Apache solr 6.6.0安装
最近使用了Apache solr搜索引擎框架,solr是基于lucene的一个搜索服务器,lucene也是Apache的一个开源项目;对于学习搜索引擎来说,这个入门也是不错的
http://www.apache.org/dyn/closer.lua/lucene/solr/6.6.0,首先先把Apache solr 6.6.0的包下载.

我下载来的目录结构是这样的,bin里可以进行solr的启动,几条基本的命令,在bin里:一般使用端口为8983
solr start -p 8983,开启solr
solr stop -p 8983,关闭solr
solr start -p 8983 -f 前台开启,默认是后台开启
也可以不加-p 端口,会开启默认端口,
浏览器里打开solr管理界面 http://localhost:8983/solr/
solr create -c <name> 创建一个核心 solr delete -c <name> 删除一个核心
创建好的核心是放在solr-6.6.0serversolr下的,进入创建好的核心里,
核心/data/index/里的文件和lucene的索引文件差不多,核心/conf/的里文件
data-config.xml文件是自己创的,而最常修改的文件就是solrconfig.xml和managed-schema,注意版本不同,配置文件的名称也不同
一般如果要让搜索引擎支持中文的话,是需要加入中文词法分析,而如果要和数据库连接,是需要数据库的架包,首先考虑你的搜索引擎是否需要中文词法分析器.
对几种中文分析器: StandardAnalyzer、ChineseAnalyzer、CJKAnalyzer、IK_CAnalyzer、MIK_CAnalyzer、MMAnalyzer(JE分词)、PaodingAnalyzer等,我用的是IK_CAnalyzer
链接:http://pan.baidu.com/s/1o8HoQRg 密码:yavs,下载的地址,下好的文件夹为
当然,将ik-analyzer-solr5-5.x.jar 放入solr-6.6.0serversolr-webappwebappWEB-INFlib,一般对于架包都是放着的
将IKAnalyzer.cfg.xml,mydict.dic(搜狗的扩展词库),stopword.dic放入solr-6.6.0serversolr-webappwebappWEB-INFclasses里
然后有了这些架包,就需要在配置文件里导入,在自己的核心confmanaged-schema里
<fieldType name="text_id" class="solr.TextField" positionIncrementGap="100"> <analyzer> <tokenizer class="solr.StandardTokenizerFactory"/> <filter class="solr.LowerCaseFilterFactory"/> <filter class="solr.StopFilterFactory" words="lang/stopwords_id.txt" ignoreCase="true"/> <filter class="solr.IndonesianStemFilterFactory" stemDerivational="true"/> </analyzer> </fieldType> <!--它之后添加添加配置--> <fieldType name="text_ik" class="solr.TextField"> <analyzer type="index"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="false"/> </analyzer> <analyzer type="query"> <tokenizer class="org.apache.lucene.analysis.ik.IKTokenizerFactory" useSmart="true"/> </analyzer> </fieldType>
即添加一个类型为"text_ik",之后保存,接下来测试一下,先Reload一下,
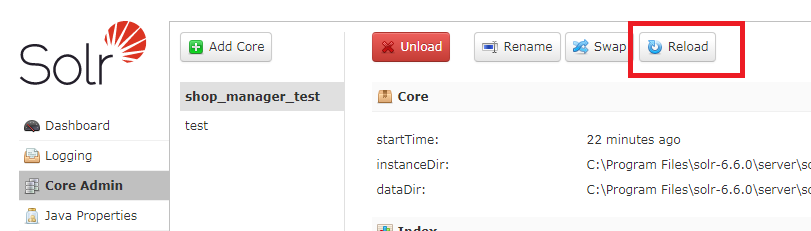
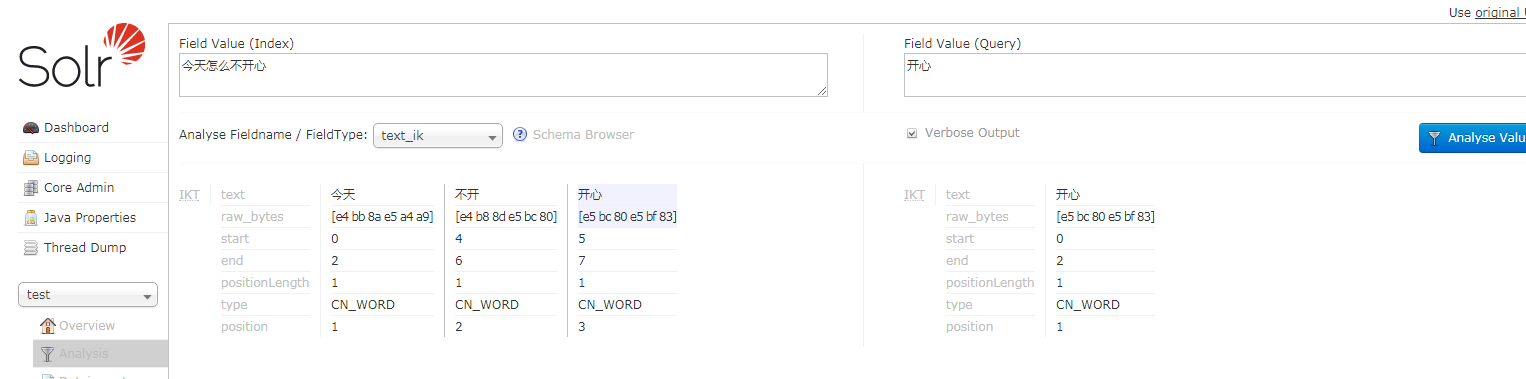
在自己的核心里的Analysis里测试,记得选择FieldType为text_ik,即中文词法分析,Verbose Output可选不可选都可以,
接下来就是配置数据库连接, 大多数的应用程序将数据存储在关系数据库、xml文件中。对这样的数据进行搜索是很常见的应用。所谓的DataImportHandler提供一种可配置的方式向solr导入数据,可以一次全部导入,也可以增量导入。
