引言
随着云原生技术日益普及的今天,在 Kubernetes 上运行无状态应用已经非常成熟,平滑扩展能力也很强,但对于有状态的应用,数据需要持久化存储,这还有很大提升的空间,面临着很多挑战。
云原生存储的挑战
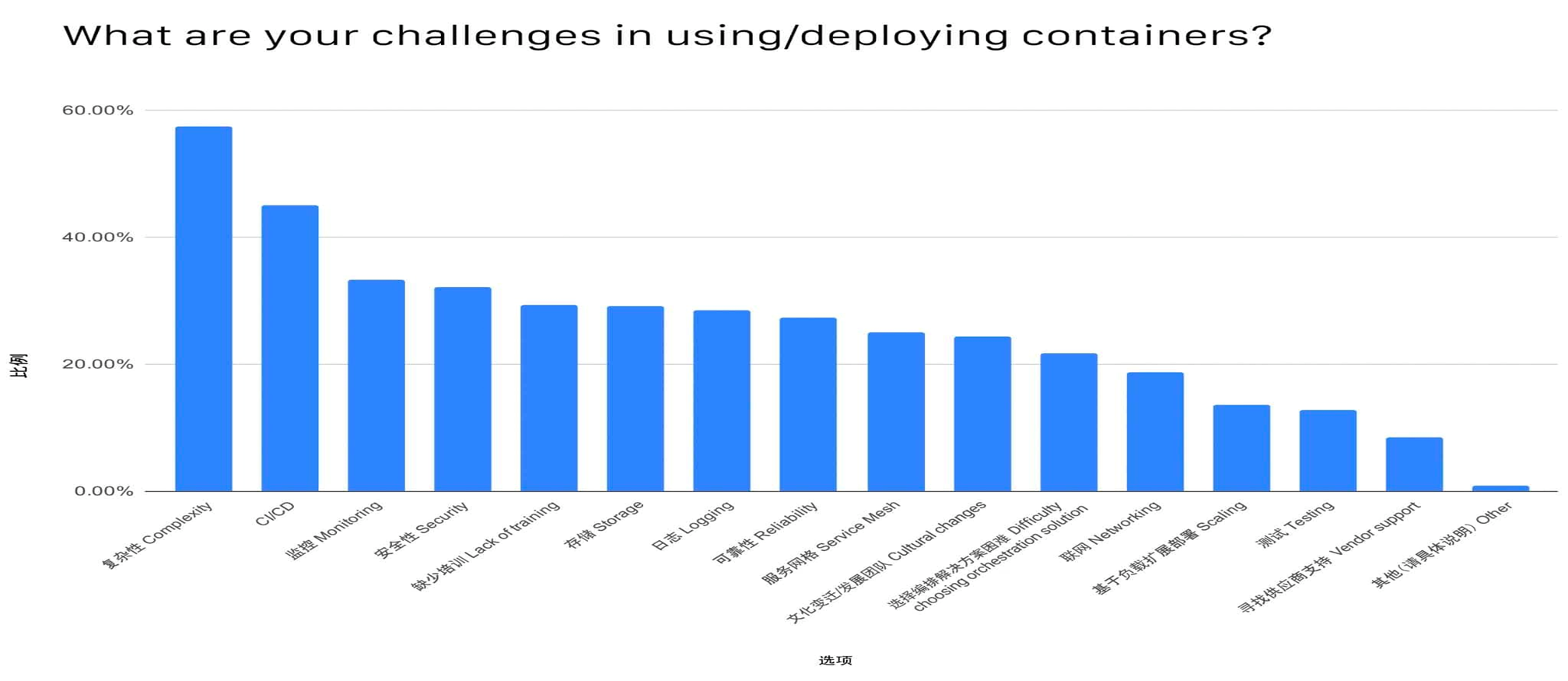
上图是 CNCF 对于“在使用/部署容器的过程中遇到的挑战”做出的调查报告。根据报告的结果,可以总结出云原生存储遇到的挑战表现在以下几个方面:
- 易用性:存储服务部署、运维复杂,云原生化程度低,缺少与主流编排平台整合
- 高性能:大量应用 IO 访问,IOPS 需求高,低时延,性能成为应用运行效率瓶颈
- 高可用:云原生存储已经应用到生产环境,需要高可靠/高可用,不能出现单点故障
- 敏捷性:PV 快速创建、销毁、平滑的扩展/收缩,PV 随 Pod 迁移而快速迁移等
常见云原生存储解决方案
Rook-Ceph:Rook-Ceph 是一个可以提供 Ceph 集群管理能力的 Operator,使用底层云原生容器管理,调度和编排平台提供的功能来执行其职责。
OpenEBS:OpenEBS 存储控制器本身就运行在容器中。OpenEBS Volume 由一个或多个以微服务方式运行的容器组成。
优势
1.与云原生编排系统的融合,具有很好的容器数据卷接入能力;
2.完全开源,社区较为活跃,网络资源、使用资料丰富,容易入手;
劣势
