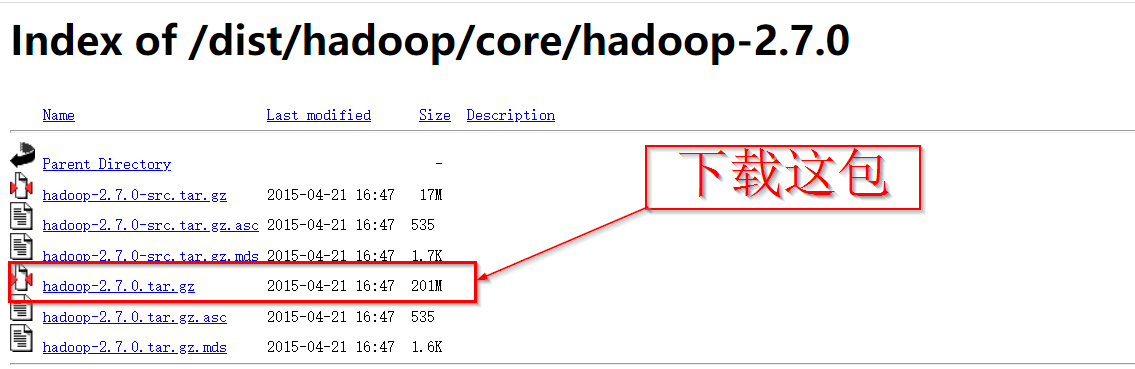
1:http://archive.apache.org/dist/hadoop/core/hadoop-2.7.0/ 下载Hadoop安装包到本地并解压
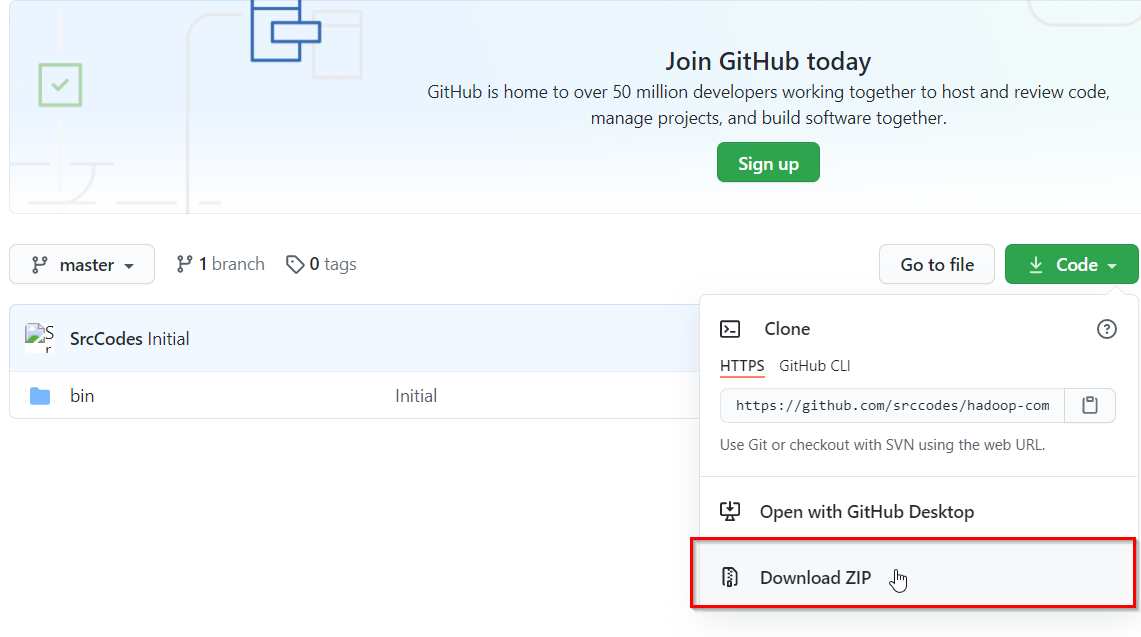
2: https://github.com/srccodes/hadoop-common-2.2.0-bin 下载这包.
