@
0. Paper link
1. Overview
因为之前没有看论文《Instance-sensitive fully convolutional networks》,所以对这篇文章把卷积网络具有的translation invariance变为translation variance很innovation,文章最后我也会思考作者是如何提出的(假设作者完全独立提出这个结构)。
R-FCN是一个基于region、全卷积,具有较好的准确率与性能的目标检测网络。之前例如Faster-RCNN网络最后的分类网络都以AlexNet或者VGG作为backbone,R-FCN使用ResNet的全卷积部分作为backbone,并且引入position-sensitive score maps来消除分类网络translation invariance的性能,使它更适应于detection,他也是使用RPN与R-FCN共享feature同时生成ROI,也加入了多任务训练,与position-sensitive score maps有一条并行的分支用来做Bonding Box Regression,最后模型与Faster R-CNN性能相当但是在training与inference阶段更快。
2. position-sensitive score maps
2.1 Background
之前的detection网络中分类网络通常是AlexNet与VGG等,卷积层+几层全连接层,而那时候的state-of-the-art都是(fully convolutional)(除了最后一层是全连接层,但是应用在detection中是要被去掉/替换的),通过类比很容易构建一个全卷积共享参数的detection architecture,但是准确率很低,在ResNet的文章里在两部分conv层之间插入了RoI Pooling layer,虽然这样通过加深ROI-wise的子网络的深度提高了精度,但同时却降低了速度,因为在计算每一个RoI时计算不共享,ResNet原文的做法恰好是打破了原来网络的 translation invariance, 在ROI pooling前都是卷积,是具备平移不变性的,但一旦插入ROI pooling之后,这种“region-specific”使后面的网络结构就不再具备平移不变性了(文章解释:no longer translation-invariant when evaluated across different regions.),但是效率低
2.2 position-sensitive score maps
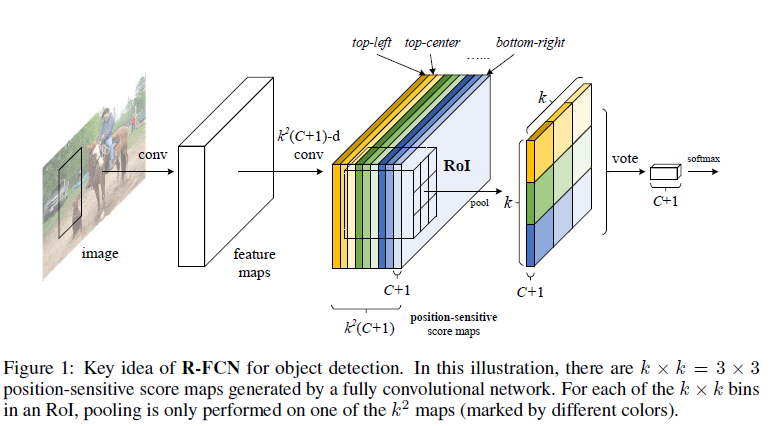
上图是R-FCN的核心idea,可以看到中间的position-sensitive score maps有(k^2(C+1))层channels,其中作者把ROI分成(k×k)的feature,其中(k)是边长,因此 position-sensitive score maps中的(k^2)指的是ROI中的(k^2)个“空间位置”,对于每个“空间位置”有(C+1)个通道,(C)是类别(+1个background),通过position-sensitive ROI pooling layer产生一个(k×k×(C+1))的feature(共(k×k)个空间位置,每个“空间位置”只学习一次),同时通过end-to-end training,ROI layer可以监督最后一层卷积层来学习position-sensitive score maps,最后通过vote的方法进行分类。
position-sensitive score maps包含物体的位置信息,其顶端设有RoI Pooling层来处理位置信息,所以对位置敏感,不具有平移不变性,之后再没有权重层。这样,RFCN就将几乎所有的计算都共享,可以达到比faster rcnn快2.5-20倍。
3. Architecture
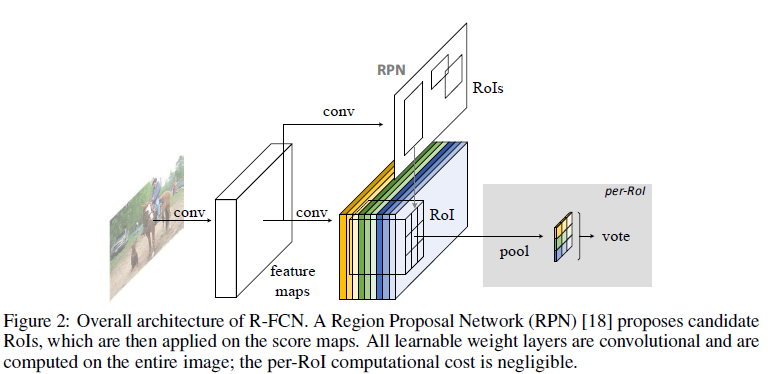
在R-FCN中,RPN与R-FCN是共享feature的,RPN用来生成ROI,R-FCN用来分类区别前景还是后景,在R-FCN中所有需要学习权重的层都是卷积层并且针对整个图片做卷积,在position-sensitive score maps之后没有需要学习权重的层了。
3.1 backbone
ResNet-101 网络有100个卷积层,1个全局平均池化层和1个1000类的全连接层。仅用ImageNet预训练的该网络的卷积层计算特征图。
3.2 Position-sensitive score maps & Position-sensitive RoI pooling
之前提到了position-sensitive score maps有(k × k)个“空间位置”,因此需要把每个矩形ROI分成(k × k),假设ROI是(w × h),那么每个bin的size大约是 (frac{w}{k} × frac{h}{k}),在R-FCN中最后一层卷积层每个类别生成 (k^2)score maps,对第((i, j))-th score map((0 leq i, j leq k-1))做池化可以表示如下:
其中,做的是average pooling,(r_c(i, j))代表在((i, j))位置第(c)个类别池化后的数值,(z_{i,j,c})是((i, j))位置第(c)个类别的feature map,(x_0, y_0)代表ROI的左上角, n是这个bin(空间位置)所有像素的数量, (Theta)是所有网络需要学习的参数, 另外(lfloor i frac{w}{k}
floor leq x < lceil (i+1)frac{w}{k}
ceil), (lfloor j frac{h}{k}
floor leq y < lceil (j+1)frac{h}{k}
ceil)
如图之前的两个图,池化之后生成了一个 (k×k×(C+1))的position-sensitive score,然后可得每个类别的总得分:(r_c(Theta) = sum_{i, j} r_c(i, j | Theta)),一共(C+1)维向量,之后可以得到交叉熵损失函数:(s_c({Theta}) = e^{r_c{(Theta)}} / sum_{c` = 0}^{C} e^{r_c`}(Theta)) ,在训练时候用作交叉熵损失函数, 在inference时候用过对ROI进行排序。
同样的网络中也使用了回归层用于位置精修,与(k^2(C+1)) 个通道的score map并列,另外再使用(4k^2) 个通道的score map,同样是 (k^2) 组,只不过每一组现在变成了4个通道,代表着坐标的四个值。最后PS ROI Pooling之后的feature map是 (4×k×k)的,average voting之后生成一个 4维的向量,代表着 bounding box位置的四个值 (t=(tx,ty,tw,th)) ,分别为中心坐标,和宽高。这里使用的是类别不明确的回归(class-agnostic bounding box regression) ,也就是对于一个ROI只输出 一个(t)向量,然后与分类的结果结合。实际上也可以使用类别明确的回归(class-specific ) ,这种回归方式对一个 ROI 输出 (C)个(t) 向量,也就是说每一类别都输出一个位置向量,这跟分类时每一个类别都输出一个概率是相对的。
PS:以下内容摘取arleyzhang,总结的真的好。
3.3 Training
损失函数
其中(c^*)代表GT label,(L_{cls}(s_{c^*}) = -log(s_{c^*})), (L_{reg})是跟R-CNN中的一样。文章设置(lambda = 1), 正负样本的IOU阈值为0.5
训练方法与参数设置
- It is easy for our method to adopt online hard example mining (OHEM) during training. Our
negligible per-RoI computation enables nearly cost-free example mining. - We use a weight decay of 0.0005 and a momentum of 0.9.
- By default we use single-scale training: images are resized such that the scale (shorter side of image) is 600 pixels [6, 18].
