需求改进与系统设计
一、需求与原型改进
1.1改进的原型
1、改进说明



https://git.coding.net/ma744191948/team.work.git
1.2改进的原型需求规格说明书
1、改进说明
项目背景进行修改。
开发目标进行了修改补充。
用户角色分析表进行了补充。学生方面增加了安全性。
网站界面标准添加了四个新的标准,使网站界面更加标准美化。
网站设计验收标准添加了建设方面的标准,使网站设计更为规范。
2、需求规格说明书下载地址
https://git.coding.net/ma744191948/need.git
二、系统设计
2.1系统架构设计
开发级需求分析
在开发过程中,团队本身在开发的起始阶段确定了基本的开发级需求分析:
经过上一次的结对作业,我们对于合作开发这件事已经加深了一层理解,也更加清楚合作开发和个人开发的不同。因此我们会在开始开发前就制定好代码规范,在实行过程中,按照构建之法书中的要求来进行代码的实现,修改,测试,维护等等。
经过讨论我们决定使用已经学习过的代码语言来实现页面(例如:java,js,servlet,jsp等等),对于这几种语言我们团队都有一些开发经验,再次开发时会提高一些开发效率,而且这几种语言已经可以解决我们项目开发中的大部分问题。对于解决不了的问题,我们会进行学习,好在团队学习积极性较高,学习能力较强,由于网页功能较为复杂,我们团队将尽可能的使用成熟的框架技术,实现对开发效率和开发质量的需求。
需求回顾:
我们想要做一个关于失物招领的平台,现在每天东师有大量的学生丢失物品,而我们开发这样一个网站,是方便捡到的人可以将物品信息发布在网上,然后丢失东西的人可以在我们的网站上进行搜索查询,方便东师学生生活,这样一个专门的网站,可以减少用户丢失重要物品而找不到的情况,极大的帮助了这些遗失物品的人。
架构设计
1.设计摘要说明
首先从架构的层次上,对本身的设计进行最简短的概述:
|
前端页面 |
直接与用户打交道,发出提供用户增加,减少,修改,查询遗失物品功能的请求 |
后端系统 |
负责处理用户的请求,并衔接搜索系统,使用户对数据进行操作 |
搜索系统 |
负责搜集、整合数据,并响应网站后端的搜索请求,提供搜索结果 |
因此不妨设计东师拾遗的概念架构图如下图所示:
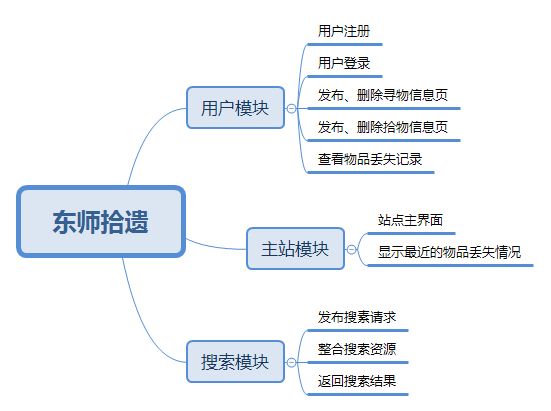
2.前端页面设计
前端开发将依据UI设计的交互进行开发,主要用到的语言有:html、css、jquery、js。开发过程会用到Bootstrap框架,以完成响应式布局。开发工具将用到sublime tex,后期与后端调试时将用到IDE。前端开发会积极做好与UI设计人员和后台开发人员的沟通,力求界面美观大方,交互符合用户需求。
3.后端系统设计
