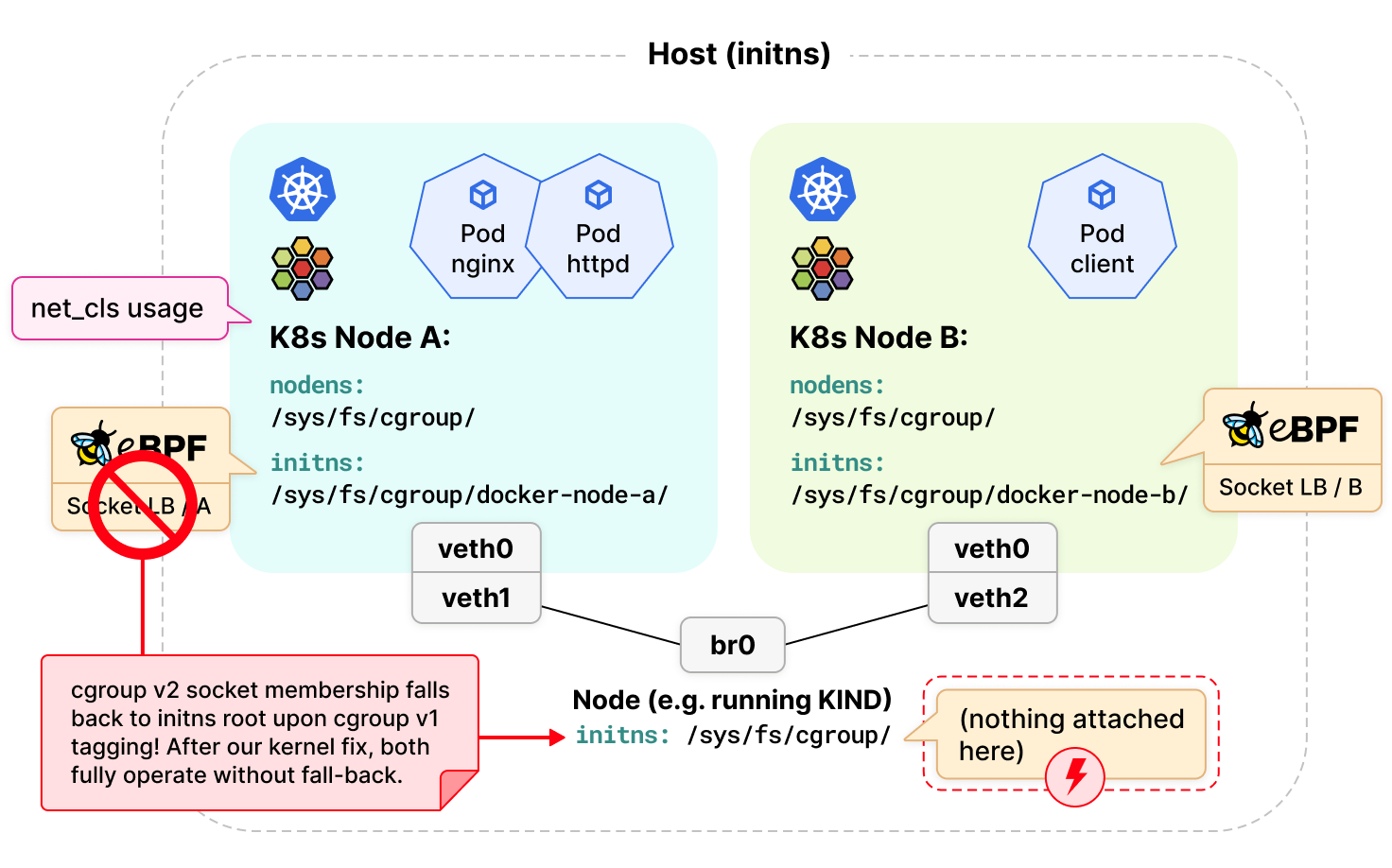
Cilium 使用 eBPF 替代 kube-proxy 作为独立负载均衡器的优势之一是能够将 eBPF 程序附加到 socket hooks 上,例如 connect(2)、bind(2)、sendmsg(2) 以及其他各种相关的系统调用,以便透明地将本地的应用程序连接到后端服务。但是这些程序只能被附加到 cgroup v2。虽然 Kubernetes 正在努力迁移到 cgroup v2,但目前绝大多数用户的环境都是 cgroup v1 和 v2 混合使用。
Linux 在内核的 socket 对象中标记了 socket 与 cgroup 的关系,并且由于 6 年前的一个设定,cgroup v1 和 v2 的 socket 标签是互斥的。这就意味着,如果一个 socket 是以 cgroup v2 成员身份创建的,但后来通过具有 cgroup v1 成员身份的 net_prio 或 net_cls 控制器进行了标记,那么 cgroup v2 就不会执行附加在 Pod 子路径上的程序,而是回退执行附加到 cgroup v2 层次结构 (hierarchy) 根部的 eBPF 程序。这样就会导致一个很严重的后果,如果连 cgroup v2 根部都没有附加程序,那么整个 cgroup v2 层次结构 (hierarchy) 都会被绕过。
现如今,cgroup v1 和 v2 不能并行运行的假设不再成立,具体可参考今年早些时候的 Linux Plumbers 会议演讲。只有在极少数情况下,当被标记为 cgroup v2 成员身份的 eBPF 程序附加到 cgroup v2 层次结构的子系统时,Kubernetes 集群中的 cgroup v1 网络控制器才会绕过该 eBPF 程序。为了在数据包处理路径上的尽量前面(early)的位置解决这个问题,Cilium 团队最近对 Linux 内核进行了修复,实现了在所有场景下允许两种 cgroup 版本 (part1, part2) 之间相互安全操作。这个修复不仅使 Cilium 的 cgroup 操作完全健壮可靠,而且也造福了 Kubernetes 中所有其他 eBPF cgroup 用户。
