一、python语言基本的8个要素
Python语言的8个要素:数据类型、对象引用、组合数据类型、逻辑操作符、运算操作符、控制流语句、输入/输出、函数的创建与引用。除此之外还有一个非常重要且无处不在的要素:对象。实际上,在所有的语言当中,这种要素结构几乎一样。
1.要素1--数据和对象类型
python的数据类型是指内置数据类型。python基本的内置数据类型是数字(int)、字符串(str)、列表(list)、元组(tuple)和字典(dic),python基本的内置对象包括文件、对象(object)、布尔值(bool)、None。python中的内置数据类型也是一个对象。
具体来讲,python的基础[标准]数据类型包括:数字、整型、布尔型、长整型、浮点型、复数型、字符串、列表、字典和元组。python的其他内建类型包括:类型、Null对象(None)、文件、集合(固定集合)、函数/方法、模块、类。
2.要素2--变量和对象引用
第二步是定义储存数据类型的变量。在python中,变量(有的书中称为对象引用)不需要提前声明,有的语言是可以提前声明而不赋值的(如js:var x;)。
以 x = 123为例作一些探讨。
在这个语句中,123存在(或生成)于内存中,它是一个数字对象(type(123) = int);x是变量,或者称为对象引用(即引用了内存中数字对象123);
“=”的作用是把变量(对象引用)与内存中的数字123进行绑定(或重新绑定)。如果变量x没有被声明(创建),则“=”会创建x并把它绑定到123上;如果x已被声明,则进行重绑定。
变量(引用对象)的名字,称为“标识符”。当然标识符(也即变量的名字)也它的命名规则。
如果直接写一个数字或字符串而没有被赋给某个变量,则它称为“字面量常量”。
3.要素3--组合数据类型
与python中的其他内容一样,组合数据类型也是对象,因此可以将某种组合数据类型嵌套在其他组合类型里。
实质上,列表和元组并不存真正的数据项,而是存放对象引用。
元组、列表、字符串等数据类型都是有“长度的”,将这些数据类型传给len函数是有意义的。
组合数据对象有自己的属性和方法。
4.要素4--逻辑操作符
a.身份操作符 is
is操作符是一个二元操作符,如果其左端的对象引用与右端的对象引用指向的是同一个对象,则会返回true。is操作符只需要对对象的内存地址进行比较,所以速度很快。
b.比较操作符 ==、!=、<=、 >、<
a = "123",b = "123",c = 123。a is b (True),a == b (True),a is c (False), a >= c (报错。)
python比较操作符只会进行同类对象的比较。python可以进行链接比较。123 < 456 < 789。
c.成员操作符 in / not in
d.逻辑运算符 and or not
1.在没有()的情况下not 优先级高于 and,and优先级高于or,即优先级关系为( )>not>and>or,同一优先级从左往右计算。
2.x or y , x为真,值就是x,x为假,值是y;x and y, x为真,值是y,x为假,值是x。
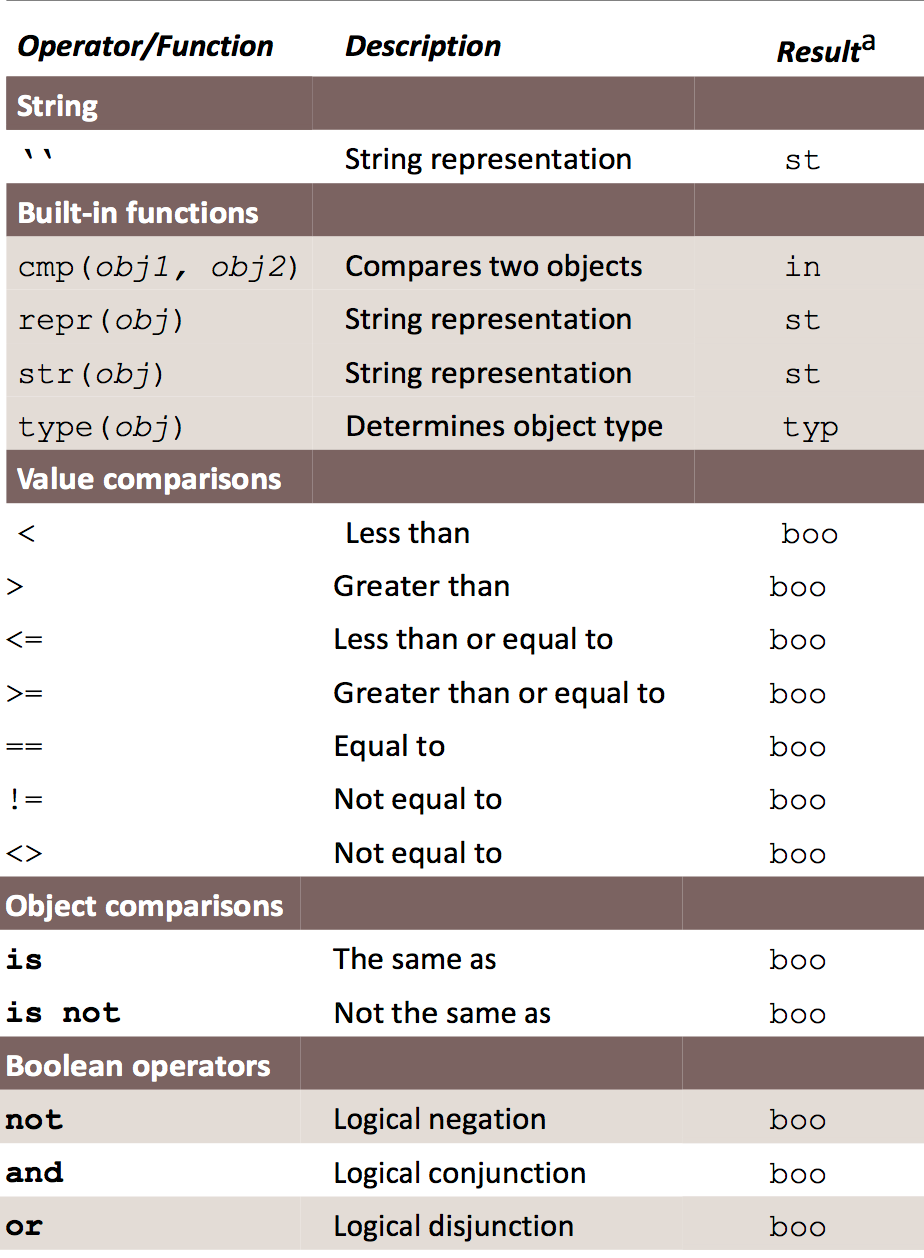
注:同一灰度的运算符具有同样的优先级。每一组运算符的优先级由上至下。
5.要素5--算术运算法
+、 -、 *、 /、 %、 **
在这里需要剖析一下 a = 0, a += 2的过程。第一步是创建内存对象0并把它的内存地址绑定给a这个对象引用。第二步,计算 0 + 2,并将对象引用a重新绑定到新的内存地址。原来的内存对象0由于其引用计数变成了0而被来及回收。
列表和字符串都支持 + 、 * 操作。
6.要素6--流程控制
a. if - elif - else语句
.py文件中的每条语句都是自上而下一条条执行的。这里写条件的时候一定要注意范围的问题。
b.while - break - continue - else语句
while循环中支持break、continue、els语句。