Rook-Ceph 不足:
- 性能差:IO 性能、吞吐、时延等方面都表现欠佳,很难应用在高性能服务场景;
- 维护成本高:虽然部署、入门简单,但组件多,架构复杂,排错困难,一旦运行中出现问题解决起来非常棘手,需要有很强的技术团队加以保障;
OpenEBS-hostpath 不足:没有高可用功能,单点故障;
OpenEBS-zfs-localpv 不足:在磁盘上安装 zfs,然后在 zfs上 创建 vol,也是没有高可用功能;
因此多在企业内部测试环境,很少用于持久化关键应用数据,部署到生产环境中;
NeonIO 为什么适合云原生存储
NeonIO 简介
NeonIO 是一款支持容器化部署的企业级分布式块存储系统,能够给 Kubernetes 平台上提供动态创建(Dynamic Provisioning) 持久存储卷(Persistent Volume) 的能力,支持 Clone、Snapshot、Restore、Resize 等功能,NeonIO 的结构图如下:
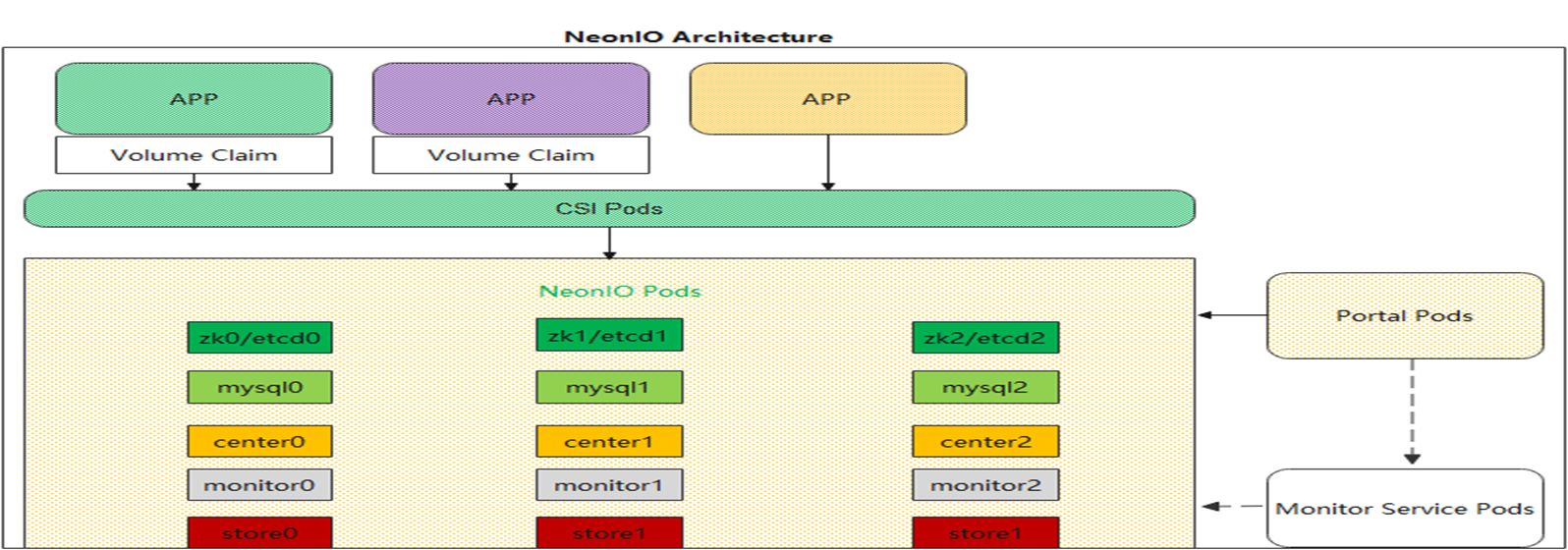
NeonIO 包括的服务组件如下:
- zk/etcd: 提供集群发现、分布式协调、选 master 等服务
- mysql:提供元数据存储服务,如 PV 存储卷的元数据
- center:提供逻辑管理服务,如创建 PV 卷,快照
- monitor: 提供监控服务,能够把采集监控指标暴露给 Promethus