此外,Kubernetes 和 Docker 等容器运行时最近开始陆续宣布支持 cgroup v2。在 cgroup v2 模式下,Docker 默认会切换到私有 cgroup 命名空间,即每个容器(包括 Cilium)都在自己的私有 cgroup 命名空间中运行。Cilium 通过确保 eBPF 程序附加到正确的 cgroup 层次结构的 socket hooks 上,使 Cilium 基于套接字的负载均衡在 cgroup v2 环境中能正常工作。
增强负载均衡器的可扩展性
主要外部贡献者:Weilong Cui (Google)
最近的测试表明,对于运行着 Cilium 且 Kubernetes Endpoints 超过 6.4 万的大型 Kubernetes 环境,Service 负载均衡器会受到限制。有两个限制因素:
- Cilium 使用 eBPF 替代 kube-proxy 的独立负载均衡器的本地后端 ID 分配器仍被限制在 16 位 ID 空间内。
- Cilium 用于 IPv4 和 IPv6 的 eBPF datapath 后端映射所使用的密钥类型被限制在 16 位 ID 空间内。
为了使 Kubernetes 集群能够扩展到超过 6.4 万 Endpoints,Cilium 的 ID 分配器以及相关的 datapath 结构已被转换为使用 32 位 ID 空间。
Cilium Endpoint Slices
主要外部贡献者:Weilong Cui (Google), Gobinath Krishnamoorthy (Google)
在 1.11 版本中,Cilium 增加了对新操作模式的支持,该模式通过更有效的 Pod 信息广播方式大大提高了 Cilium 的扩展能力。
