一、简介
每个网页,都有一定的特殊结构和层级关系,而且很多节点都有 id 或 class 作为区分,我们可以借助它们的结构和属性来提取信息。
PyQuery 是一个强大的 HTML 解析库,利用它,我们可以直接解析 DOM 节点的结构,并通过 DOM 节点的一些属性快速进行内容提取。
pyquery 是 Python 的第三方库,可以用 pip3 来安装,安装命令如下:
pip install pyquery
在解析 HTML 文本的时候,首先需要将其初始化为一个 pyquery 对象。它的初始化方式有多种,比如直接传入字符串、传入 URL、传入文件名等等。
字符串初始化
可以直接把 HTML 的内容当作参数来初始化 pyquery 对象,下面用一个实例来感受一下:
from pyquery import PyQuery as pq
html = '''
<div>
<ul class="clearfix">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"></li>
<li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"></li>
</ul>
</div>
'''
doc = pq(html)
print(doc('li'))
运行结果如下:
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li><img src="http://pic.netbian.com/uploads/allimg/210107/215736-1610027856f6ef.jpg"/></li>
<li><img src="http://pic.netbian.com//uploads/allimg/190902/152344-1567409024af8c.jpg"/></li>
首先引入 pyquery 这个对象,取别名为 pq,然后定义了一个长 HTML 字符串,并将其当作参数传递给 pyquery 类,这样就成功完成了初始化。
接下来,将初始化的对象传入 CSS 选择器。在这个实例中,我们传入 li 节点,这样就可以选择所有的 li 节点。
URL 初始化
# -*- coding: UTF-8 -*-
from pyquery import PyQuery as pq
url = 'https://www.cnblogs.com/feng0815/'
doc = pq(url)
print(doc('title'))
运行结果如下:
<title>尘世风 - 博客园</title>
pyquery 对象会首先请求这个 URL,然后用得到的 HTML 内容完成初始化。这就相当于将网页的源代码以字符串的形式传递给 pyquery 类来初始化。
文件初始化
除了传递一个 URL,我们还可以传递本地的文件名,参数指定为 filename 即可:
from pyquery import PyQuery as pq
doc = pq(filename='时间轮播图.html')
print(doc('title'))
运行结果如下:
<title>Awesome-pyecharts</title>
当然,这里需要有一个本地 HTML 文件,其内容是待解析的 HTML 字符串。这样它会先读取本地的文件内容,然后将文件内容以字符串的形式传递给 pyquery 类来初始化。
以上 3 种方式均可初始化,当然最常用的初始化方式还是以字符串形式传递。
二、pyquery基本使用
基本 CSS 选择器
用一个实例来感受一下 pyquery 的 css 选择器的用法:
from pyquery import PyQuery as pq
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
doc = pq(html)
print(doc('#container .list li'))
print(type(doc('#container .list li')))
运行结果如下:
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
<class 'pyquery.pyquery.PyQuery'>
初始化 pyquery 对象之后,传入 css 选择器 #container .list li,它的意思是先选取 id 为 container 的节点,然后再选取其内部 class 为 list 的所有 li 节点,最后打印输出。
可以看到,我们成功获取到了符合条件的节点。我们将它的类型打印输出后发现,它的类型依然是 pyquery 类型。
下面,我们直接遍历这些节点,然后调用 text 方法,就可以获取节点的文本内容
from pyquery import PyQuery as pq
html = '''
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
'''
doc = pq(html)
for item in doc('#container .list li').items():
print(item.text())
运行结果如下:
first item
second item
third item
fourth item
fifth item
而是直接通过选择器和 text 方法,就得到了我们想要提取的文本信息,是不是挺方便的?
