需求:
1)与以前存在的样本名称相同的,筛选出来,这是重复样本,做减法,不后续实验
2) 重复样本中以前检测不合格的,加上,做后续实验。
准备工作:
1.unique的已存在样本列表
-
first_four_Sample<-read.csv("./first_four_Sample.csv") #如果有first_five文件,直接校验duplicatd就行 fifth<-read.csv("./five_uniq_第五批去重去异常.csv") View(first_four_Sample) View(fifth) fifth$客户样本名称 fifth$invSampleName<-fifth$客户样本名称 # 统一变量名,后续好对列操作 fifth$invSampleName first_five<-c(first_four_Sample$invSampleName,fifth$invSampleName) #合并向量 first_five first_five[duplicated(first_five)] # 保障uniq后,继续。 summary(first_five) #看有多少观测行
2. 本次入库待实验的样本
sixth<-read.csv("./sixth_2088_Sample.csv")
View(sixth)
sixth$invSampleName
first_six<-c(first_five,sixth$invSampleName)
summary(first_six)
first_six[duplicated(first_six)] #这里可以sixth_repeated<-first_six[duplicated(first_six)]。如果有dup则继续。为空的话直接全下检测单就行了
3. 之前检测不合格的样本
-
unqualified143<-read.csv("../143unqualified_1217.csv") View(unqualified143) intersect(unqualified143$客户样本名称,first_six[duplicated(first_six)]) #本次样本中需要弥补之前不合格的样本sixth_nonrepeate<-setdiff(sixth$invSampleName,first_six[duplicated(first_six)]) #本次入库的非重复样本 summary(sixth_nonrepeate)
sixth_need<-c(sixth_nonrepeate,supple_unqalified) #需要后续实验的所有样本 summary(sixth_need) sample_sixth<-data.frame(invSampleName=sixth_need) View(sample_sixth) #构建一个数据框,方便和后边数据框拼接inner_join
4. 拼接样本信息表及入库单编码。
-
sixth_code<-read.csv("./第六批入库单编码.csv") #入库单编码 View(sixth_code) sixth_sampleinfo<-read.csv("./入库第六次_2088样本.csv") #样本信息单 View(sixth_sampleinfo) sixth_code$invSampleName sampleinfo_code<-dplyr::inner_join(sixth_sampleinfo,sixth_code,by="invSampleName") #拼接两个数据框 View(sampleinfo_code) glimpse(sampleinfo_code) sampleinfor_code_nonextended<-sampleinfo_code %>% select(!starts_with("extended")) #extend太多列了,不需要 glimpse(sampleinfor_code_nonextended)
5. 生成需要的样本信息表
-
test6_need<-dplyr::inner_join(sampleinfor_code_nonextended,sample_sixth,by="invSampleName") #需要后续实验的样本信息表,注意sample_six在后,不然新增的前面质检不合格样本不与之前板号连续 View(test6_need) write_excel_csv(test6_need,"./test6_need.csv") repeat6<-first_six[duplicated(first_six)] #重复样本也保留 write.csv(repeat6,"./repeat_6th.csv")
新知识
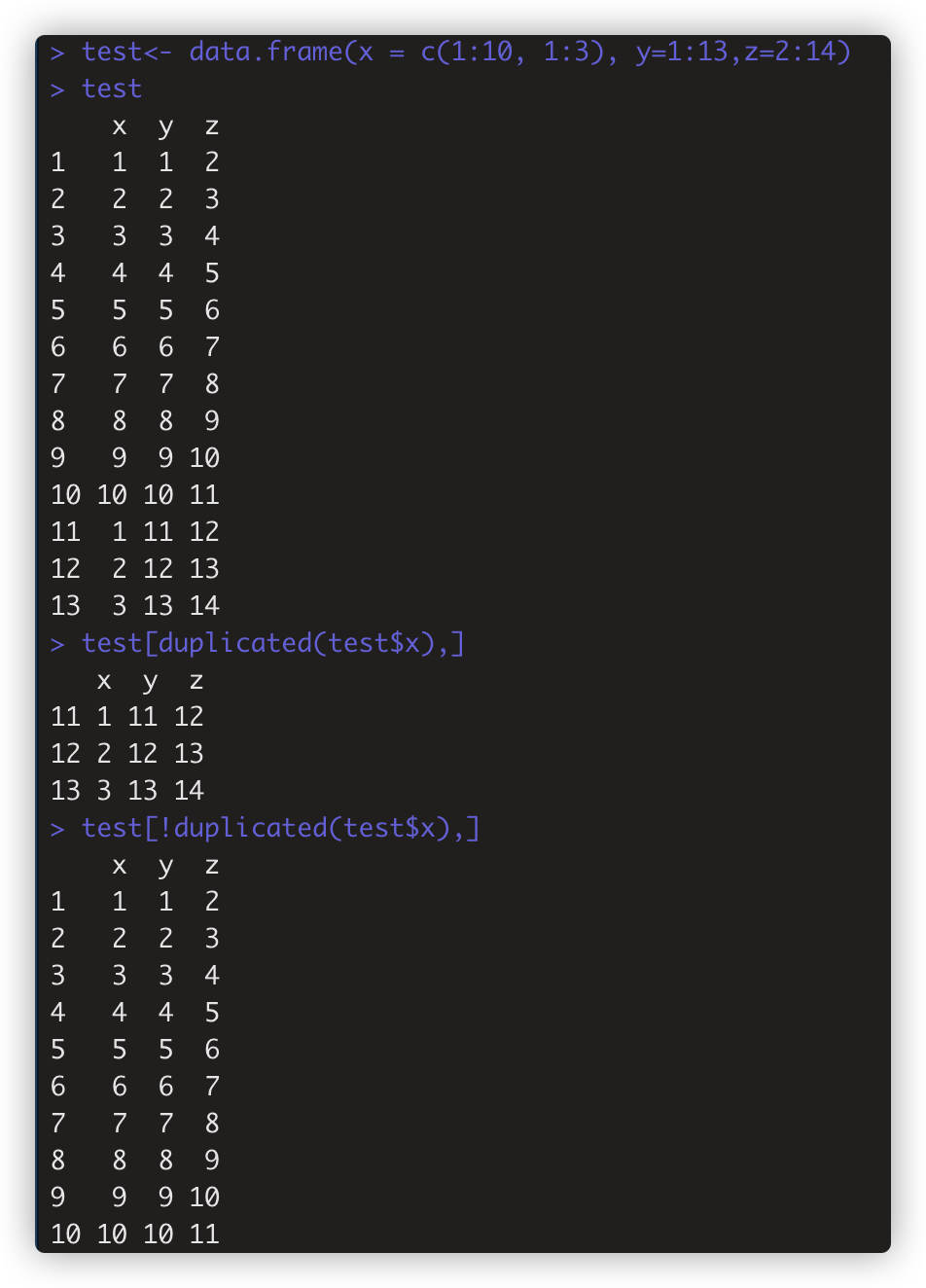
first_six[duplicated(first_six)] 取出向量的重复观测
数据框的话,如:
> test[!duplicated(test$x),] #与前面观测值 重复的行
> test[!duplicated(test$x),] #唯一观测,重复项取第一次出现的行。
intersect(x,y) 两个向量取交集
union(x,y) 取并集
setdiff(x,y) 取x-y 的部分集。
