1. 什么是hpsql
目前版本的hive中没有提供类似存储过程的功能,使用Hive做数据开发时候,一般是将一段一段的HQL语句封装在Shell或者其他脚本中,然后以命令行
的方式调用,完成一个业务或者一张报表的统计分析。好消息是,现在已经有了Hive存储过程的解决方案(HPL/SQL –Procedural SQL on hadoop),并
且在未来的Hive的版本(2.0)中,会将该模块集成进来。该解决方案不仅支持Hive,还支持在SparkSQL,其他NoSQL,甚至是RDBMS中使用类似于
Oracle PL/SQL的功能,这将极大的方便数据开发者的工作,Hive中很多之前比较难实现的功能,现在可以很方便的实现,比如自定义变量、基于一个结果集的游标、循环等等。
2. 安装配置hpsql
2.1 下载软件
可以从官网 http://www.hplsql.org/download下载最新版本安装包,并解压
也可以从我的云盘下载 <hplsql-0.3.17.tar.gz> 链接是:https://pan.baidu.com/s/1i5mTBEH 密码是:xbf
2.2 安装配置hpsql
mkdir /opt/hpsql
tar -zxf hplsql-0.3.17.tar.gz -C /opt/hpsql
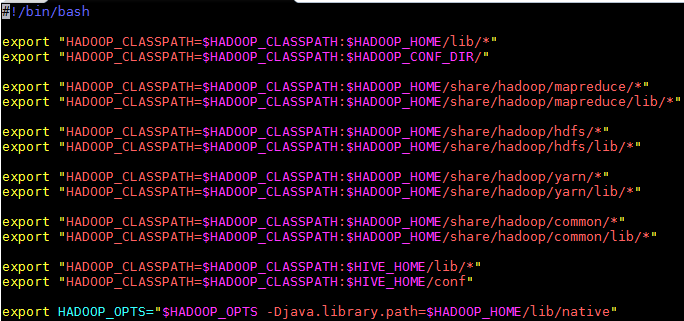
2.2.1 进入hplsql安装目录,配置 HADOOP_CLASSPATH
vi hplsql
2.2.2 进入hive安装目录,配置和启动Hive的thrift服务HiveServer2
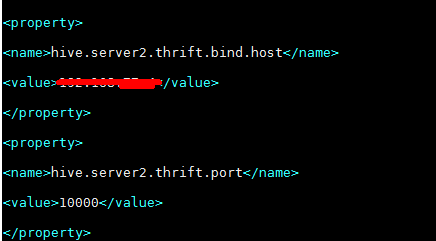
启动HiveServer2:
nohup hive --service hiveserver2 > hiveserver2.log 2>&1 &
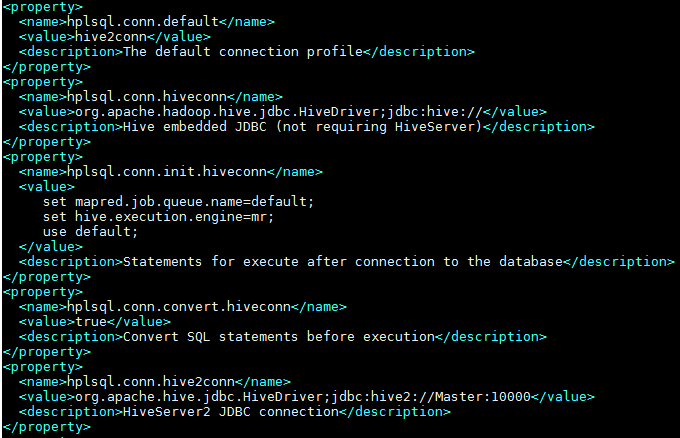
2.2.3 配置HPL/SQL与Hive的连接
vi hplsql-site.xml
2.3 使用hplsql执行HPL/SQL语句
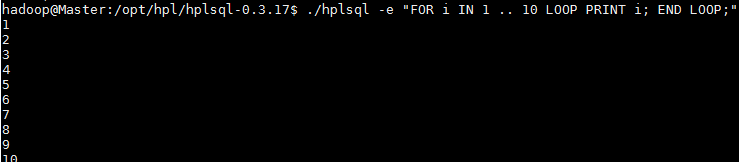
2.3.1 使用-e 命令在命令行窗口直接运行

2.3.2 使用-f 命令运行脚本
创建测试表people

创建测试脚本
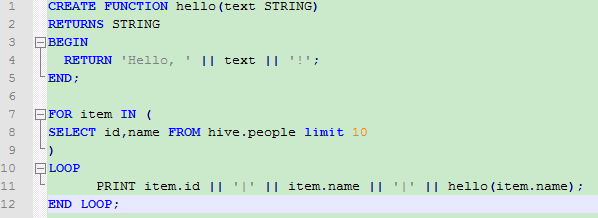
执行语句

2.3.3 存储过程调用
第一步,按如下格式创建存储过程
use database;
create procedure
begin
......
end;
第二步,按如下方式调用存储过程
include path/sp name
call sp name;
示例如下:
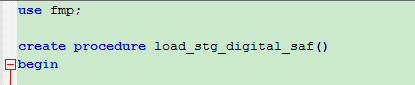
此处省略逻辑部分......

创建完成以后,调用运行,查看执行结果