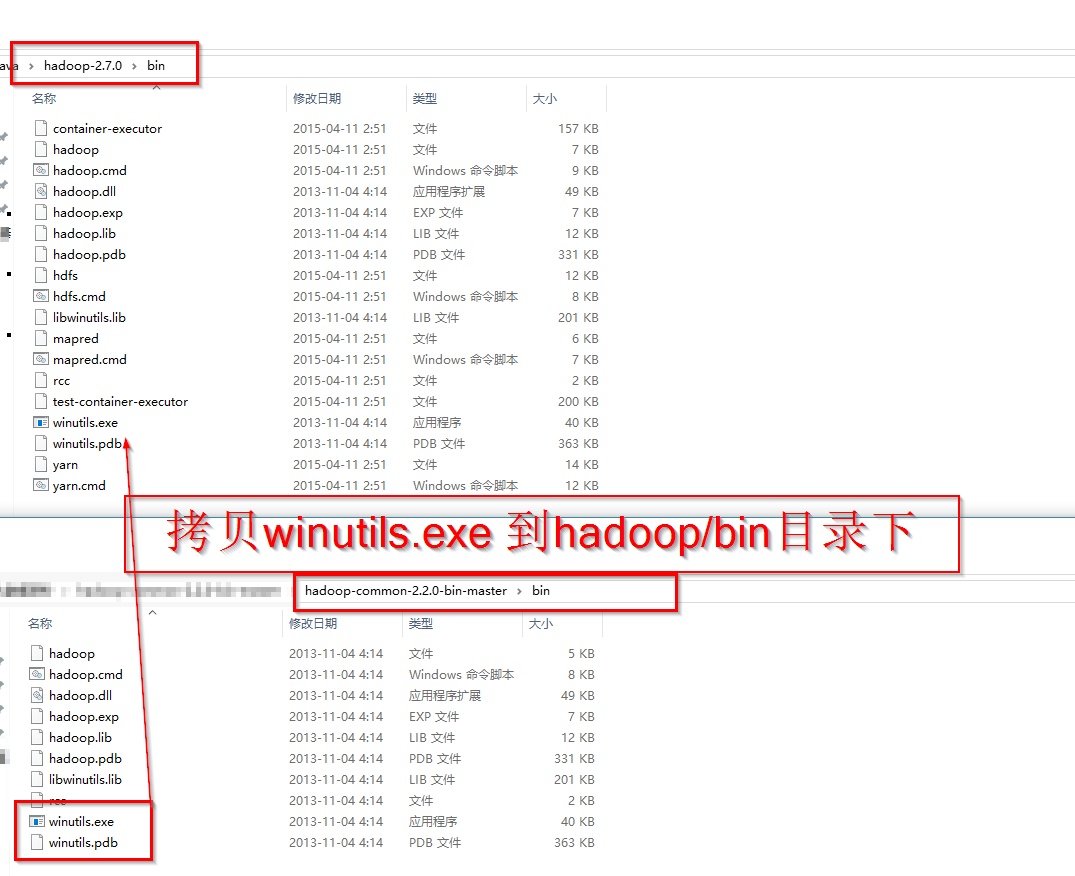
3: 将步骤2下载的bin包中的内容。解压缩到1步骤下载的hadoop包的bin目录下.
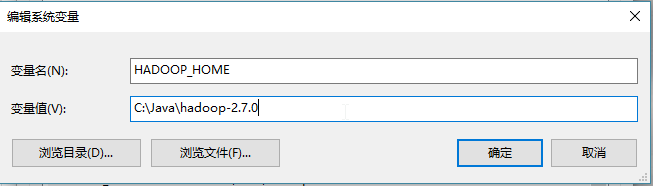
4:配置环境变量
添加HADOOP_HOME
添加path
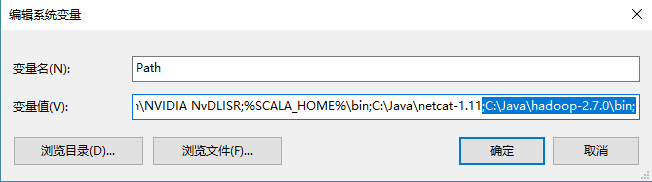
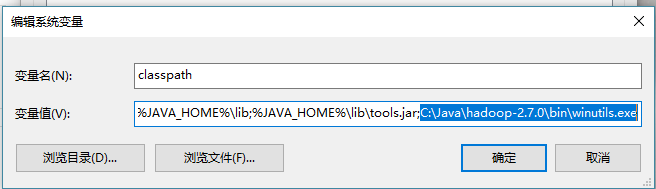
修改classpath.添加winutils.exe
5: idea创建Maven工程文件. POM文件添加:
<dependencies> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-core_2.11</artifactId> <version>2.4.3</version> </dependency> <dependency> <groupId>org.apache.spark</groupId> <artifactId>spark-sql_2.11</artifactId> <version>2.4.3</version> </dependency> </dependencies>
修改在IDEA中配置Run Configuration,添加HADOOP_HOME变量

main目录下创建scala文件夹(记得Mark Directory as sources root)。 添加Scala支持
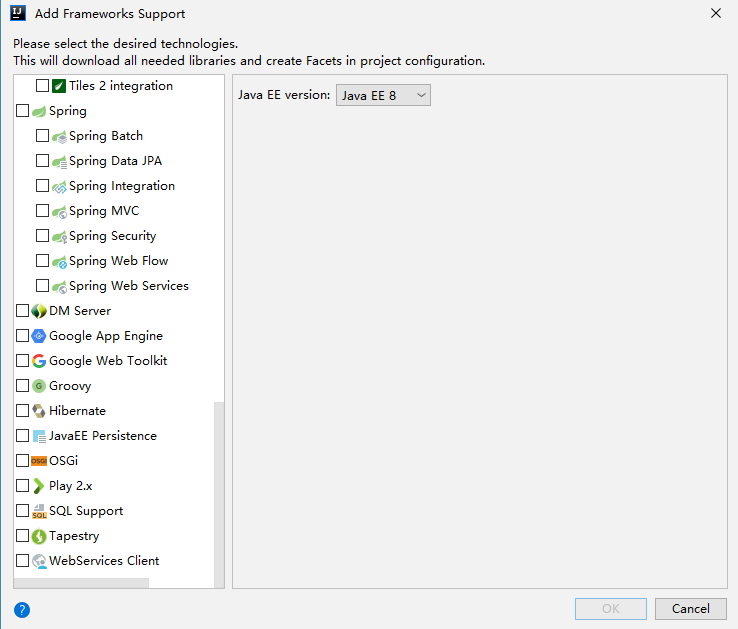
选中scala复选框.
6:添加log。在Resources目录下添加log4j.properties。这文件从spark conf目录下拷贝过来的。(log4j.properties.template)
# # Licensed to the Apache Software Foundation (ASF) under one or more # contributor license agreements. See the NOTICE file distributed with # this work for additional information regarding copyright ownership. # The ASF licenses this file to You under the Apache License, Version 2.0 # (the "License"); you may not use this file except in compliance with # the License. You may obtain a copy of the License