Handler首先要在自己的核心confsolrconfig.xml文件中配置下,如下所示:(强迫症,位置一定要规范,其实放哪都行)
<lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-velocity-d.*.jar" /> <!--之后引入DataImportHandler类的jar--> <lib dir="${solr.install.dir:../../../..}/dist/" regex="solr-dataimporthandler-.*.jar" />
在随便一个<requestHandler>...</requetHandler>之后添加:
<requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> </lst> </requestHandler>
我使用的是mysql,首先在核心里添加一个字段,这个字段可以通过
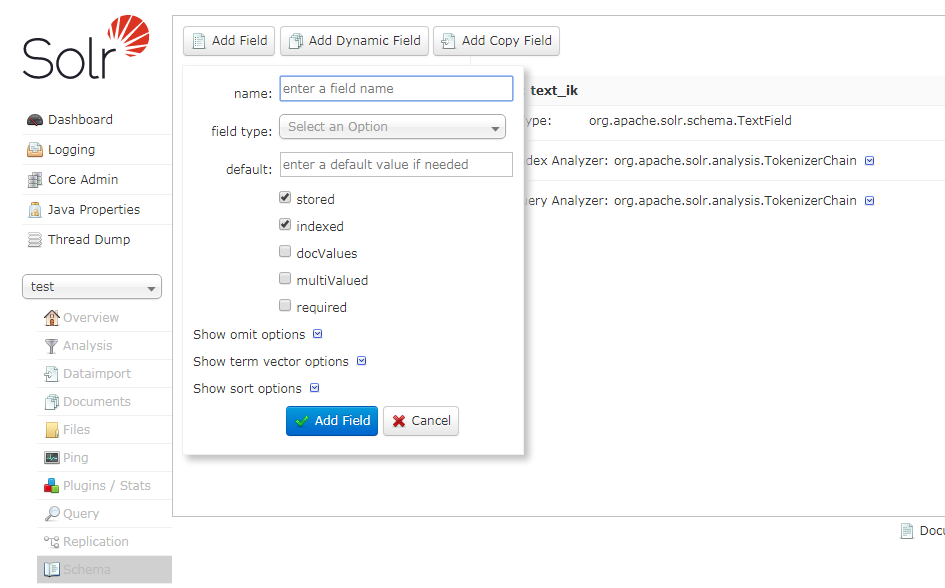
注意一下,field type看你的需要写,如果需要中文分析,就用text_ik,填好后,然后添加(Add Field)
或者在自己的核心confmanaged-schema里:
<field name="_version_" type="long" indexed="false" stored="false"/> <!--之后添加,字段类型注意--> <field name="content" type="text_ik" indexed="true" stored="true"/> <field name="id" type="string" multiValued="false" indexed="true" required="true" stored="true"/> <field name="title" type="text_ik" indexed="true" stored="true"/> <!--之前添加--> <dynamicField name="*_txt_en_split_tight" type="text_en_splitting_tight" indexed="true" stored="true"/>
其实放置的位置无所谓,只是最好还是规范一点好
接下来就是配置data-config.xml,在data-configxml中
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource name="production" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/solr_test" user="root" password="root" batchSize="-1" /> <document name="news"> <entity dataSource="production" name="test" pk="id" query="select * from test" deltaImportquery="select * from test where id=${dih.delta.id}" > <!--column的id是数据库的id,name的id是managed_schema里面的id,id是必须,并且唯一的--> <field column="id" name="id" /> <!--column的title是数据库的title字段,name的title是managed_schema里面的title,下面配置同理--> <field column="id" name="id" /> <field column="title" name="title" /> <field column="content" name="content" /> </entity> </document> </dataConfig>
先添加一个数据源,之后就是添加一个<document>,架包的位置和配置中文词法分析的架包放置位置一样,solr-6.6.0serversolr-webappwebappWEB-INFlib,接下来测试一下,先Reload一下,然后
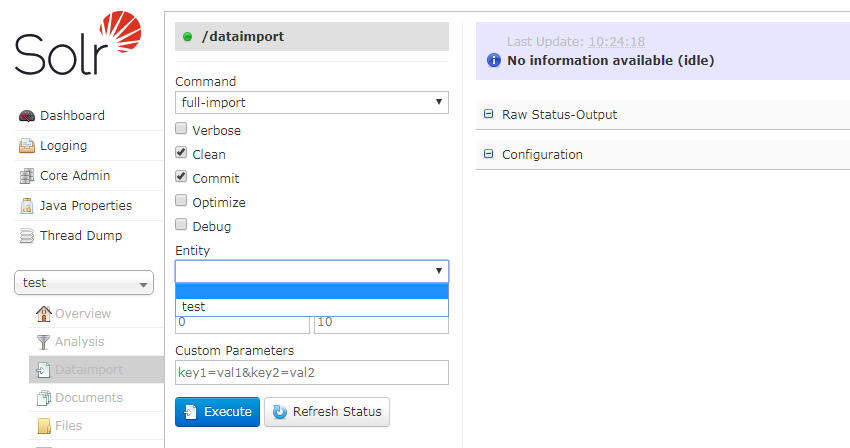
Command中选择full-import(全文导入),Entity即选择data-config.xml下自己写的,Execute后,多Refresh Status几次

就看到效果了