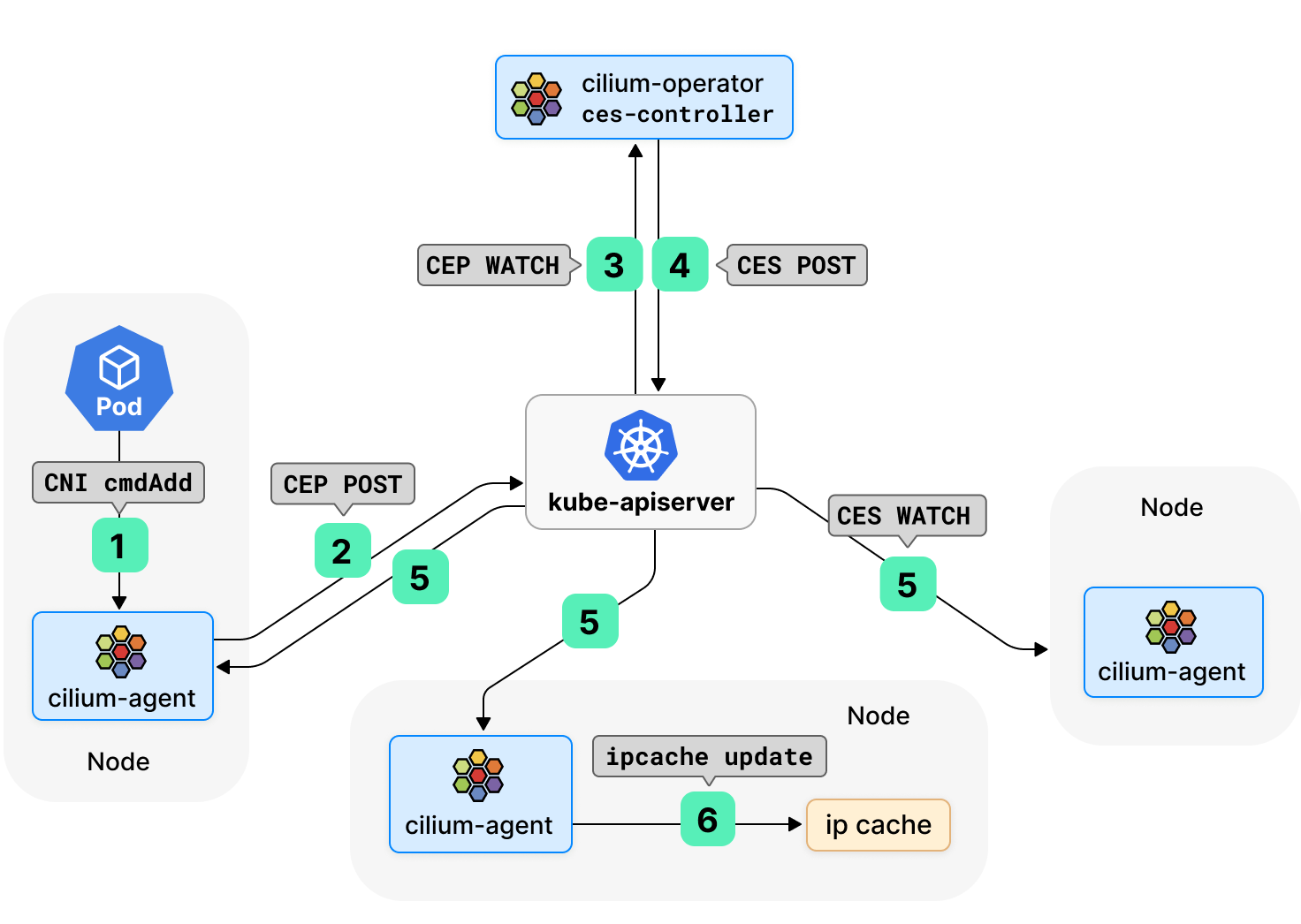
之前,Cilium 通过 watch CiliumEndpoint (CEP) 对象来广播 Pod 的 IP 地址和安全身份信息,这种做法在可扩展性方面会带来一定的挑战。每个 CEP 对象的创建/更新/删除都会触发 watch 事件的组播,其规模与集群中 Cilium-agent 的数量呈线性关系,而每个 Cilium-agent 都可以触发这样的扇出动作。如果集群中有 N 个节点,总 watch 事件和流量可能会以 N^2 的速率二次扩展。
Cilium 1.11 引入了一个新的 CRD CiliumEndpointSlice (CES),来自同一命名空间下的 CEPs 切片会被 Operator 组合成 CES 对象。在这种模式下,Cilium-agents 不再 watch CEP,而是 watch CES,大大减少了需要经由 kube-apiserver 广播的 watch 事件和流量,进而减轻 kube-apiserver 的压力,增强 Cilium 的可扩展性。
由于 CEP 大大减轻了 kube-apiserver 的压力,Cilium 现在已经不再依赖专用的 ETCD 实例(KVStore 模式)。对于 Pod 数量剧烈变化的集群,我们仍然建议使用 KVStore,以便将 kube-apiserver 中的处理工作卸载到 ETCD 实例中。
这种模式权衡了“更快地传播 Endpoint 信息”和“扩展性更强的控制平面”这两个方面,并力求雨露均沾。注意,与 CEP 模式相比,在规模较大时,如果 Pod 数量剧烈变化(例如大规模扩缩容),可能会产生较高的 Endpoint 信息传播延迟,从而影响到远程节点。