while循环要对while 后面的参数进行布尔判断,并决定是否继续下一次循环。跟据参数可以大致分为两种循环方式。标志符的True/False判断,参数的迭代次数判断。后者可以对参数的迭代进行跳跃。
break:当某个条件满足时,执行到break行时,会直接跳出break所在的那一层循环;
continue:当某个条件满足时,执行到continue时,会跳过当次循环时continue行后面的代码,但是仍会继续执行continue所在的那一层循环;
通常,break和continue都用在if语句的内部。
else:while正常结束时执行else内部的代码。如果while循环被break中断,则不会执行else代码。


1 n = 0 2 while n < 5: 3 if n == 3: 4 print(n) 5 break 6 else: 7 pass 8 n += 1 9 else: 10 print("over!")
c.for - in 语句
for 循环也支持continue、break和else,其用法与while基本一致。for循环可以对可迭代对象进行逐一迭代。
典型的写法包括三种方式。for index in range(len(list)),for item in (list),这两种循环可根据索引或对象引用对列表进行迭代。当然也推荐使用for index, value in enumerate(list) 对list迭代。
for key, value in dict.items(),可以对字典对象进行迭代。当然也有for key in dict.keys(),for value in dict.values()。
for循环支持"_"。如for key, _ in dict.items()。
d.try - except - finally异常处理
它是流程控制的一部分。这里暂不做细写。
e.goto跳转:愚人节的作品,不推荐使用。
7.要素7--输入输出
a.input 和 print
input和print支持用户交互。Input的返回值是一个字符串,因此需要进行格式转化;print没有返回值,但是终端执行py文件时可以配合>输入到文本中保存。
b.格式化
1 "{name}, {age}".format(name="json", age=45) 2 "{0}, {1}".format("json", 45) 3 "{[0]}, {[1]}".format(["json", "bob"], [45, 27])
1 print("%s, %d" % ("json", 45)) 2 print("%r, %r" % ("json", 45)) 3 print("%(name)s, %(age)s" % ({"name": "json", "age": 45}))
8.要素8--函数
函数是面向对象中不可分割的最小功能性单元(逻辑上不可分割的代码块),在对象解耦中需要考虑函数的功能和具体代码。它可以接收参数,并执行相应的代码块,最后返回(或不返回)一个结果。
def可以创建函数。它的具体做法是:在内存中创建一个函数对象,并将该函数对象的内存地址绑定到该对象运用上(函数名)。
函数的另一重要特性是减少内存变量。因为除非在函数中声明global,否则函数内部的变量仅创建和回收于函数执行周期内。除非特别重要的变量,一般不会在.py中直接定义变量。(直接定义的变量显然存在于.py文件执行的整个进程中,占用系统资源。)
9.要素9--类
说到类,自然有三个词浮现出来,继承、多态、封装,用于实现更为复杂的操作。class用于创建类。暂时不提。
二、python的语法和标识符
1.语句和语法
注释:#表示单行注释,""""""表示多行注释或者格式化输出。
换行: ,标准的行分隔符。
继续:,反斜杠表示本行的代码继续上一行。
分号:;,表示两行代码如果写到一行里,可以用分号分开。
冒号::,将代码块的头和体分开。
缩进:tab,将代码块进行逻辑区分。
2.变量和标识符