获取信息
提取到节点之后,我们的最终目的当然是提取节点所包含的信息了。比较重要的信息有两类,一是获取属性,二是获取文本,下面分别进行说明。
获取属性:提取到某个 pyquery 类型的节点后,可以调用 attr 方法来获取属性:
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
doc = pq(html)
a = doc('.item-0.active a')
print(a, type(a))
print(a.attr('href'))
print(a.attr.href)
运行结果如下:
<a href="link3.html"><span class="bold">third item</span></a> <class 'pyquery.pyquery.PyQuery'>
link3.html
link3.html
在这个例子中我们首先选中 class 为 item-0 和 active 的 li 节点内的 a 节点,它的类型是 pyquery 类型。然后调用 attr 方法。在这个方法中传入属性的名称,就可以得到属性值了。此外,也可以通过调用 attr 属性来获取属性值。
遍历获取所有的 a 节点的属性:
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
doc = pq(html)
nodes = doc('a')
for item in nodes.items():
print(item.attr('href'))
运行结果如下:
link2.html
link3.html
link4.html
link5.html
因此,在进行属性获取时,先要观察返回节点是一个还是多个,如果是多个,则需要遍历才能依次获取每个节点的属性。
获取文本
获取节点之后的另一个主要操作就是获取其内部文本了,此时可以调用 text 方法来实现:
from pyquery import PyQuery as pq
html = '''
<div class="wrap">
<div id="container">
<ul class="list">
<li class="item-0">first item</li>
<li class="item-1"><a href="link2.html">second item</a></li>
<li class="item-0 active"><a href="link3.html"><span class="bold">third item</span></a></li>
<li class="item-1 active"><a href="link4.html">fourth item</a></li>
<li class="item-0"><a href="link5.html">fifth item</a></li>
</ul>
</div>
</div>
'''
doc = pq(html)
nodes = doc('li')
for item in nodes.items():
print(item.text())
运行结果如下:
first item
second item
third item
fourth item
fifth item
三、爬取B站视频热搜榜单数据
下面用一个爬取B站视频热搜榜单数据的实例来熟悉 PyQuery 的使用
URL:https://www.bilibili.com/v/popular/rank/all
1、发送请求
import requests
# 伪装请求头
headers = {
"Origin": "https://www.bilibili.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
}
# 目标URL
url = 'https://www.bilibili.com/v/popular/rank/all'
# request请求获取的文本传入PyQuery初始化
resp = requests.get(url, headers=headers)
print(resp.status_code)
print(resp.text)
在上面的代码中,我们完成了以下几件事:
-
导入 requests 库
-
伪装请求头
-
使用 get 方法构造请求
-
打印查看请求的状态码和网页源代码文本
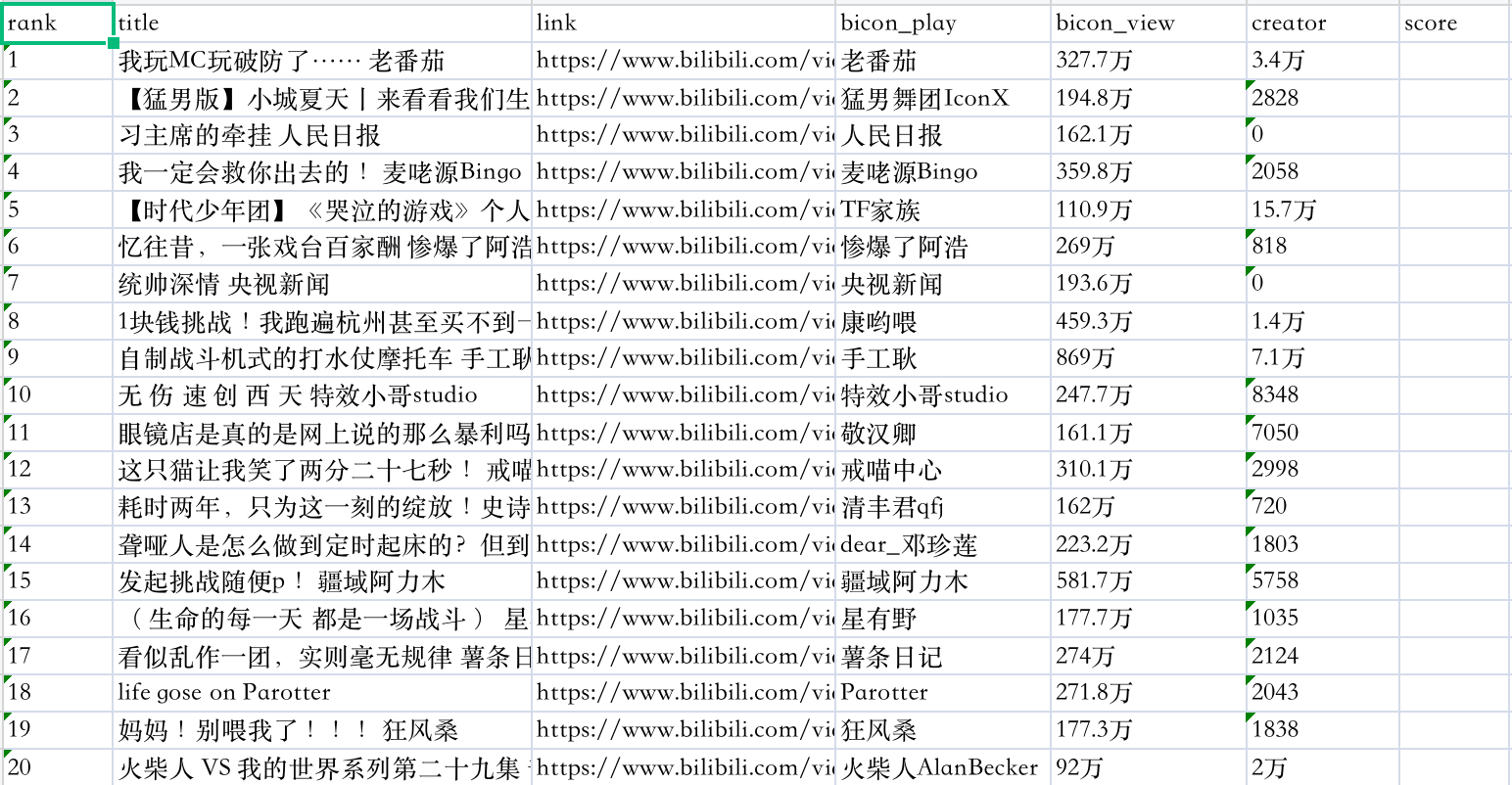
2、解析提取数据和保存
from pyquery import PyQuery as pq
import openpyxl
wb = openpyxl.Workbook() # 初始化工作簿对象
sheet = wb.active # 获取活动的工作表
# 添加列名
sheet.append(['rank', 'title', 'link', 'bicon_play', 'bicon_view', 'creator', 'score'])
doc = pq(resp)
# 获取class=rank-list 下所有li节点内容
# 遍历li节点
con1 = doc('.rank-list li')
for item in con1.items():
rank = item('.num').text() # 排名
title = item('.content .info a:first-child').text() # 视频标题
link = 'https:' + item('.content .info a').attr('href') # 视频链接
# creator = item('.content .info .detail a span').text() # UP主
bicon_play, bicon_view, creator = item('.content .info .detail span').text().split(' ')