- Each GPU holds 1 image and selects B = 128 RoIs for backprop. We train the model with 8 GPUs (so the effective mini-batch size is 8×).
- We fine-tune R-FCN using a learning rate of 0.001 for 20k mini-batches and 0.0001 for 10k mini-batches on VOC. To have R-FCN share features with RPN (Figure 2), we adopt the 4-step alternating training, alternating between training RPN and training R-FCN.
3.4 Inference
- an image with a single scale of 600.
- During inference we evaluate 300 RoIs.
- The results are post-processed by non-maximum suppression (NMS) using a threshold of 0.3 IoU , as standard practice.
3.5 À trous algorithme
带孔卷积(L.-C. Chen, G. Papandreou, I. Kokkinos, K. Murphy, and A. L. Yuille. Semantic image segmentation with
deep convolutional nets and fully connected crfs. In ICLR, 2015.):与FCN一样,本文也将网络的整体降采样步长改为了16,增大了score map的分辨率。原先ResNet的Conv1-Conv5每一组都是2倍的降采样,总共是32倍降采样。本文中将Conv5的降采样倍数改为了1,提高了分辨率,这样整个结构是16倍的降采样,为了弥补由于降采样倍数改动导致网络后面的卷积层的感受野发生变化,文章使用了 À trous 技巧,也就是带孔卷积,不过带孔卷积只在Conv5中使用,Conv1-Conv4保持原来的不变,因此RPN不受影响。
带孔卷积对整个检测结果的影响还是蛮大的,如下是 R-FCN (k × k = 7 × 7, no hard example mining)的结果对比,带孔卷积提高了2.6个百分点。

3.6 Visualization
将score map可视化


4. Experiments
4.1 Pascal VOC
试验条件:
- 类别C=20
- 训练集:VOC 2007 trainval and VOC 2012 trainval (“07+12”)
- 测试集:VOC 2007 test set
- 性能衡量指标:mean Average Precision (mAP)
首先对比一些用于目标检测的 不同全卷积网络设计策略 的结果,以下是一些 不同的全卷积设计策略:
-
Naïve Faster R-CNN. 使用了Conv1-Conv5作为base部分,用于特征提取,ROI直接映射在Conv5最后输出的feature map上,与图2类似,不一样的地方在于:ROI池化之后加了一个 21维的全连接层。使用了 The àtrous 技巧。是一个近似的全卷积网络。
-
Class-specific RPN. 与标准的Faster R-CNN中使用的RPN类似,RPN训练方法也一样,不一样的在于:RPN部分不是一个二分类,而是一个类别为21的多分类。 为了对比公平,RPN的head使用的是 ResNet-101的 Conv5 层,也使用了àtrous 技巧。注意这个只是Faster R-CNN中的RPN,是一个全卷积网络。