- store:存储服务,处理应用 IO 的功能
- portal:提供 UI 界面服务
- CSI:提供 csi 的标准 IO 接入服务
下面从以下几个方面来看 NeonIO 为什么适合云原生存储:
易用性
-
组件容器化:服务组件、CSI、Portal 容器化
-
支持 CSI:提供标准的 IO 接入能力,可静态、动态创建 PV
-
UI 界面,运维方便:
- 存储运维操作界面化、告警、监控可视管理;
- 有基于 PV 粒度的性能监控,如 IOPS、吞吐量,可以快速定位到热点 PV;
- 有基于 PV 粒度的 Qos,能够保证用户高优先级的服务质量;
-
与云原生高度融合:
- 支持 Promethus,通过 ServiceMonitor 把 NeonIO 的采集指标暴露给 Promethus、Grafana,进行图形化展示
- 同时 UI 界面可与 Promethus 对接,展示其他云原生监控的指标,如 node-exporter 的磁盘 IO 负载、带宽等
- 平台化的运维方式,存储的扩容、升级、灾难恢复运维操作、只需要 Kubernetes 的一些命令即可实现,不需要额外掌握过多的存储相关的运维知识
- 服务发现、分布式协调支持 etcd、元数据的管理,使用 CRD 的方式
-
一键式部署::
helm install neonio ./neonio --namespace kube-system
