1.选一个自己感兴趣的主题。
2.网络上爬取相关的数据。
3.进行文本分析,生成词云。
4.对文本分析结果解释说明。
5.写一篇完整的博客,附上源代码、数据爬取及分析结果,形成一个可展示的成果。
我选择主题是游戏资讯,爬取的网站是:http://www.gamersky.com/news/
爬取此网页中一些游戏新闻标题、发布时间、来源以及地址:
import requests from bs4 import BeautifulSoup from datetime import datetime import re url = 'http://www.gamersky.com/news/' res = requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.Mid2L_con'): for news2 in news.select('li'): if len(news2)>0: title=news2.select('.tt')[0]['title'] url=news2.select('.tt')[0]['href'] time=news2.select('.time')[0].text print('标题:',title) print('链接:',url) print('时间:',time)
效果如下图所示:
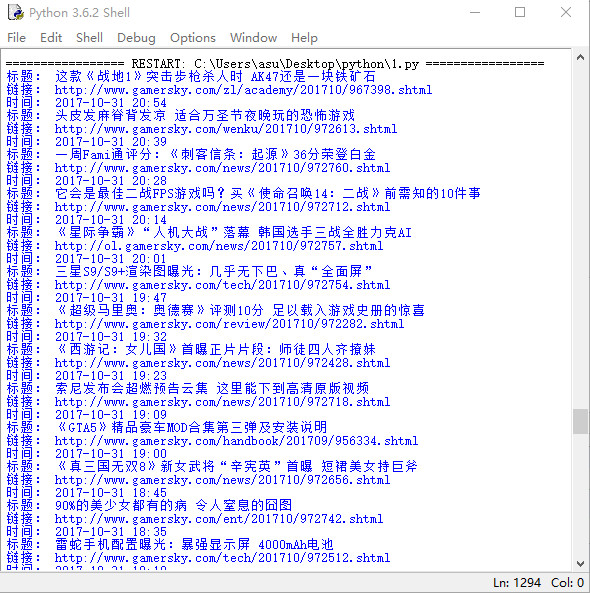
进行文本分析,生成词云:
import requests import jieba from bs4 import BeautifulSoup import re url = 'http://www.gamersky.com/news/' res = requests.get(url) res.encoding='utf-8' soup=BeautifulSoup(res.text,'html.parser') for news in soup.select('.Mid2L_con'): for news2 in news.select('li'): if len(news2)>0: title=news2.select('.tt')[0]['title'] url=news2.select('.tt')[0]['href'] resd=requests.get(url) resd.encoding='utf-8' soupd=BeautifulSoup(resd.text,'html.parser') p = soupd.select('p')[0].text #print(p) break words = jieba.lcut(p) ls = [] counts = {} for word in words: ls.append(word) if len(word) == 1: continue else: counts[word] = counts.get(word,0)+1 items = list(counts.items()) items.sort(key = lambda x:x[1], reverse = True) for i in range(10): word , count = items[i] print ("{:<5}{:>2}".format(word,count)) from wordcloud import WordCloud import matplotlib.pyplot as plt cy = WordCloud(font_path='msyh.ttc').generate(p)#wordcloud默认不支持中文,这里的font_path需要指向中文字体 plt.imshow(cy, interpolation='bilinear') plt.axis("off") plt.show()
效果如下图所示:

