视频转码的算法在逐渐优化,软件转码消耗的时间也越来越多,

换算为pixels/second的话,可以看出更加明显的数量级的差异

描述一个这个卡的作用,同样的视频质量的话,传输带宽可以降低5倍;
1920*1080pixels*30frames/s*rgb32bit/10^6=1990Mbps=248MBps,不知道20Mbps是不是算错了。

自研的卡实现了两种转码算法:

编码核心,使用标准的256bit位宽的AXI数据总线,和32bit位宽的APB控制总线;
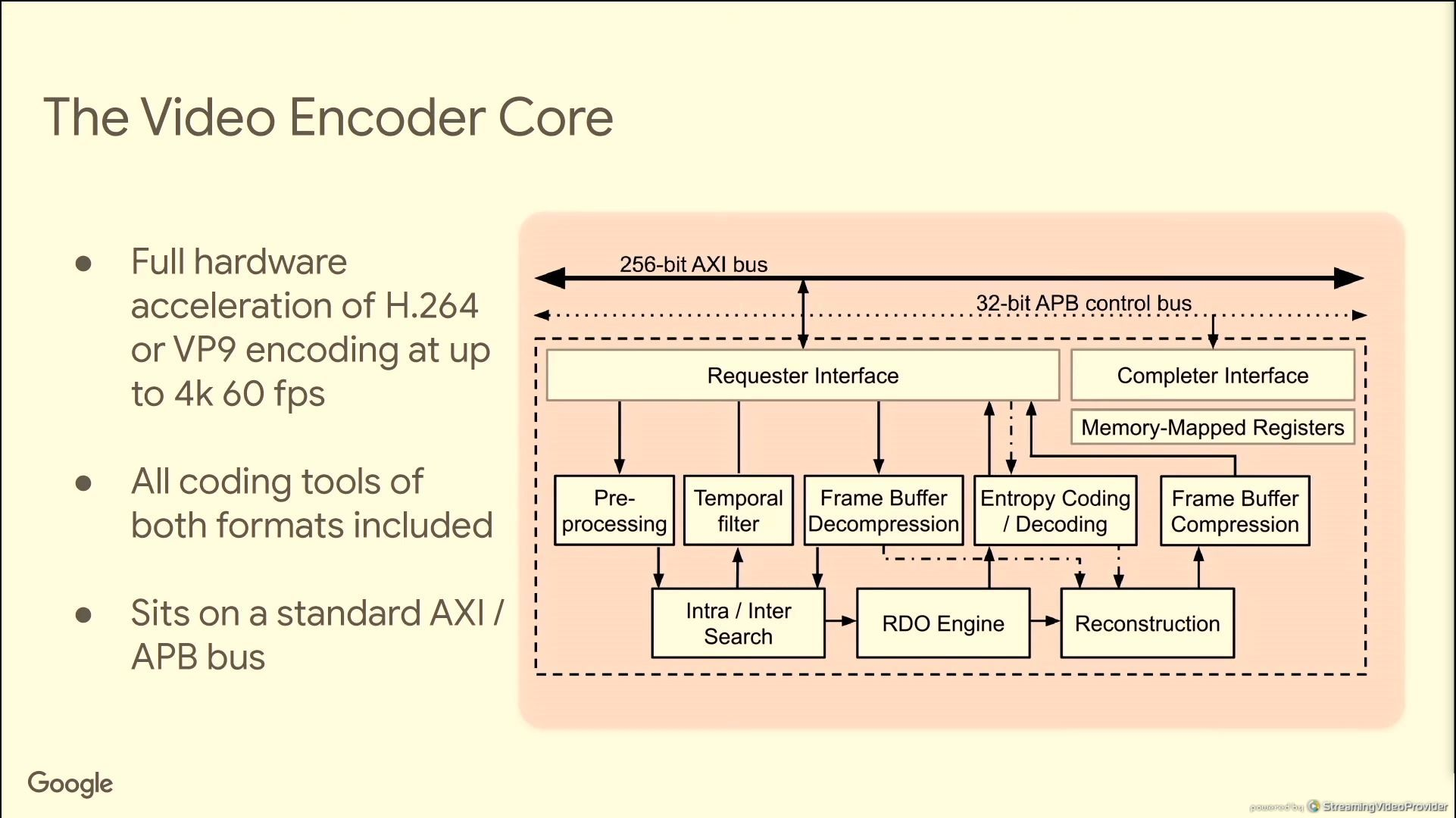
设计上采用了西门子的EDA的软件;