at # # http://www.apache.org/licenses/LICENSE-2.0 # # Unless required by applicable law or agreed to in writing, software # distributed under the License is distributed on an "AS IS" BASIS, # WITHOUT WARRANTIES OR CONDITIONS OF ANY KIND, either express or implied. # See the License for the specific language governing permissions and # limitations under the License. # # Set everything to be logged to the console log4j.rootCategory=ERROR, console log4j.appender.console=org.apache.log4j.ConsoleAppender log4j.appender.console.target=System.err log4j.appender.console.layout=org.apache.log4j.PatternLayout log4j.appender.console.layout.ConversionPattern=%d{yy/MM/dd HH:mm:ss} %p %c{1}: %m%n # Set the default spark-shell log level to WARN. When running the spark-shell, the # log level for this class is used to overwrite the root logger's log level, so that # the user can have different defaults for the shell and regular Spark apps. log4j.logger.org.apache.spark.repl.Main=ERROR # Settings to quiet third party logs that are too verbose log4j.logger.org.spark_project.jetty=ERROR log4j.logger.org.spark_project.jetty.util.component.AbstractLifeCycle=ERROR log4j.logger.org.apache.spark.repl.SparkIMain$exprTyper=INFO log4j.logger.org.apache.spark.repl.SparkILoop$SparkILoopInterpreter=INFO log4j.logger.org.apache.parquet=ERROR log4j.logger.parquet=ERROR # SPARK-9183: Settings to avoid annoying messages when looking up nonexistent UDFs in SparkSQL with Hive support log4j.logger.org.apache.hadoop.hive.metastore.RetryingHMSHandler=FATAL log4j.logger.org.apache.hadoop.hive.ql.exec.FunctionRegistry=ERROR
7:添加wordcount源代码.(在scala目录下创建wordcount scala object)
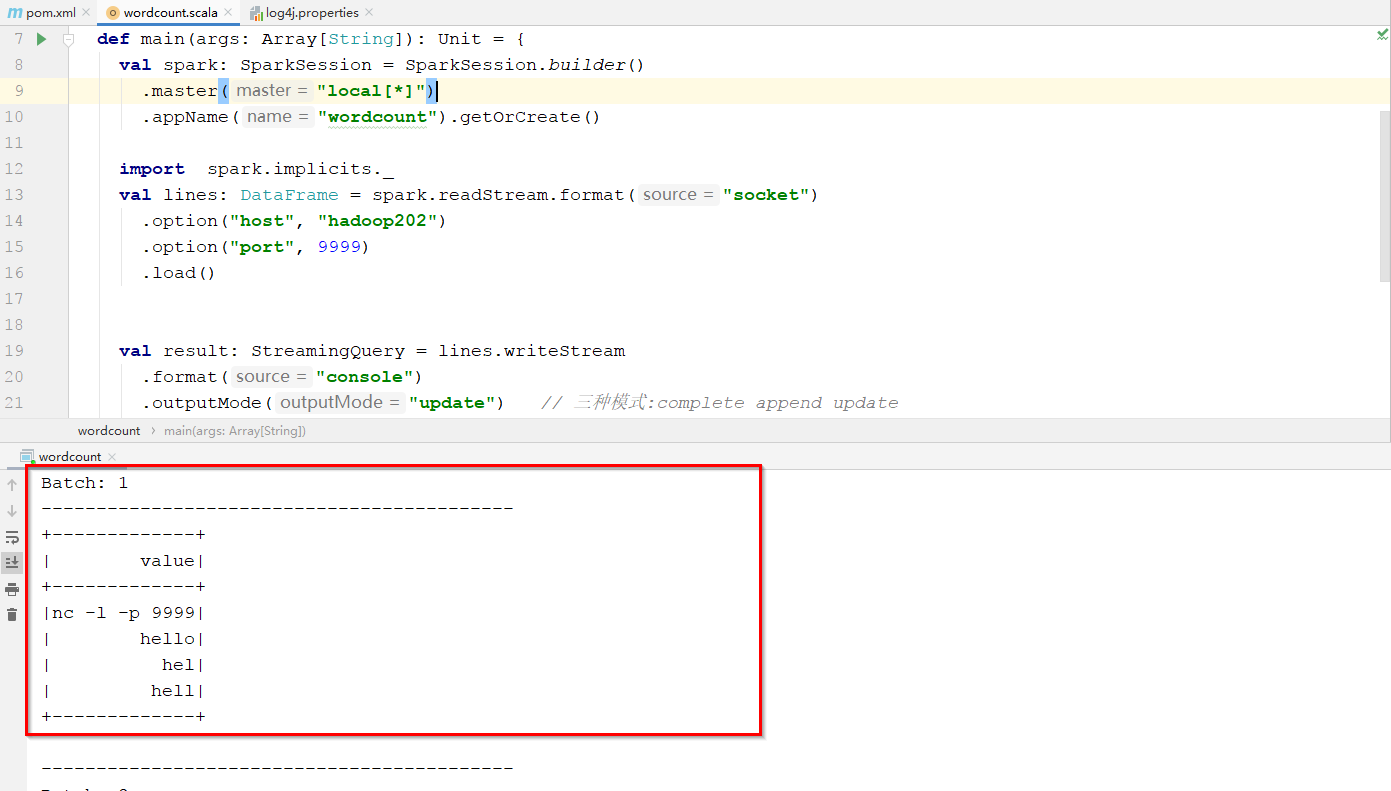
package com.atguigu.structure.streaming import org.apache.spark.sql.streaming.StreamingQuery import org.apache.spark.sql.{DataFrame, SparkSession} object wordcount { def main(args: Array[String]): Unit = { val spark: SparkSession = SparkSession.builder() .master("local[*]") .appName("wordcount").getOrCreate() import spark.implicits._ val lines: DataFrame = spark.readStream.format("socket") .option("host", "hadoop202") .option("port", 9999) .load() val result: StreamingQuery = lines.writeStream .format("console") .outputMode("update") // 三种模式:complete append update .start() result.awaitTermination() spark.stop() } }
8:启动netcat 程序 发送数据:
nc -l -p 9999
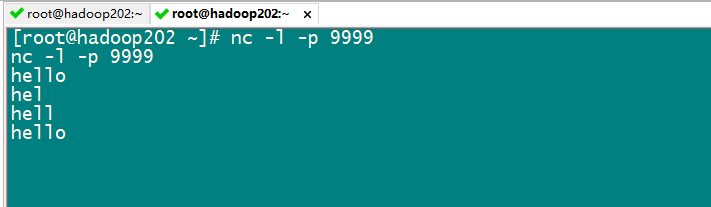
启动 wordcount:
9:常见错误:winutils.exe 错误

步骤1,2,3,4,5就可以解决。