GKE 最早采用了 CES,我们在 GKE 上进行了一系列“最坏情况”规模测试,发现 Cilium 在 CES 模式下的扩展性要比 CEP 模式强很多。从 1000 节点规模的负载测试来看,启用 CES 后,watch 事件的峰值从 CEP 的 18k/s 降低到 CES 的 8k/s,watch 流量峰值从 CEP 的 36.6Mbps 降低到 CES 的 18.1Mbps。在控制器节点资源使用方面,它将 CPU 的峰值使用量从 28 核/秒减少到 10.5 核/秒。


详情请参考 Cilium 官方文档。
Kube-Proxy-Replacement 支持 Istio
许多用户在 Kubernetes 中使用 eBPF 自带的负载均衡器来替代 kube-proxy,享受基于 eBPF 的 datapath 带来的高效处理方式,避免了 kube-proxy 随着集群规模线性增长的 iptables 规则链条。
eBPF 对 Kubernetes Service 负载均衡的处理在架构上分为两个部分:
- 处理进入集群的外部服务流量(南北方向)
- 处理来自集群内部的服务流量(东西方向)
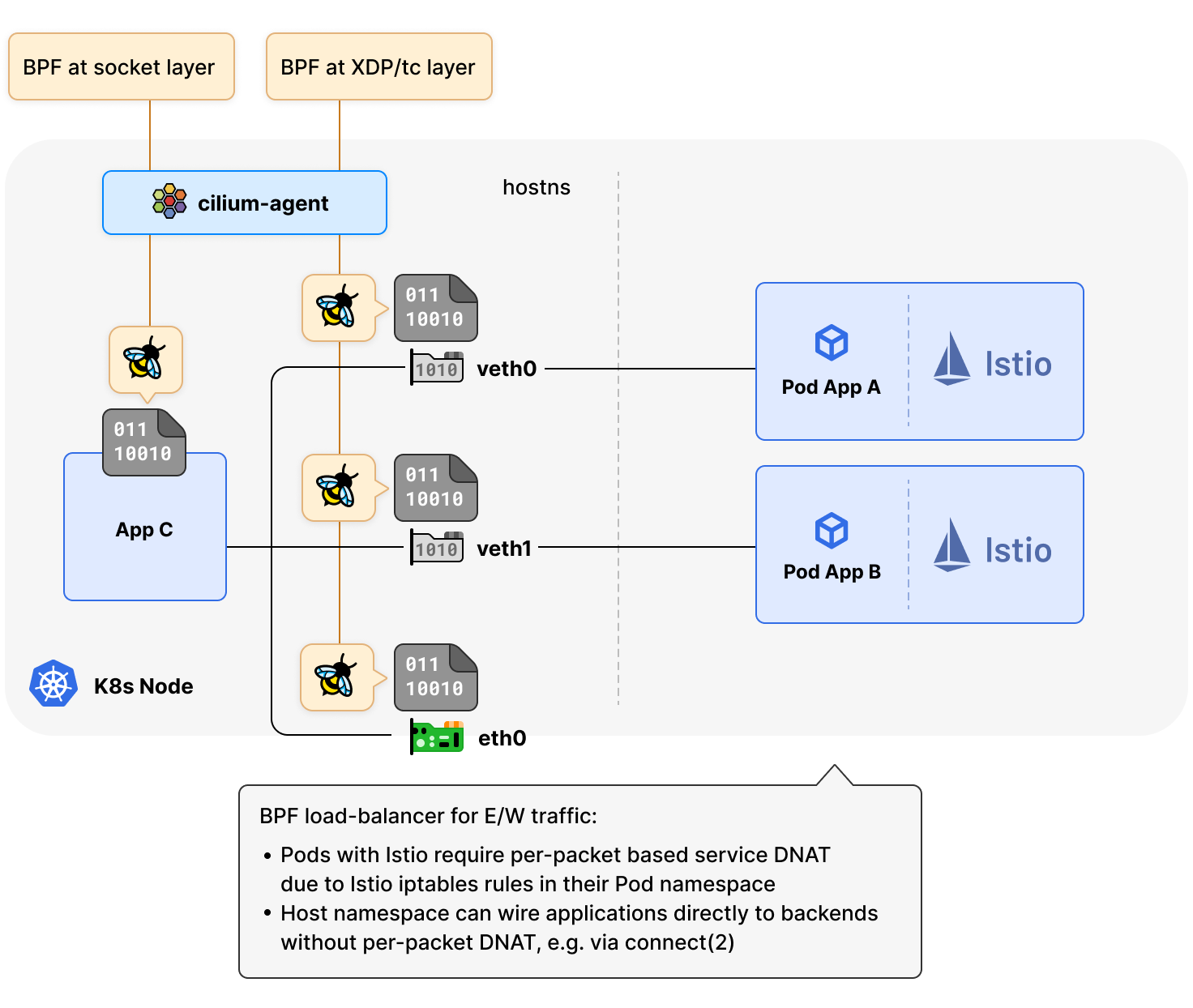
在 eBPF 的加持下,Cilium 在南北方向已经实现了尽可能靠近驱动层(例如通过 XDP)完成对每个数据包的处理;东西流量的处理则尽可能靠近 eBPF 应用层,处理方式是将应用程序的请求(例如 TCP connect(2))从 Service 虚拟 IP 直接“连接”到后端 IP 之一,以避免每个数据包的 NAT 转换成本。
Cilium 的这种处理方式适用于大多数场景,但还是有一些例外,比如常见的服务网格解决方案(Istio 等)。Istio 依赖 iptables 在 Pod 的网络命名空间中插入额外的重定向规则,以便应用流量在离开 Pod 进入主机命名空间之前首先到达代理 Sidecar(例如 Envoy),然后通过 SO_ORIGINAL_DST 从其内部 socket 直接查询 Netfilter 连接跟踪器,以收集原始服务目的地址。
所以在 Istio 等服务网格场景下,Cilium 改进了对 Pod 之间(东西方向)流量的处理方式,改成基于 eBPF 的 DNAT 完成对每个数据包的处理,而主机命名空间内的应用仍然可以使用基于 socket 的负载均衡器,以避免每个数据包的 NAT 转换成本。
