1、流式数据访问:一次写入,多次读取是最高效的访问模式。数据集通常由数据源生成或从数据源复制而来,每次分析都在该数据集上进行
2、数据块:文件的独立存储单元,默认64MB;目的是为了最小化寻址开销;块的元数据存在namenode的内存中;HDFS中一个小于块大小的文件不会占据整个块的空间
3、namenode的容错为什么重要,容错的方法有哪些?
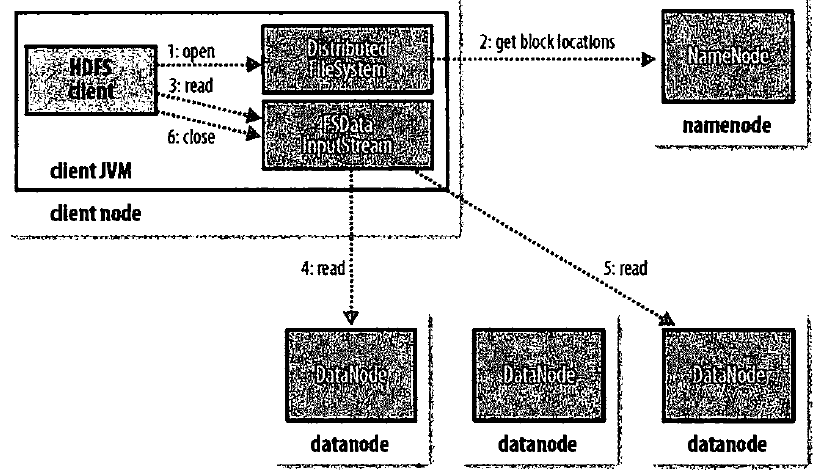
4、读文件的流程:
5、写文件的流程:
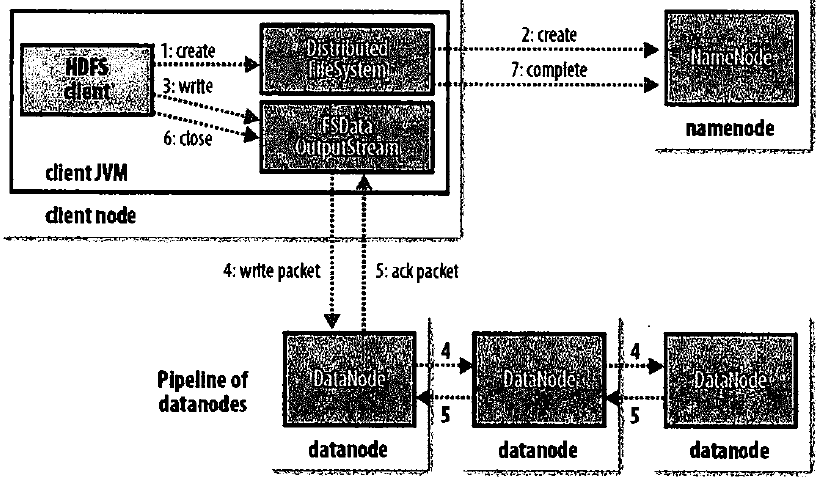
6、写文件中数据队列、管线、副本布局的问题
7、distcp并行复制
8、带宽:数据中心中最稀缺的资源!
1、流式数据访问:一次写入,多次读取是最高效的访问模式。数据集通常由数据源生成或从数据源复制而来,每次分析都在该数据集上进行
2、数据块:文件的独立存储单元,默认64MB;目的是为了最小化寻址开销;块的元数据存在namenode的内存中;HDFS中一个小于块大小的文件不会占据整个块的空间
3、namenode的容错为什么重要,容错的方法有哪些?
4、读文件的流程:
5、写文件的流程:
6、写文件中数据队列、管线、副本布局的问题
7、distcp并行复制
8、带宽:数据中心中最稀缺的资源!