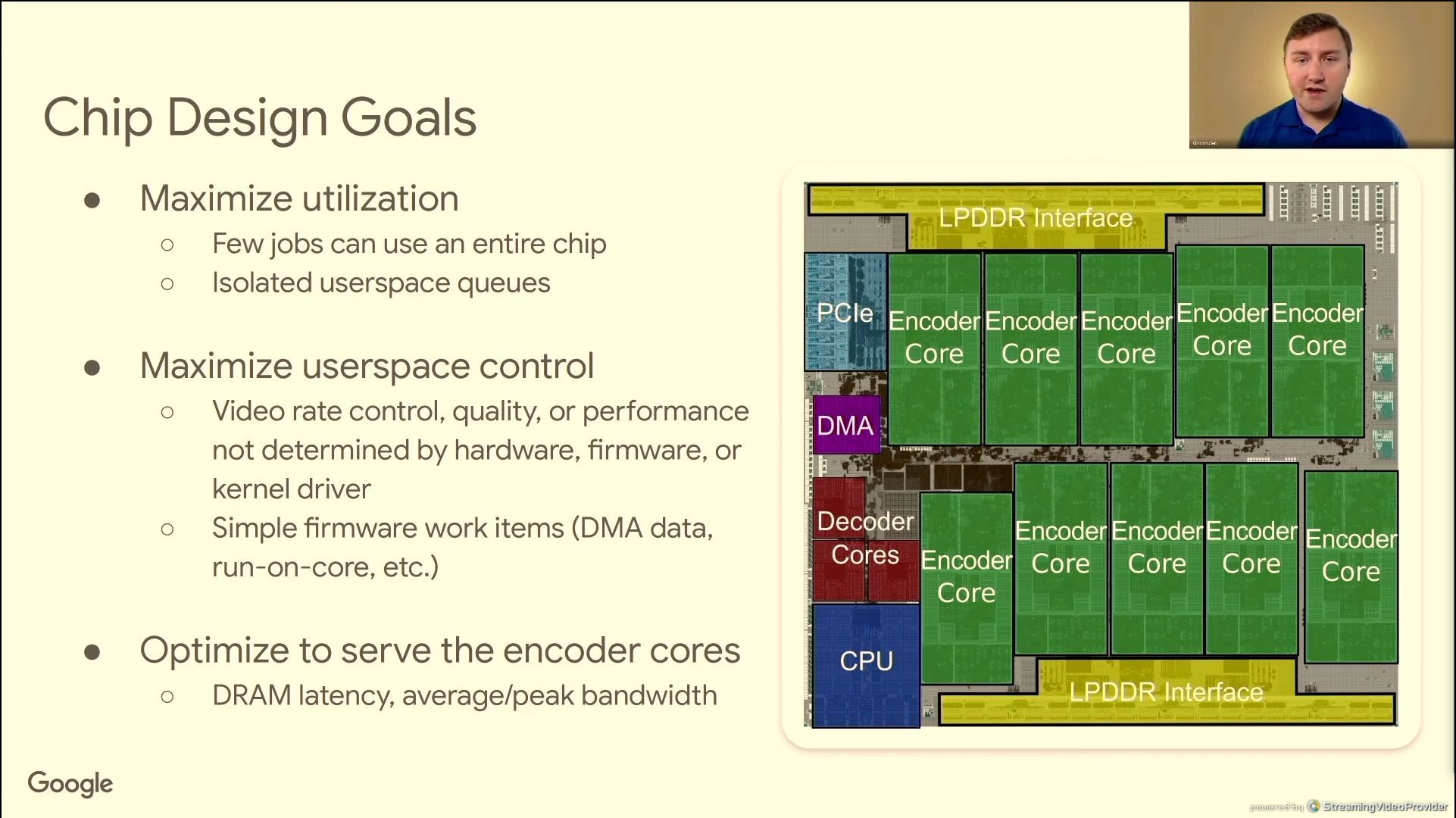
设计上的目标:1. 最大化利用效率;2. 最大化用户空间的控制;3. 为编码器优化带宽和延时
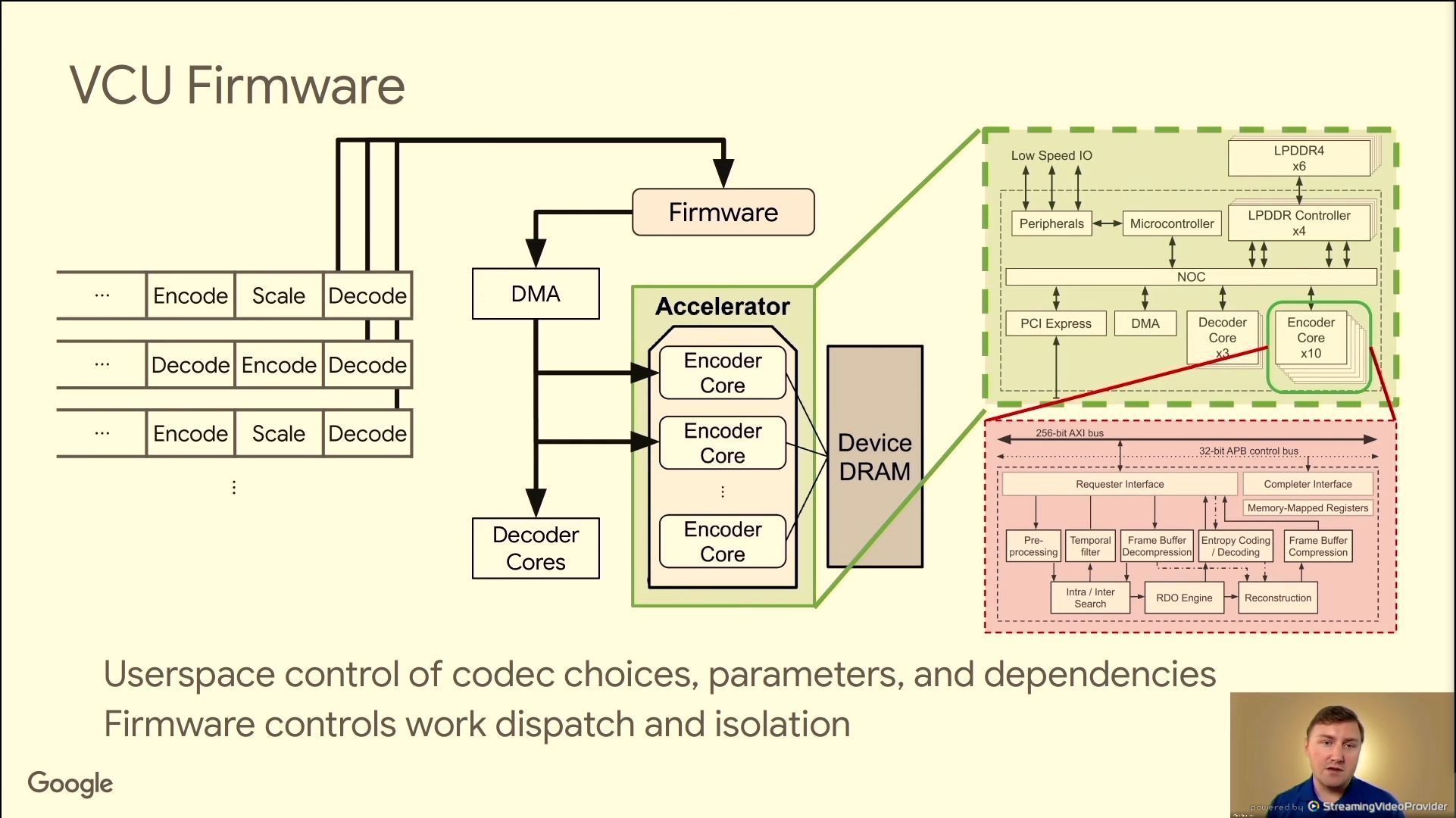
支持1个decode对应48个encode,也就是上传1个视频,转码成多种版本;
从下图可以看出,三个解码,十个编码单元;其他的控制器模块通过片上网络进行互联;

下面这个图具体描述一个片上互联网络的拓扑

用户空间控制转码的选择,固件控制了任务的分发和隔离。
解码的任务到达固件,转发给DMA引擎,然后到达加速器上的编码单元;这里重要的事解码帧的复用,可以提高编码的并发;
为了最大化Perf/TCO,每个卡支持2个ASIC,每个主板支持5个卡,每个host支持2个主板,因此一个host支持20个ASIC;

性能对比部分可以看到编码部分的增长是线性的,但是单输出转码因为受限解码模块的数量并不会很快,多输出转码反而是比单输出的情况下提高了1.2倍;

【这个卡设计的确实不是很好看】
参考文献:
THE END
2021年8月29日