# print(bicon_play, bicon_view, creator)
score = item('.content .info .pts div').text()
sheet.append([rank, title, link, bicon_play, bicon_view, creator, score])
wb.save(filename='data.xlsx')
- 完整代码
# -*- coding: UTF-8 -*-
from pyquery import PyQuery as pq
import requests
import logging
import openpyxl
wb = openpyxl.Workbook() # 初始化工作簿对象
sheet = wb.active # 获取活动的工作表
# 添加列名
sheet.append(['rank', 'title', 'link', 'bicon_play', 'bicon_view', 'creator', 'score'])
# 日志输出配置
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
# 伪装请求头
headers = {
"Origin": "https://www.bilibili.com",
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1"
}
# 目标URL
url = 'https://www.bilibili.com/v/popular/rank/all'
# request请求获取的文本传入PyQuery初始化
resp = requests.get(url, headers=headers).text
doc = pq(resp)
# 获取class=rank-list 下所有li节点内容
# 遍历li节点
con1 = doc('.rank-list li')
for item in con1.items():
rank = item('.num').text() # 排名
title = item('.content .info a:first-child').text() # 视频标题
link = 'https:' + item('.content .info a').attr('href') # 视频链接
# creator = item('.content .info .detail a span').text() # UP主
bicon_play, bicon_view, creator = item('.content .info .detail span').text().split(' ')
# print(bicon_play, bicon_view, creator) # 排名
score = item('.content .info .pts div').text()
sheet.append([rank, title, link, bicon_play, bicon_view, creator, score])
logging.info([rank, title, link, bicon_play, bicon_view, creator, score])
wb.save(filename='data.xlsx')
运行效果如下:
2022-08-02 14:03:20,376 - INFO: ['1', '我玩MC玩破防了…… 老番茄', 'https://www.bilibili.com/video/BV1ad4y1D7k5', '老番茄', '327.2万', '3.4万', '']
2022-08-02 14:03:20,378 - INFO: ['2', '【猛男版】小城夏天丨来看看我们生活的小城吧! 猛男舞团IconX', 'https://www.bilibili.com/video/BV1pW4y1y7AJ', '猛男舞团IconX', '194.6万', '2826', '']
2022-08-02 14:03:20,380 - INFO: ['3', '主席的牵挂 人民日报', 'https://www.bilibili.com/video/BV1wB4y187vU', '人民日报', '161.8万', '0', '']
2022-08-02 14:03:20,382 - INFO: ['4', '我一定会救你出去的! 麦咾源Bingo', 'https://www.bilibili.com/video/BV1Zr4y1V7L5', '麦咾源Bingo', '358.1万', '2052', '']
2022-08-02 14:03:20,384 - INFO: ['5', '【时代少年团】《哭泣的游戏》个人角色短片之《沉默怪兽》 TF家族', 'https://www.bilibili.com/video/BV1oG4y1e7Em', 'TF家族', '110.8万', '15.7万', '']
2022-08-02 14:03:20,386 - INFO: ['6', '忆往昔,一张戏台百家酬 惨爆了阿浩', 'https://www.bilibili.com/video/BV1ot4y1G73b', '惨爆了阿浩', '268.7万', '818', '']
2022-08-02 14:03:20,388 - INFO: ['7', '统帅深情 央视新闻', 'https://www.bilibili.com/video/BV1ig41117qQ', '央视新闻', '193.5万', '0', '']
2022-08-02 14:03:20,390 - INFO: ['8', '1块钱挑战!我跑遍杭州甚至买不到一瓶水! 康哟喂', 'https://www.bilibili.com/video/BV1pT411j7gW', '康哟喂', '458.7万', '1.4万', '']
......
Process finished with exit code 0