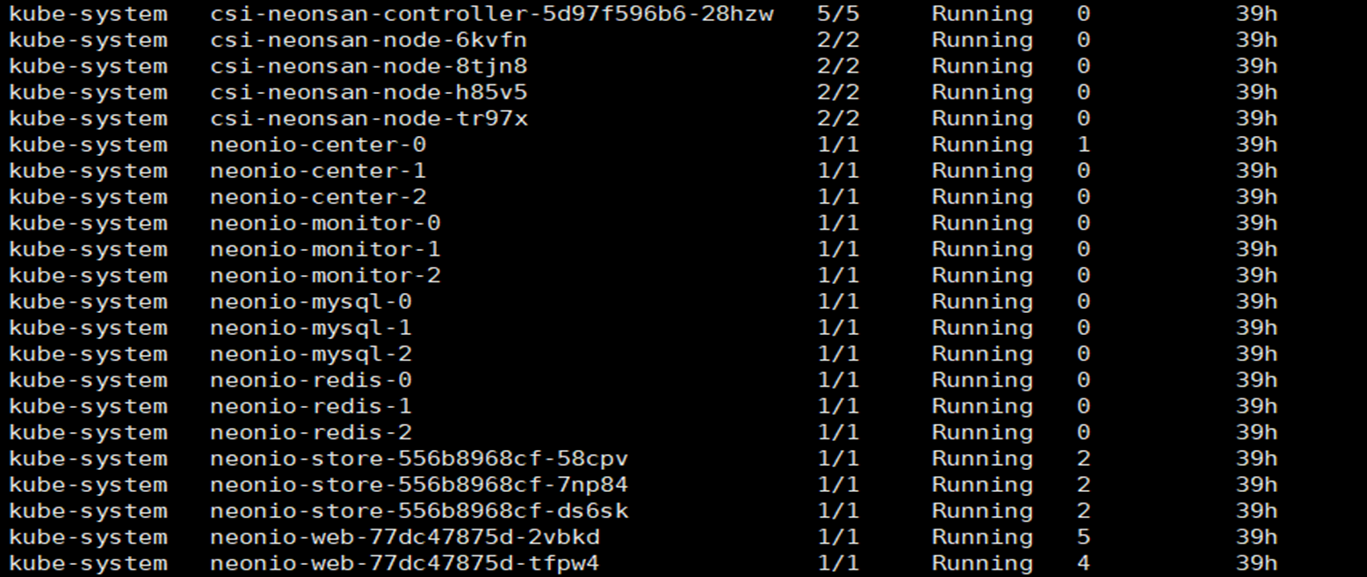
- 部署简单灵活:和 Rook-Ceph 对比:
| 功能 | NeonIO | Rook-Ceph |
|---|---|---|
| 节点规划部署 | 通过对对应节点打 label | 通过修改 cluster.yaml,需要配置节点 IP 配置那些服务 |
| Quick Start | 总共 4 步: 1.检查确保有可给供 neonio 的设备; 2.检查是否已经安装 QBD; 3.添加 helm repo; 4.安装部署: helm install neonio ./neonio --namespace kube-system |
总共 5 步 1.检查确保有可给供 ceph 的设备; 2.检查是否已经安装 RBD; 3.apt-get install -y lvm2 4.下载代码:git clone --single-branch --branch master https://github.com/rook/rook.git 5.cd rook/cluster/examples/kubernetes/ceph kubectl create -f crds.yaml -f common.yaml -f operator.yaml kubectl create -f cluster.yaml |