-
R-FCN without position-sensitivity. 在图4的结构中设置k = 1,就跟图2是一样的,只是ROI池化的尺寸变成了 1×1 ,相当于全局池化。使用了àtrous 技巧。这是一个全卷积网络。
先展示一个 baseline的结果,如表1。这是使用 ResNet101 的标准 Faster R-CNN的测试结果。 我们只关注与本文本节实验条件相同的项,也就是红色方框框起来的那一行。可以看到mAP是 76.4%。标准的 Faster R-CNN 结构我们上面说过,首先这不是一个全卷积网络,其次 ROI pooling位于Conv4 和 Conv5之间, head 部分没有共享计算。
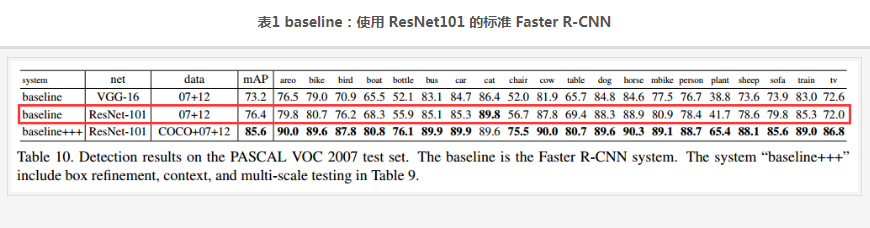
以上提到的三种全卷积设计策略的结果对比如表2:
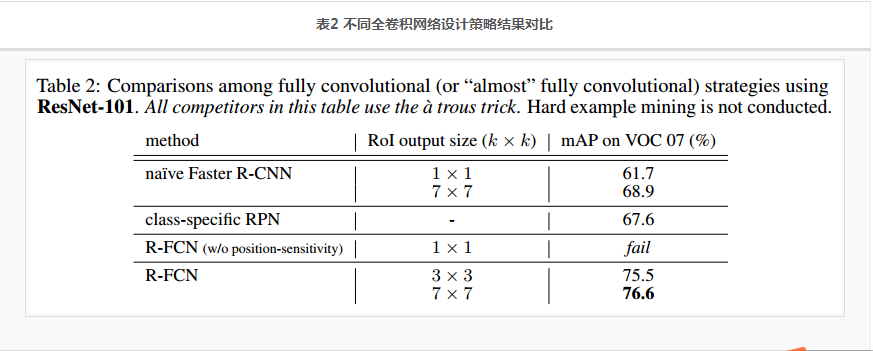
- Naïve Faster R-CNN的结果最高只有 68.9%,与标准 Faster R-CNN相比,说明 将ROI pooling放置在Conv4 和 Conv5之间,是有效保证位置信息的关键。而深层的全卷积网络损失了位置信息,对位置不敏感。
- Class-specific RPN的结果是67.6%,这实际上相当于特殊版本的 Fast R-CNN,相当于在head部分使用了sliding window的稠密检测方法。
- R-FCN without position-sensitivity直接fail,不及格,应该是连50%都不到,因为文中提到这种情况下网络不能收敛,也就是说这种情况下,从ROI中提取不到位置信息。这个跟 Naïve Faster R-CNN 的1×1 ROI输出的版本挺像的,不一样的是 Naïve Faster R-CNN中加了全连接层,而且Naïve Faster R-CNN是可以收敛的,只是精度比标准的低很多。
- R-FCN的mAP分别为 75.5和76.6,使用 7×7 ROI输出时,超过了标准的 Faster R-CNN。与R-FCN without position-sensitivity相比 ,说明Position-sensitive RoI pooling 起作用了,它可以对位置信息进行编码。
经过以上的试验分析,基本可以确定了 R-FCN with RoI output size 7 ×7 的效果是最好的。 以下的试验中涉及到 R-FCN的都采用这样的设置。
表3 是 Faster F-CNN 与 R-FCN 的 测试结果对比:

- depth of per-RoI subnetwork 指的是 head部分的深度,这里Faster F-CNN使用的是 ResNet101 版本的,Conv5有9个卷积层,再加一个全连接层,共10层。而R-FCN的head就是PS ROI Pooling和全局平均值池化,所以深度为0;
- online hard example mining 是否使用了OHEM策略进行训练,这个策略并不会额外增加训练时间,这个训练方式有待研究。
- 可以看到 R-FCN不管是训练还是测试都要比 Faster R-CNN快很多,平均精度也部落下风。
- 很明显的看到,当 ROI 数量是300时,Faster R-CNN训练平均一张图片需要1.5s,R-FCN需要0.45s;而当ROI 数量为300时,Faster R-CNN训练平均一张图片需要2.9s,R-FCN需要0.46s。Faster R-CNN的训练时间受 ROI是数量影响很大,而R-FCN几乎没有影响,只增加了0.01s。这也是使用全卷积,和 PS ROI Pooling 带来的好处。然而增加 ROI 数量并没有良好的精度收益。所以后面的试验中基本上都是使用的是 300个ROI。
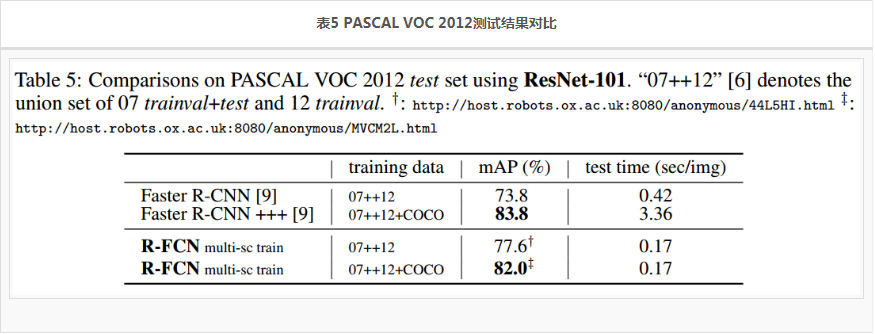
更多的测试结果,见表4,表5.