为了达到我们的开发级需求,我们选择使用java语言进行后端开发,并使用SpringMVC框架。
比较同意一种说法,Java最大的优势不是它的跨平台性而是它庞大而完善的生态系统。它的流行最主要原因还是由其生态系统决定的。
Java语言各方面比较均衡,拥有最值得信赖的GC,避免很多码农的低级错误。并且天生的面向对象设计,更容易模块化开发。再加上Java强类型静态语言,只要框架已搭好,即便开发人员能力不足,也基本能保证代码质量,这在大项目的协作开发、维护方面很有优势。开源,拥有大量的第三方库,并且大部分质量有保证,可以拿来就用,对软件生产效率的提升所带来的巨大价值。正如一句话所说:“我们不生产代码,我们只是Github的搬运工。”并且Java拥有很多杀手级应用,如Spring,Apache、Android,Hadoop,Spark等。
为了提高我们的开发效率,我们决定使用SpringMVC框架如果没有MVC设计模式。程序间的各层之间依赖非常强,耦合度高。严重违背了高内聚低耦合的设计原则。而WebMVC将控制逻辑和功能处理,模型和视图进行了分离。降低耦合。
后端系统主要有两部分功能,一部分是与用户系统相关的功能,如用户的登陆、管理、发布还有完成等等,另一部分则是与搜索引擎的衔接。同时还有一个模块负责整个站点的衔接、整合等。
ps:数据库架构
信息架构的方面,我们认为数据库的设计也至关重要。
建立用户实体类,物品实体类,用户实体类中声明所有需要用到的属性。用户和物品在关系上呈现一对多的关系。两者之间通过用户的id实现关联。
由于拾遗物品是经过分类的,对于这些物品不同分类设置不同键值,类似于Map存储方式。
对于开发过程:首先实现用户模块,再增加主站模块实现与数据库信息之间各种不同的操作。最后通过数据库查询实现搜索模块,搜索过程中支持关键字模糊查询。
平台架构设计
1.tomcat服务器
Tomcat是Apache 软件基金会(Apache Software Foundation)的Jakarta 项目中的一个核心项目,由Apache、Sun 和其他一些公司及个人共同开发而成。由于有了Sun 的参与和支持,最新的Servlet 和JSP 规范总是能在Tomcat 中得到体现,Tomcat 5支持最新的Servlet 2.4 和JSP 2.0 规范。因为Tomcat 技术先进、性能稳定,而且免费,因而深受Java 爱好者的喜爱并得到了部分软件开发商的认可,成为目前比较流行的Web 应用服务器。
2.搜索系统
数据库查询是数据库的最主要功能之一。为了增加数据库的查询效率,我们准备使用索引数据结构。
使用索引结构的原因如下:
