本文转自:http://www.hankcs.com/nlp/cs224n-gru-nmt.html

 从动机层面直观地充实了GRU和LSTM的理解,介绍了MT的评测方法,讨论了NMT中棘手的大词表问题和一些常见与最新的解决办法。
从动机层面直观地充实了GRU和LSTM的理解,介绍了MT的评测方法,讨论了NMT中棘手的大词表问题和一些常见与最新的解决办法。



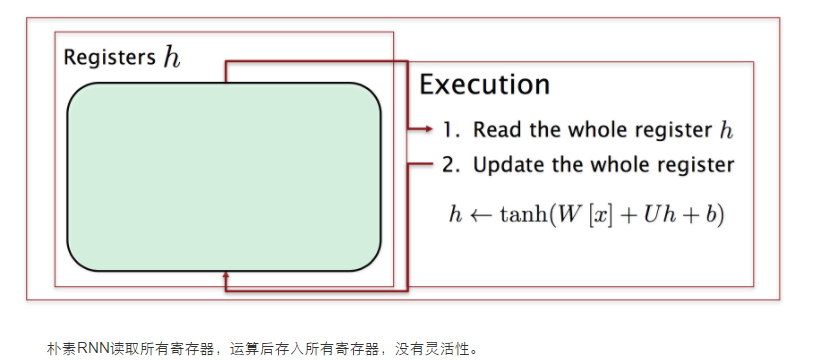
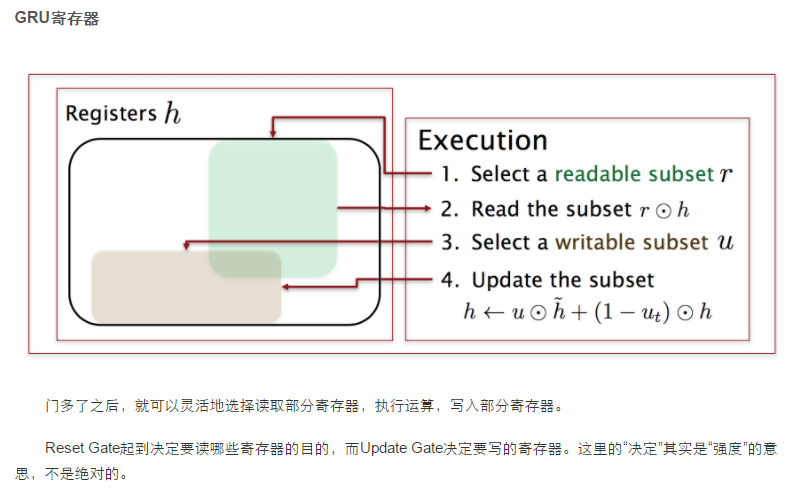

深入LSTM
宏观上的LSTM Cell:
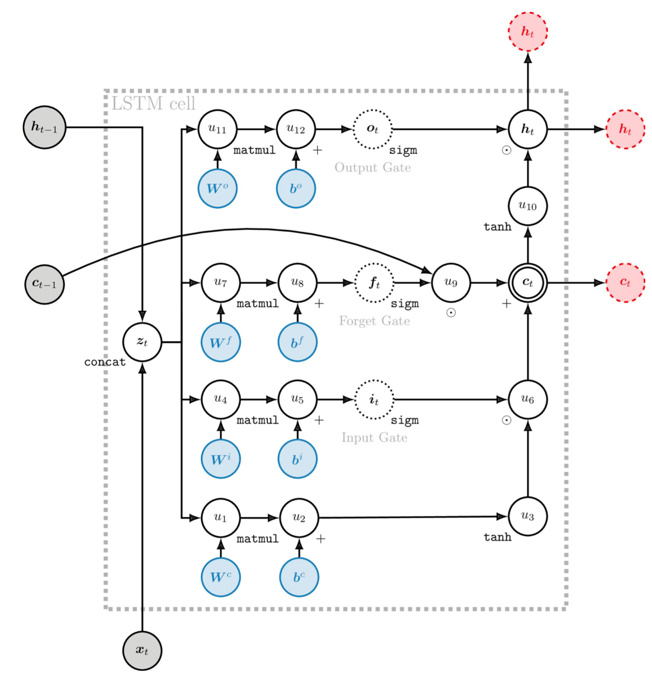
将所有操作都gate起来,方便遗忘甚至忽略一些信息,而不是把所有东西都塞到一起。