http://www.cnblogs.com/llz5023/archive/2012/11/15/2772154.html,推荐的一篇博客
最后的最后写下自己最近写的联合查询,有时候我想把多个表信息查出来,在data-config.xml中:
<?xml version="1.0" encoding="UTF-8"?> <dataConfig> <dataSource name="production" type="JdbcDataSource" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://127.0.0.1:3306/shop_manager" user="root" password="root" batchSize="-1" /> <document name="items"> <entity dataSource="production" name="all_resource" pk="id" query="select name,description,price from food_store union select name,description,price from cloths_store union select name,description,price from book_store;"> <!--column的id是数据库的id,name的id是managed_schema里面的id,id是必须,并且唯一的,不过我设置了uuid和更新策略--> <field column="name" name="name"/> <field column="description" name="description"/> <field column="price" name="price"/> </entity> </document> </dataConfig>
query中这么写,不过呢,有一个冲突就是id的重复,如果去掉id字段即,唯一键就没了,所以我就用了UUID,含义是通用唯一识别码 (Universally Unique Identifier)
修改自己的核心confsolrconfig.xml中的结果为:
<!--RequestHandler 手动添加--> <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler"> <lst name="defaults"> <str name="config">data-config.xml</str> <str name="update.chain">uuid</str> </lst> </requestHandler> <!--还需添加一个uuid的更新策略--> <requestHandler name="/update" class="solr.UpdateRequestHandler"> <lst name="defaults"> <str name="update.chain">uuid</str> </lst> </requestHandler>
搜索updateReqeustProcessorChain,在:
<updateRequestProcessorChain name="add-unknown-fields-to-the-schema">
前加入如下配置:
<updateRequestProcessorChain name="uuid"> <processor class="solr.UUIDUpdateProcessorFactory"> <str name="fieldName">id</str> </processor> <processor class="solr.LogUpdateProcessorFactory" /> <processor class="solr.DistributedUpdateProcessorFactory" /> <processor class="solr.RunUpdateProcessorFactory" /> </updateRequestProcessorChain>
修改自己的核心confsolrconfig.xml中的
<field name="id" type="uuid" multiValued="false" indexed="true" required="true" stored="true"/>
添加一个fieldType类型
<fieldType name="uuid" class="solr.UUIDField" indexed="true"/>
<!--确保uniqueKey的值是已经定义的,一般默认是id--> <uniqueKey>id</uniqueKey>
Reload搞定