重申一遍,python是没有变量这一概念的。如,在python如果只写“123”,你可能无法拿到123.因为它写在内存里,没有变量储存它。如果写"x = 123",就是在内存里写了123,并创建了一个名为x的标识符,它引用了123这个对象(内存地址)。因此,所谓的变量其实指的是对象引用。
变量赋值。包括“=”赋值,链式赋值,增量赋值,多元赋值。
标识符。规则:第一个字符必须是字母或者下划线,其余字符可以是字母数字下划线,大小写敏感。
关键字:被python占用的标识符。import keyword;print(keyword.kwlist),可以查看关键字。除此之外还有内建的其它字符(收录在__builtins__中)。
专用下划线标识符:
_xxxx :不能被其它的模块导入
__xxx__ :系统定义名字
__xxx :类中的私有变量
三、python的字符编码
参考林海峰的博客,非常详尽。
https://www.cnblogs.com/linhaifeng/articles/5950339.html#_label8
四、python的代码结构

(1)起始行,指定脚本运行的解释器。当然可以写上编码格式-*- coding:utf-8 -*-。
(2)介绍文档。可以通过模块名.__doc__来查看。
(3)导入其它模块。导入其它的模块只有在调用具体方法时执行。
(4)定义全局变量。尽量少,可以节省内存。
(5)类定义解释文档。功能和模块文档一样。可以通过类名.__doc__来访问
(6)函数定义语句。可以通过module.function()被调用。函数文档和模块文档一样,可以通过函数名.__doc__来访问。
(7)主程序。该功能可用于测试。当当前模块直接执行时,主程序__name__的值为"__main__",当当前模块被被的py文件导入和调用时,它的名字__name__为模块名。
五、内存管理
python解释器承担了内存管理的任务,并通过引用计数和垃圾回收机制这一方式来实现具体操作。
1.引用计数
引用计数:python解释器执行py文件时,记录了对所有使用中的对象的引用次数。当一个对象被创建(如x = 123)时,引用次数就+1,当一个对象被删除(del x)时,引用次数就-1。当引用次数为0时,123在内存中都会被清除。因此,引用计数计算的方式是内存地址的引用次数例如,x = 123, y = x,此时对象123的引用次数为2;当执行del x时,123的引用计数为1变为1。
2.增加引用计数的方法
对象被创建: x = 123;
或另外的别名被创建: y=x
或被当做参数传递给函数(新的本地引用): foobar(x)
或称为容器对象的一个元素,如myList = [x, 123, "xyz"]
3.减少引用计数的方法
一个本地引用离开了其作用范围,比如foorbar()函数结束时。
对象的别名被显式地销毁。del x
对象的一个别名被赋给其它对象:x = 123, x = 456。
窗口对象本身被销毁。 del myList。
4.垃圾回收
不再被使用的内存会被垃圾机制回收。解释器负责跟踪对象的引用次数,垃圾收集器负责释放内存。垃圾收集器是一块独立代码。它用来寻找引用计数为0的对象,以及检查一些引用计数非0但也应被回收的对象。当一个对象的引用计数为0时,解释器会暂停,并释放掉这个对象及可访达它的内存地址。
5.内存占用
所有的python对象都至少拥有一个整型引用记数、一个类型定义描述符及真实数据的表示这三部分。下面是一些内建数据类型使用的内存大小
Interger 12 bytes
Long interger 12 bytes + (nbits/16 + 1)*2 bytes
Floats 16 bytes
Complex 24 bytes
List 16 bytes + 4 bytes * 每个元素
Tuple 16 bytes + 4 bytes * 每个条目
String 20 bytes + 1 bytes * 每个字符
Unicode string 24 bytes + 2 bytes * 每个字符
Dictionary 24 bytes + 12*2n bytes, n = log2(nitems)+1