要想开启这个特性,只需在新版 Cilium agent 的 Helm Chart 中设置 bpf-lb-sock-hostns-only: true 即可。详细步骤请参考 Cilium 官方文档。
特性增强与弃用
以下特性得到了进一步增强:
- 主机防火墙 (Host Firewall) 从测试版 (beta) 转为稳定版 (stable)。主机防火墙通过允许 CiliumClusterwideNetworkPolicies 选择集群节点来保护主机网络命名空间。自从引入主机防火墙功能以来,我们已经大大增加了测试覆盖率,并修复了部分错误。我们还收到了部分社区用户的反馈,他们对这个功能很满意,并准备用于生产环境。
以下特性已经被弃用:
- Consul 之前可以作为 Cilium 的 KVStore 后端,现已被弃用,推荐使用更经得起考验的 Etcd 和 Kubernetes 作为 KVStore 后端。之前 Cilium 的开发者主要使用 Consul 进行本地端到端测试,但在最近的开发周期中,已经可以直接使用 Kubernetes 作为后端来测试了,Consul 可以退休了。
- IPVLAN 之前用来作为 veth 的替代方案,用于提供跨节点 Pod 网络通信。在 Cilium 社区的推动下,大大改进了 Linux 内核的性能,目前 veth 已经和 IPVLAN 性能相当。具体可参考这篇文章:eBPF 主机路由。
- 策略追踪 (Policy Tracing) 在早期 Cilium 版本中被很多 Cilium 用户使用,可以通过 Pod 中的命令行工具
cilium policy trace来执行。然而随着时间的推移,它没有跟上 Cilium 策略引擎的功能进展。Cilium 现在提供了更好的工具来追踪 Cilium 的策略,例如网络策略编辑器和 Policy Verdicts。