| 单机 all-in-one | helm install neonio ./neonio --namespace kube-system --set sc.rep_count=1 --set center.servers=1 -- | cd rook/cluster/examples/kubernetes/ceph kubectl create -f crds.yaml -f common.yaml -f operator.yaml kubectl create -f cluster-test.yaml 使用区别与集群部署时的另一个配置 cluster-test.yaml 进行部署,不能做到配置共用 |
| RDMA/TCP | helm install neonio ./neonio --namespace kube-system --set store.type=RDMA | ceph 本身支持 RDMA,rook-ceph 不支持 |
| 管理、存储网络分离/共有 | helm install neonio ./neonio --namespace kube-system --set store.port=eth0 --set rep_port.port=eth1 | ceph 本身 pubic、cluster 网口的分离公用,rook-ceph 适配复杂 |
高性能
性能单 PV IOPS 100K,时延亚毫秒。
-
全闪的分布式存储架构
- 集群中所有节点共同承担压力,IO 性能随着节点增加而线性增长
- 存储介质支持 NVME SSD
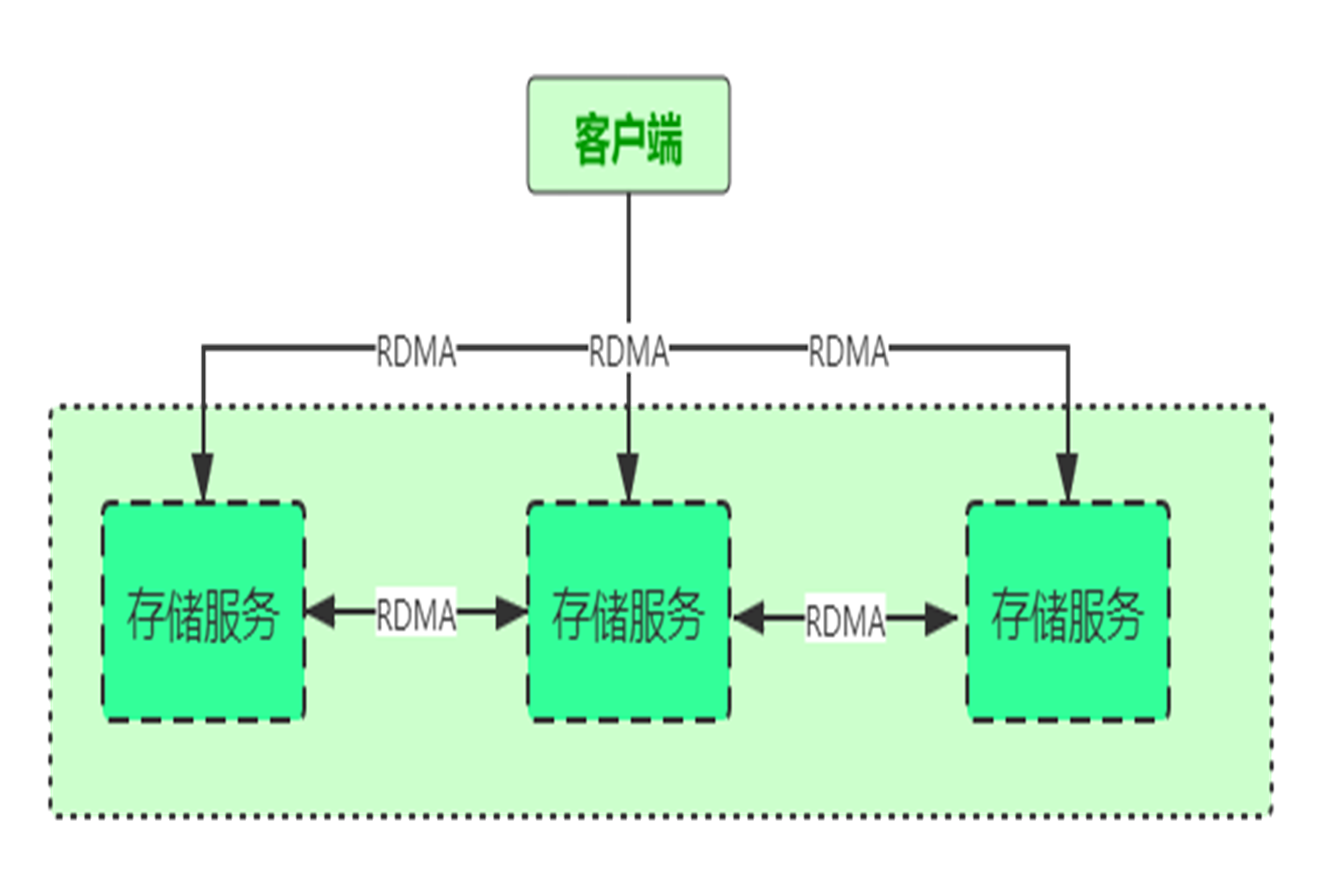
- 支持 RDMA:通过高速的RDMA技术将节点连接
-
极短的 IO 路径:抛弃文件系统,自研元数据管理系统,使 IO 路径极短
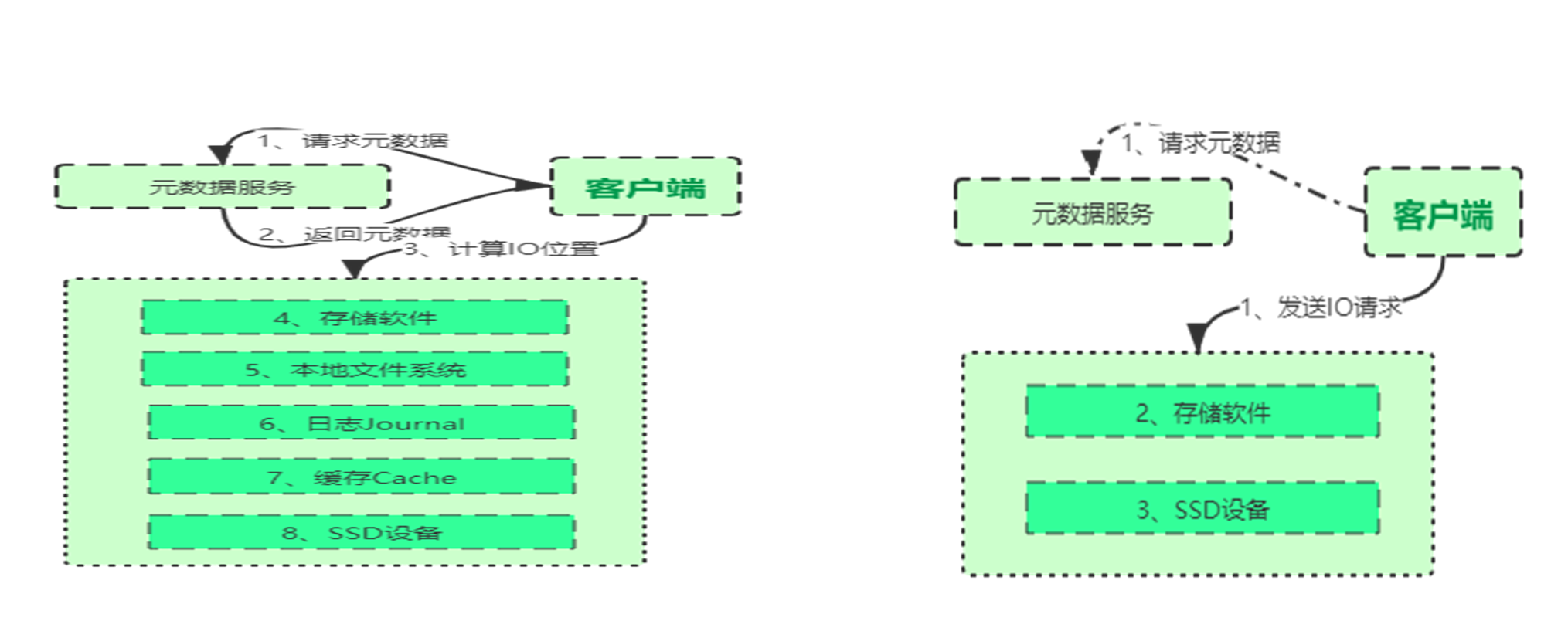
- 使用 HostNetwork 网络模式
好处:
- Store CSI Pod 使用 HostNetwork,直接使用物理网络,减少网络层次
- 管理网络、前端网络、数据同步网络分离,避免网络竞争;
高可用
-
服务组件可靠性与可用性
- 管理服务默认使用 3 副本 Pod,副本数可以配置,推荐使用 3/5 副本,任何一 Pod 因故障无法提供服务,还有其他 Pod 提供服务
- 使用探针检测 Pod 服务是否可用,是否存活,检测到 Pod 服务部可用剔除组件服务,检测到 Pod 死掉后重启 Pod,使其重新启动服务
-
数据的可靠性与可用性
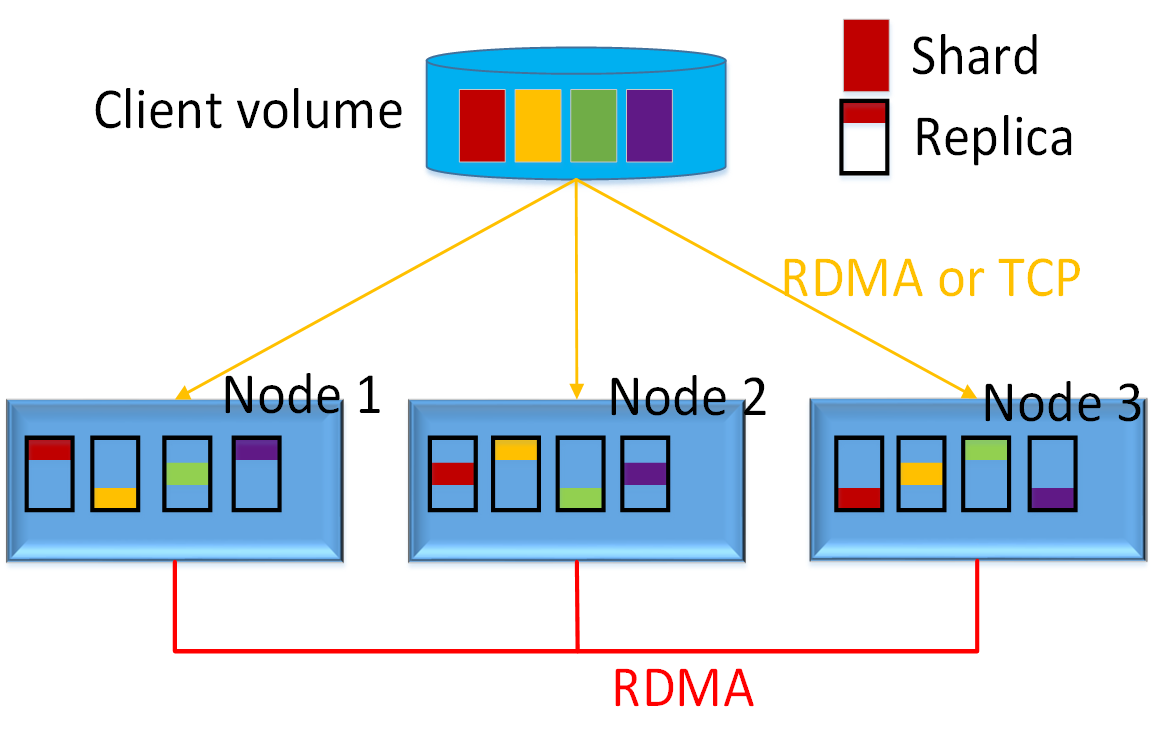
- Volume 分片为 Shard
- 每个 Shard 独立选择存储位置
- 每个 Shard 的 3 个副本存储在不同的物理节点上
- 写入时同步写入 3 个副本,强一致
- 读取时只从主副本读
- 副本数按 volume 可配
敏捷性
- Pod 跨节点重建高效:2000PV 的挂载/卸载 16s
- 批量创建 PV 能力:2000PV 的创建 5min
NeonIO性能表现
Teststand: NeonIO hyper-converged all-in-one cluster (3 nodes, 192.168.101.174 - 192.168.101.176)
Note: All tests use NVMe SSDs. Volume size = 1TiB. Performance tool: https://github.com/leeliu/dbench
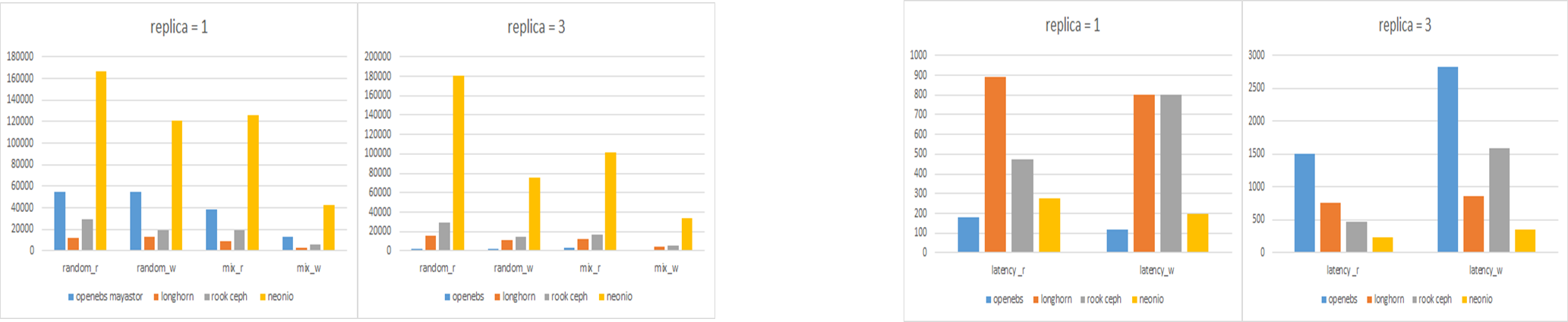
图中黄色表示的是 NeonIO,第一张图纵坐标是 IOPS,第二张图纵坐标是毫秒,从结果来看,无论是单副本还是 3 副本,NeonIO 在 IOPS、时延都有明显的优势。
NeonIO应用场景
- Devops 场景:批量快速创建/销毁 PV 能力,2000PV 创建 5min
- 数据库场景:WEB 网站后端数据库 MySQL 等提供稳定的持久化存储,提供高 IOPS、低时延
- 大数据应用分析场景:提供超大容量,PV 可扩容到 100TB
本文由博客一文多发平台 OpenWrite 发布!