我们都希望查询数据的速度能尽可能的快,因此数据库系统的设计者会从查询算法的角度进行优化。最基本的查询算法当然是顺序查找(linear search),这种复杂度为O(n)的算法在数据量很大时显然是糟糕的,好在计算机科学的发展提供了很多更优秀的查找算法,例如二分查找(binary search)、二叉树查找(binary tree search)等。如果稍微分析一下会发现,每种查找算法都只能应用于特定的数据结构之上,例如二分查找要求被检索数据有序,而二叉树查找只能应用于二叉查找树上,但是数据本身的组织结构不可能完全满足各种数据结构(例如,理论上不可能同时将两列都按顺序进行组织),所以,在数据之外,数据库系统还维护着满足特定查找算法的数据结构,这些数据结构以某种方式引用(指向)数据,这样就可以在这些数据结构上实现高级查找算法。这种数据结构,就是索引。
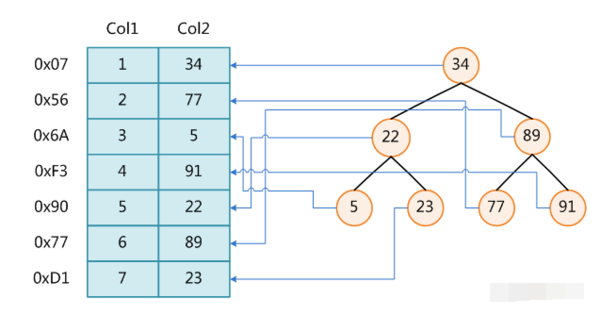
我们准备使用上图的索引方式:
左边是数据表,一共有两列七条记录,最左边的是数据记录的物理地址(注意逻辑上相邻的记录在磁盘上也并不是一定物理相邻的)。为了加快Col2的查找,可以维护一个右边所示的二叉查找树,每个节点分别包含索引键值和一个指向对应数据记录物理地址的指针,这样就可以运用二叉查找在O(log2n)O(log2n)的复杂度内获取到相应数据。
需求分析的过程
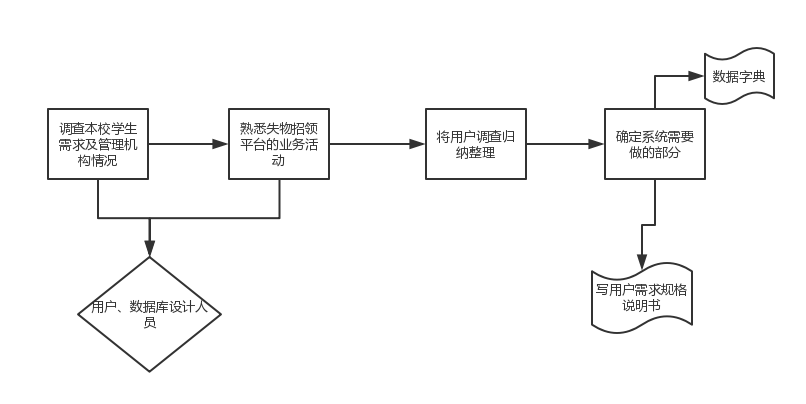
概念结构设计
1、说明
实体集:拾到物品的人、失主、被拾到的物品、丢失的物品
属性集:
l 拾到物品的人(姓名,校区,邮箱,电话)
l 拾到(拾主联系方式,拾到的物品编号,拾到时间,拾到地点)
l 拾到的物品(编号,类别,具体描述)
l 失主(姓名,校区,邮箱,电话)
l 丢失(失主联系方式,丢失的物品编号,丢失时间,丢失地点)
l 丢失的物品(编号,类别,具体描述)
l 归还(物品编号,失主联系方式,拾主联系方式)
联系集:
l 拾到东西的人和拾到的物品:每个人可以拾到多个物品,存在“拾到”的关系:1:N
l 失主和丢失的物品:一个人可以丢失多个物品,存在“丢失”的关系:1:N
l 拾到东西的人和失主:失主通过平台查询自己所丢之物,在系统中找到所丢之物对应的拾到东西的人的联系方式,寻回物品。
2、E-R图
失主与丢失的物品

拾到物品的人与拾到的物品
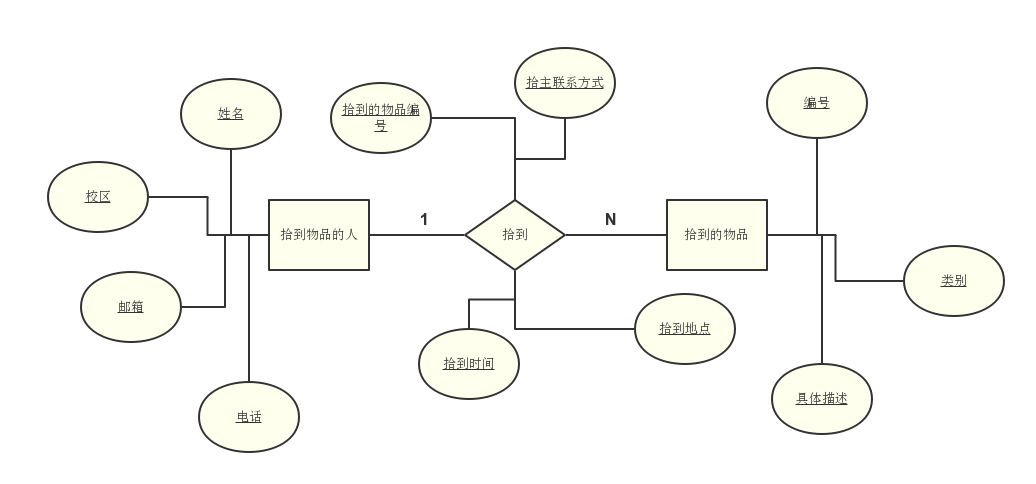
拾到物品的人与失主

逻辑结构设计
1、数据模型的规范化(根据函数依赖,使所有关系模式达到3NF)
(1)拾到东西的人模式(假设无同姓名的人):
姓名(主键) 校区、邮箱、电话
(2)失主模式:
姓名(主键) 校区、邮箱、电话
(3)拾到模式
物品编号(主键) 拾到地点、拾到时间、拾主联系方式
(4)丢失模式
物品编号(主键) 丢失地点、丢失时间、失主联系方式
(5)物品模式
物品编号(主键) 类别、描述
2、 在数据库中的具体实现
Finder(拾到物品的人的表):
|
字段名 |
数据类型(精度范围) |
空/非空 |
约束条件 |
说明 |
|
Fname |
Varchar(10) |
Not null |
Primary key |
姓名 |
|
Fzone |
Char(10) |
Not null |
|
校区 |
|
Femail |
Char(10) |
Not null |
|
邮箱 |
|
Fphone |
Varchar(10) |
Not null |
|
电话 |
Loser(失主的表):
|
字段名 |
数据类型(精度范围) |
空/非空 |
约束条件 |
说明 |
|
Lname |
Varchar(10) |
Not null |
Primary key |
姓名 |
|
Lzone |
Char(10) |
Not null |
|
校区 |
|
Lemail |
Char(10) |
Not null |
|
邮箱 |
|
Lphone |
Varchar(10) |
Not null |
|
电话 |
Find(拾到模式)
|
字段名 |
数据类型(精度范围) |
空/非空 |
约束条件 |
说明 |
|
Fdid |
Varchar(10) |
Not null |
Primary key |
物品编号 |
|
Fdplace |
Char(20) |
Not null |
|
拾到地点 |
|
Fdtime |
Char(10) |
Not null |
|
拾到时间 |
|
Fdphone |
Varchar(10) |
Not null |
|
拾主联系方式 |
Lose(丢失模式)
|
字段名 |
数据类型(精度范围) |
空/非空 |
约束条件 |
说明 |
|
Lsid |
Varchar(10) |
Not null |
Primary key |
物品编号 |
|
Lsplace |
Char(20) |
Not null |
|
丢失地点 |
|
Lstime |
Char(10) |
Not null |
|
丢失时间 |
|
Lsphone |
Varchar(10) |
Not null |
|
失主联系方式 |
Thing(物品模式)
|
字段名 |
数据类型(精度范围) |
空/非空 |
约束条件 |
说明 |
|
Tgid |
Varchar(10) |
Not null |
Primary key |
物品编号 |
|
Tgname |
Char(10) |
Not null |
|
类别 |
|
Tgdiscrib |
Varchar(30) |
Not null |
|
具体描述 |
物理结构设计
1、数据库系统选择
操作系统选择Windows10,数据库管理系统选择SQL Server 2008,前台开发工具选择sublime text3,后台开发工具选择myeclipse与IDE。