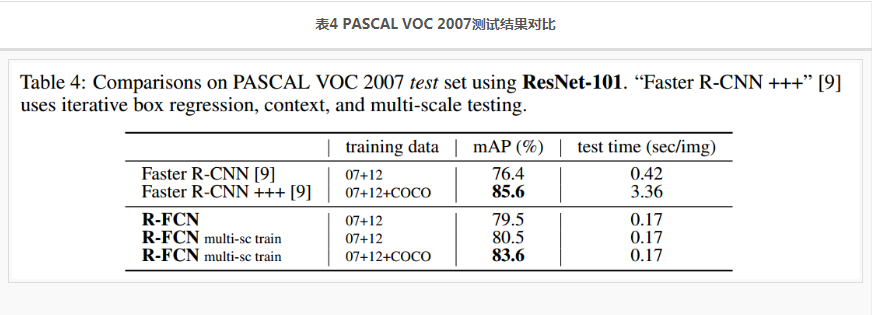
- multi-scale training :resize the image in each training iteration such that the scale is randomly sampled from {400,500,600,700,800} pixels. And still test a single scale of 600 pixels, so add no test-time cost. 使用这个策略后 mAP80.5。
- 如果先在COCO 数据集(trainval set )上训练,然后再 PASCAL VOC数据集上 fine-tune,可以获得 83.6%的mAP。但是精度不敌使用了各种技巧的 Faster R-CNN+++。但也不差。Faster R-CNN+++是ResNet论文中提出的。注意R-FCN并没有使用相应的技巧,比如 iterative box regression, context, multi-scale testing.
- Faster R-CNN+++虽然精度高,但是速度慢,简直被R-FCN 吊打,R-FCN的0.17s比Faster R-CNN+++快20倍。
- 表5展示了 PASCAL VOC 2012的测试结果,结论基本差不多,R-FCN精度稍逊Faster R-CNN+++,速度吊打Faster R-CNN+++。不过与 Faster R-CNN相比,精度还是高出很多的。
ResNet深度对检测结果的影响见表6:
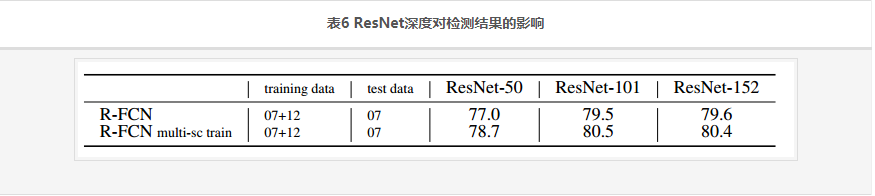
- 从50到101,精度是上升的,但是到152就趋于饱和了。
不同的 region proposal 方法对检测精度的影响,见表7:
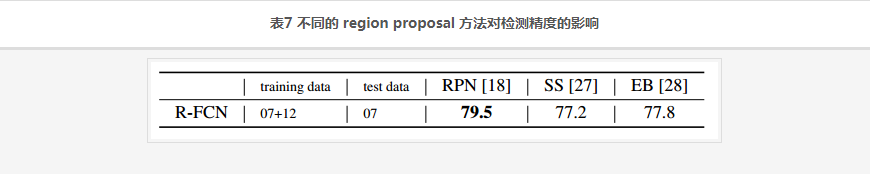
- SS: Selective Search , EB: Edge Boxes , RPN最牛。
4.2 MS COCO
试验条件:
- 总类别数 C=80;
- 80k train set, 40k val set, and 20k test-dev set;
- 评价指标:AP@[0.5; 0.95],指的是阈值在0.5到0.95之间的平均精度(average precise);AP@0.5,指的是阈值为0.5的平均精度(average precise)。
训练方法,直接把原文的搬过来:
- We set the learning rate as 0.001 for 90k iterations and 0.0001 for next 30k iterations, with an effective mini-batch size of 8.
