lxml的作用
lxml是HTML、xml的解析器,主要的功能是如何解析和提取HTML和xml数据
lxml和正则一样,也是使用C来实现的,是一款高性能的python HTML/xml解析器,我们可以使用xpath语法快速定位特定元素和节点信息
xpath的介绍
xpath(xml path language)是一门在xml文档之查找信息的语言,可用来在xml文档中对元素和属性进行遍历
路径表达式
最常用的路径表达式:
/ :表示从根节点选取
//:从匹配选择的当前节点选择文档中的节点,而不考虑他们的位置
.:选取当前节点
..:选取当前节点的父节点
@:代表选取属性
常用路径表达式及其表达式结果
/bookstore:选取根元素bookstores,
注释:如果路径起始于正斜杠(/),则此路径始终代表到某元素的绝对路径
bookstore/book:选取属于bookstore的子元素的所有book元素
//book:选取所有book子元素,而不管他们在文档中的位置
bookstores//book:选取属于bookstores元素后代的所有book元素,而不管他们位于bookstores下的什么位置
//@lang:选取说有
谓语限制节点位置
谓语用来查找某个特定的节点,或者包含某个指定值的节点,被嵌在方括号中
xpath的索引是从1开始,切记不是从零开始
/bookstores/book[1]:选取bookstores中子元素的第一个book元素
/bookstores/book[last()]:选取bookstores中子元素的最后一个book元素
/bookstores/book[last-1]:选取bookstores中子元素的倒数第二个book元素
/bookstores/book[position<3]:选取bookstores中子元素的前两个book元素
//title[@lang]:选取所有含有名为lang属性的title元素
//title[@lang="eng"]:选取所有含有名为lang属性且属性值为“eng”的title元素
/bookstores/book[@preice>35.0]:选取bookstores元素的子元素属性price值大于35.0的book元素
/bookstores/book[@price>35.0]/title:选取bookstores元素的子元素属性值price值大于35.0的book元素的子元素title元素
选取未知元素
*:匹配任何元素节点
*@:匹配任何属性节点
/bookstores/*:选取bookstores元素的所有子节点
//*:选取文档中的所有元素
//title[@*]:选取文档中所有带有属性的title元素
选取若干路径
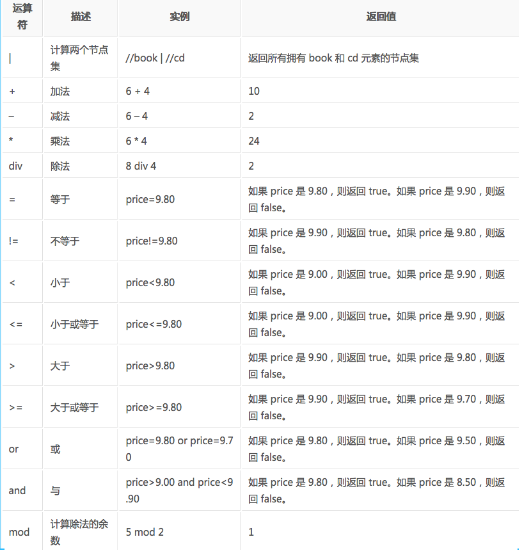
通过在路径表达式中使用“|”运算符,就可以选取若干个路径
//book/title|//book/price:选取子元素节点是price和title的所有book节点的路径
//book|//title:选取文档中所有的book元素和title元素节点
//bookstores/book/title|//price:先去文档中所有bookstores元素的book元素的title元素或是文档中所有的price元素
xpath的运算符
from lxml import etree
# xml是str类型的数据
xml = '''<div>
<ul>
<li class="item-0">老王买刀<a href="link1.html">first item</a></li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-inactive"><a href="link3.html">third item</a></li>
<li class="item-1"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a>
</ul>
</div>
'''
# lxml中的etree的HTML方法是将str类型的数据转换成为HTML对象
tree = etree.HTML(xml)
# lxml中etree的tostring方法是将HTML对象再转换成为字符串,字符串格式是(不带xml申明的阿斯克码),并且在原标签基础上添加了<html>和<body>
print(etree.tostring(tree,encoding="utf8").decode("utf8"))
# 将转化成对象的HTML使用xpath进行解析
info =tree.xpath("./body/div/ul/li")
print(info)
# 使用属性进行限制,找到指定的li,返回的对象是一个列表
print(tree.xpath("//li[@class='item-inactive']/a"))
# 结果:[<Element a at 0x9fe8888>]
# 获取a标签中属性为href的值
print(tree.xpath("//li/a/@href"))
# 获取标签中的内容,使用text()用在路径中,使用text用在标签对象上,此时text变成了标签的属性
print(tree.xpath("//li/text()"))
# 获取标签li中的class属性,使用get()
print(tree.xpath("//div//li")[0].get("class"))
# 批量获取标签的属性和标签内容
ret =tree.xpath("//div//li")
ree = [info.get("class") for info in ret ]
rea = [info.text for info in ret]
print(ree)
#输出结果:['item-0', 'item-1', 'item-inactive', 'item-1', 'item-0']
print(rea)
#输出结果:['老王买刀', None, None, None, None]
xpath使用总结:
查找所有的元素://li
查找所有的属性://div/@href
查找所有的元素值://ul/text()
根据条件进行查找:[@id>="50"] 、[@id="50" and @class="haha"]、[contains(@class,"a")]、//li|//ul 元素e,e.get('attr'),e.text 获取元素的值