New Memory Cell的计算是一个非线性的过程,与朴素RNN一模一样:
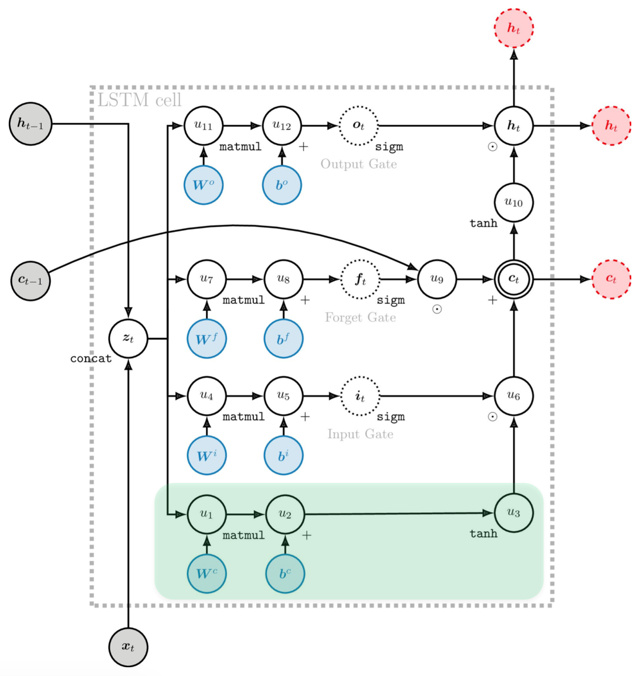
最关键之处在于,Memory Cell的更新中有一个加法项直接来自上一刻的Cell,也就是说建立了ctct和ct−1ct−1的直接线性连接(与ResNet类似):

类似于GRU中的加法,在反向传播的时候允许原封不动地传递残差,也允许不传递残差,总之是自适应的。
有了这些改进,LSTM的记忆可以比RNN持续更长的step(大约100):





一个具体的BLEU重叠例子:

为了防止某篇机翻实际上很好,可就是跟人类译文用词行文不相似的情况,IBM的论文建议多准备几篇标准答案,这样总会撞上一个:

当然了,虽然IBM建议准备4篇,实际测试中经常只有1篇。没有完美体现能力的考试,现实社会也是如此。
刚开始的时候,BLEU和人工打分几乎是线性相关(一致)的:
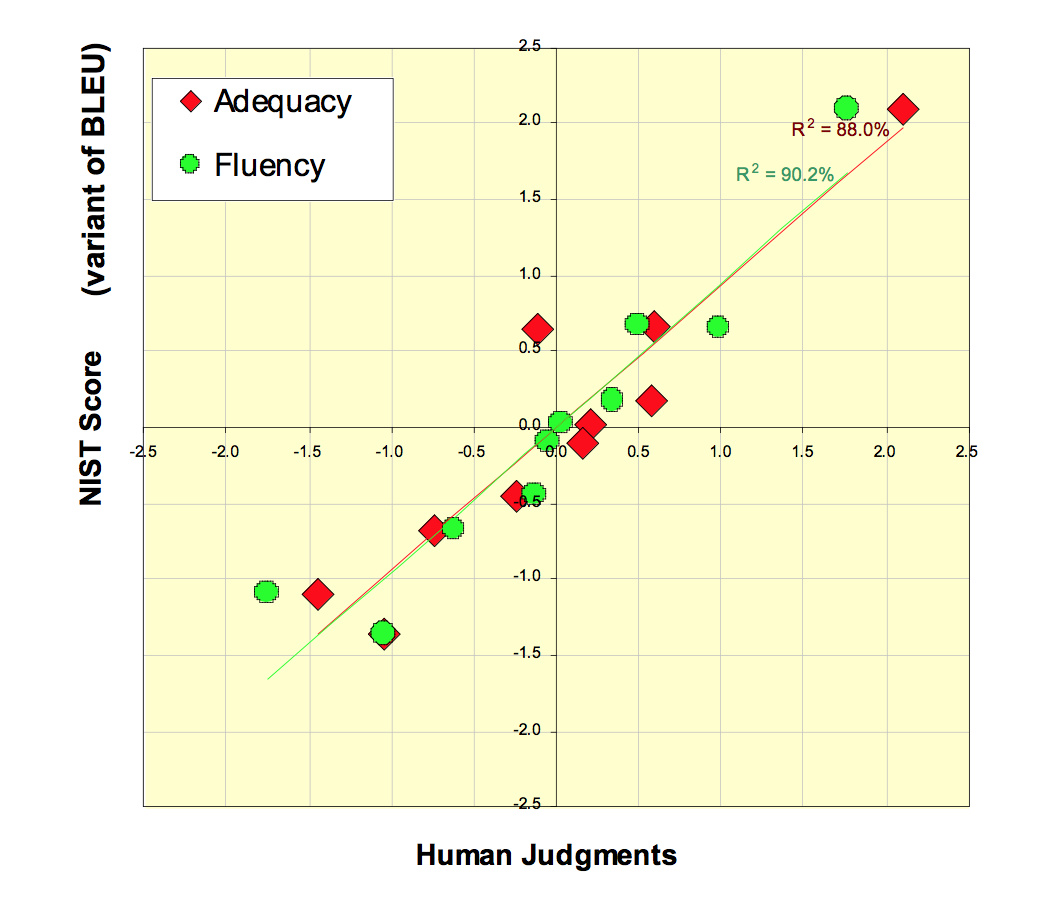
而当人们为了BLEU分数费尽心机之后,两者就开始脱钩了。这也是为什么Google翻译的效果没有宣称的那么好的原因之一。
解决大词表问题
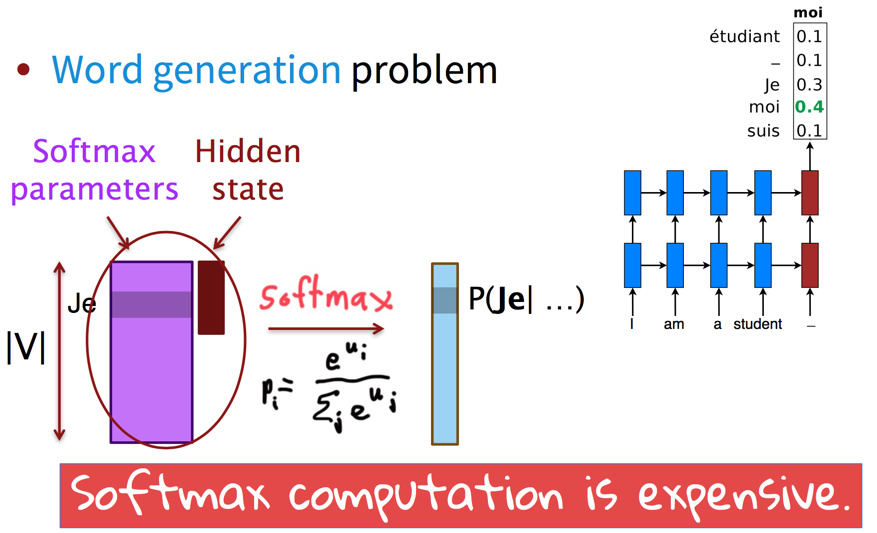
大词表问题指的是softmax的计算难度:
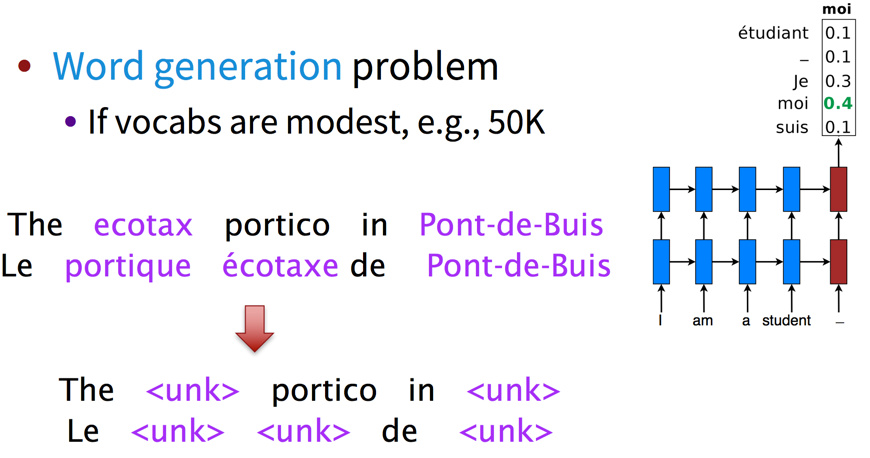
早期的MT系统会使用较小的词表,但这并不是解决问题,而是逃避问题。
另一种思路是,hierarchical softmax,建立树形词表,但这类方法过于复杂,让模型对树形结构敏感而不是对词语本身敏感。
另外就是上几次课见过的廉价的NCE,这些方法对GPU都不友好。
Large-vocab NMT
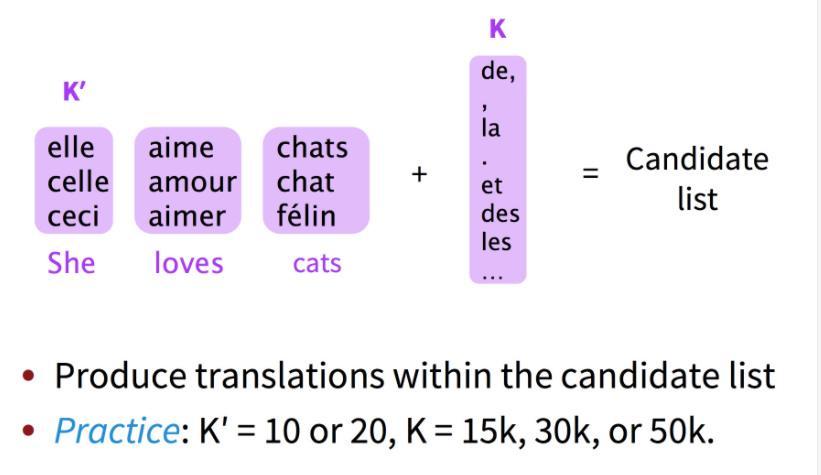
最新的方法是训练时每次只在词表的一个小子集上训练,因为40%的词语只出现一次,如果把训练数据均分为许多份,则每一份中的稀有词可能都不会在其他语料中出现。然后测试时加一些技巧,待会儿详谈。
训练