- We extend the alternating training [18] from 4-step to 5-step (i.e., stopping after one more RPN training step), which slightly improves accuracy on this dataset when the features are shared;
- we also report that 2-step training is sufficient to achieve comparably good accuracy but the features are not shared.
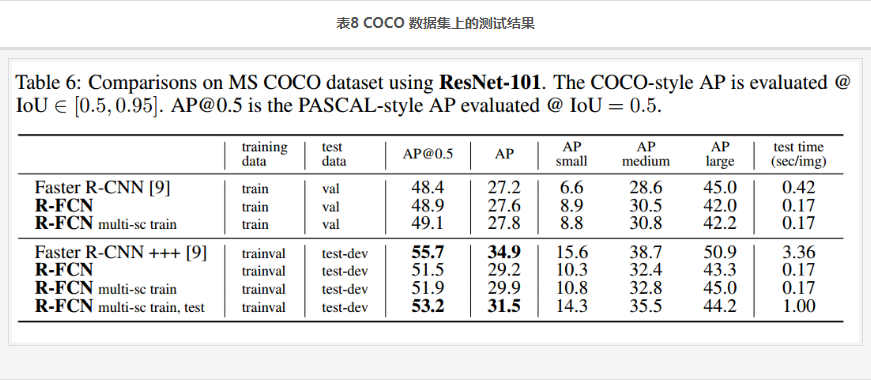
- multi-scale testing variant following ResNet’s Faster R-CNN, and use testing scales of {200,400,600,800,1000}
- 结果也是类似的 精度不敌 Faster R-CNN+++,速度吊打Faster R-CNN+++。注意R-FCN并没有使用 iterative box regression, context等技巧。
5. Conclusion
文章结合Faster R-CNN和FCN,提出了一个简单高效的网络 R-FCN,可以达到与 Faster R-CNN几乎同等的精度,而速度比Faster R-CNN快2.5-20倍。
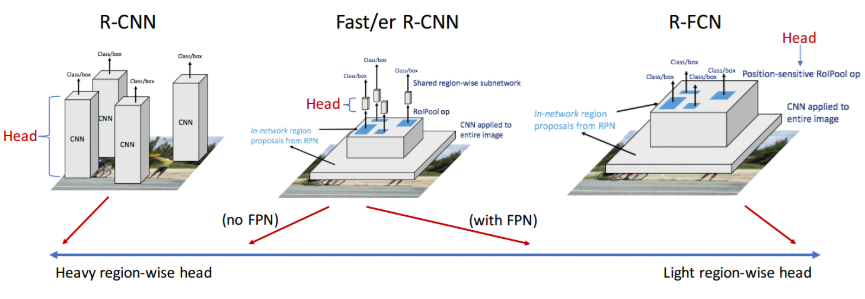
从 R-CNN, Fast/er R-CNN 到 R-FCN,改进的路线主要就是为了实现共享计算:
- R-CNN :ROI(Region of Interest)直接在原图上提取(使用 seletive search算法),每个ROI都通过 base和head进行计算。每个ROI的特征提取和最终分类都不共享计算。
- Fast R-CNN :ROI直接在原图上提取(使用 seletive search算法),将ROI映射到base部分最后一个卷积层,然后每个ROI就只通过 head 部分,head由几个全连接层构成。ROI之间的特征提取共享计算,ROI生成与base部分不共享计算,ROI通过head部分也不共享计算。
- Faster R-CNN :ROI 通过RPN(Region Proposal Network)提取,RPN与base共享特征提取层,将ROI映射到base最后一个卷积层,然后每个 ROI 只通过 head部分,head由卷积层 和或 全连接层构成。ROI之间的特征提取共享计算,ROI 提取与base部分共享计算,ROI通过head部分不共享计算。
- R-FCN:ROI通过RPN提取,提取之后的ROI仍然只通过一个网络(FCN),实现计算共享,分类层和回归层直接作用于最后一个卷积层。ROI之间的特征提取共享计算,ROI 提取与base部分共享计算,ROI通过head部分共享计算。所有层计算共享。