如何选择小词表呢?在刚才的方法上更进一步,让用词相似的文章进入同一个子集,这样每个子集的词表就更小了。



另有一些混合动力的NMT,大部分情况下在词语级别做翻译,只在需要的时候从字符级去翻译。这个系统的主体是词语级别的LSTM:
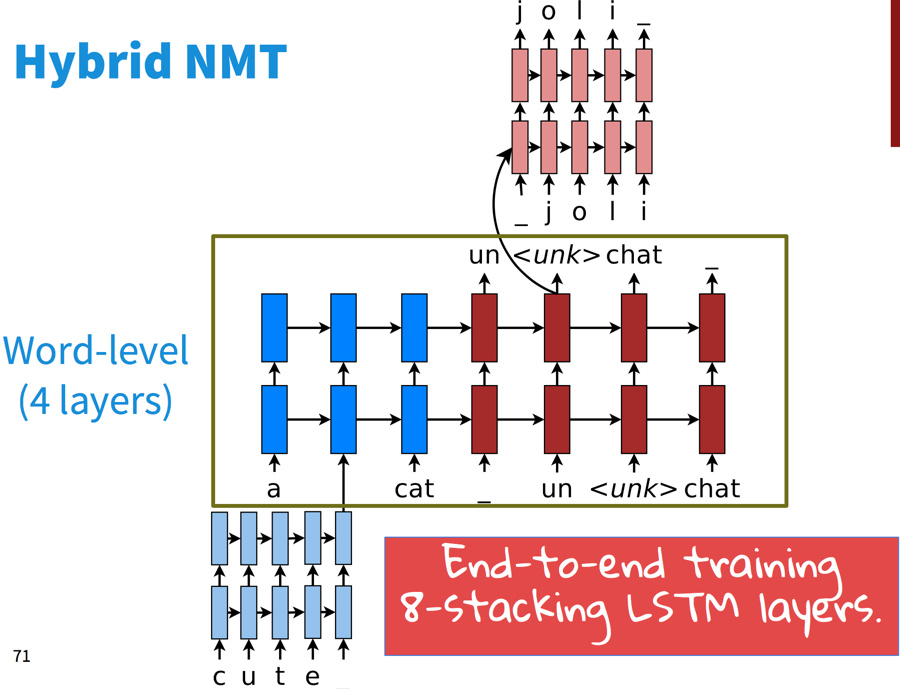
在词语级别上做常规的柱搜索:

一旦产生了unknown词语,则在字符级别进行柱搜索:

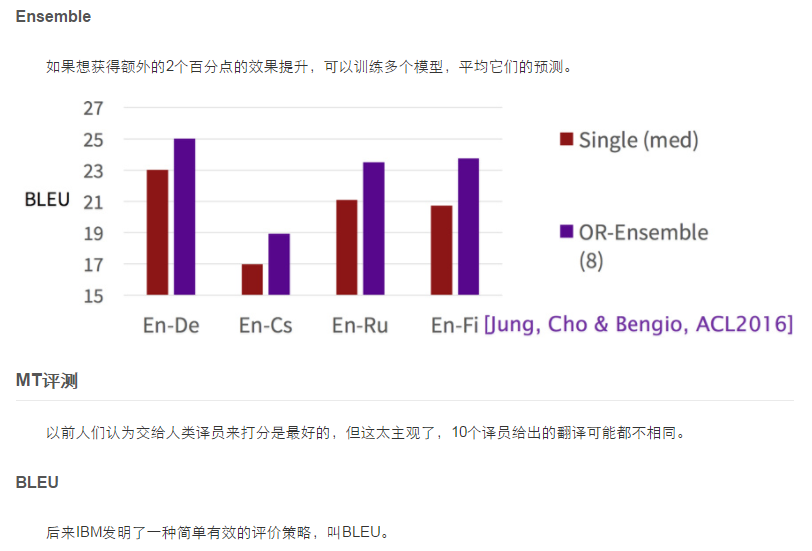
然后提升了两个BLEU分值。