2、设置索引
(1)对于Finder表,将姓名作为唯一索引。
(2)对于Loser表,将姓名作为唯一索引。
(3)对于Find表,将Fdid(物品编号)作为唯一索引,将类别作为聚簇索引。
(4)对于Lose表,将Lsid(物品编号)作为唯一索引,将类别作为聚簇索引。
(5)对于Thing表,将Tgid(物品编号)作为唯一索引,将类别作为聚簇索引。
3、用户权限设计
|
用户权限 |
查询物品信息 |
发布物品信息 |
修改物品信息 |
删除物品信息 |
|
管理员 |
可以 |
可以 |
可以 |
可以 |
|
已注册用户 |
可以 |
可以 |
可以(仅自己) |
可以(仅自己) |
|
未注册用户 |
可以 |
不可以 |
不可以 |
不可以 |
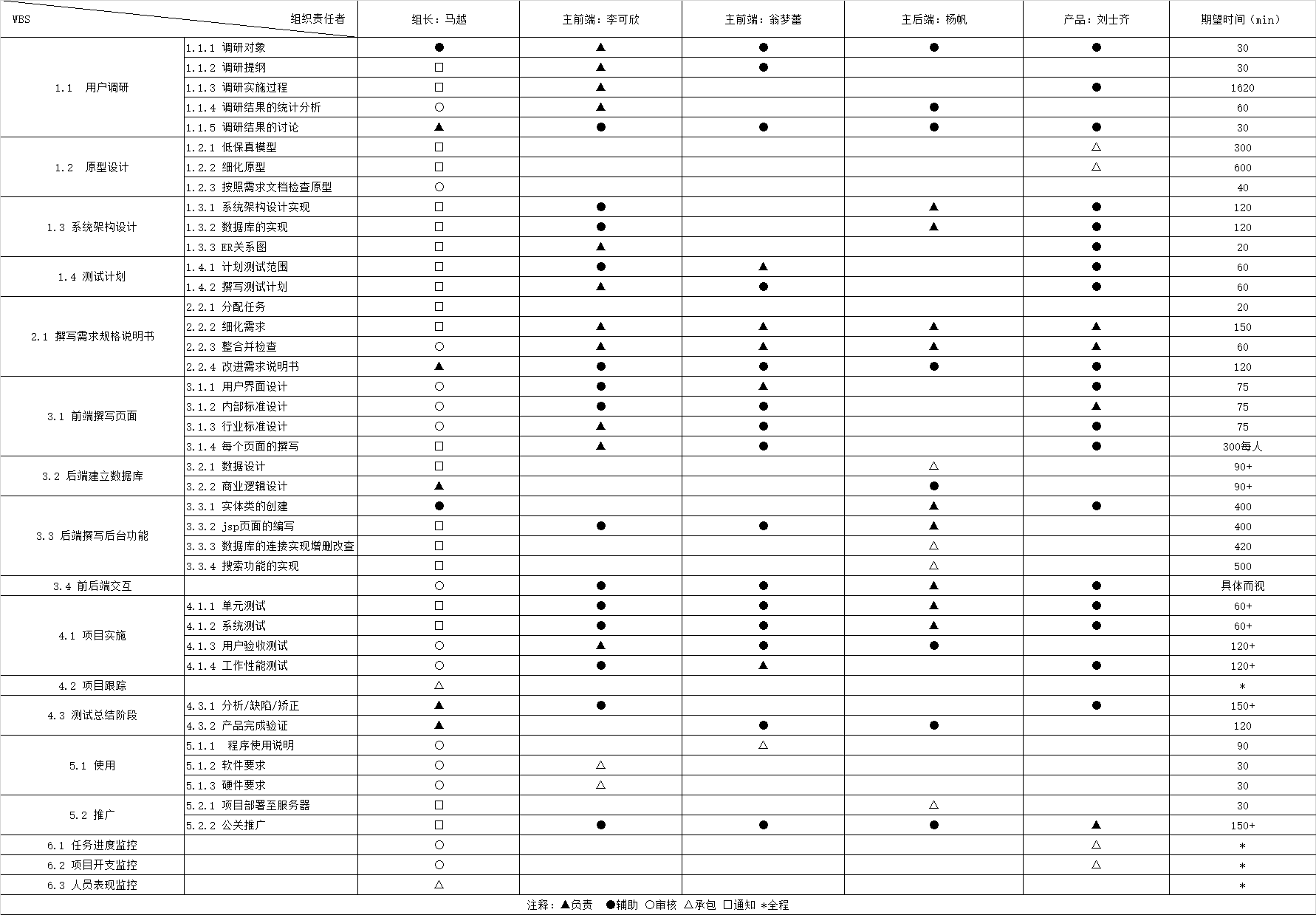
2.2任务分解WBS

三、测试计划
3.1测试计划
目录
1、引言
项目背景
参考资料
测试术语(新增)
2、任务概述
测试范围
测试目标
3、测试策略
测试人员需求、分工(新增)
测试方法
测试工具
测试阶段预估及日程计划
测试变量矩阵量
4、测试资源
5、风险评估
6、其他内容
引言
项目背景
目前市场上有许多类似的失物招领网站,但是大多数都没有针对性。大多数高校失物招领还是依靠校内实体站点或者公众号的方式进行失物招领,具有即时性,但是并不方便,范围不够广。基于在校大学生的特性,我们希望基于网站,建立一款针对在校大学生的半实名制可搜索的失物招领网站。
参考资料
测试需求分析总结
https://www.cnblogs.com/hanxiaomin/p/6132828.html
网站测试流程、要求及测试报告
http://lib.csdn.net/article/softwaretest/24298?knId=1307
测试需求分析
https://wenku.baidu.com/view/63d77034336c1eb91b375d1f.html
《东师拾遗》需求规格说明书
https://git.coding.net/ma744191948/need.git
测试术语
|
测试术语 |
名词解释 |
|
轮播 |
轮播为网站首页中的流动播放的图片,主要为较为紧急的老师或学生丢失的最新的物品信息 |
|
权限管理 |
对于管理员的权限及学生老师用户权限的管理区域 |
|
种类 |
用于用户搜索物品关键词时网页提供的一些热搜词及分类 |
|
用户管理 |
对于用户的增删改查管理 |
任务概述
测试范围
针对于网页进行的各项实用性能测试(包括用户界面及管理员界面)
制作者测试:美工页面测试、程序员页面测试
全面测试:页面框架结构问题、错别字、常识问题
发布测试:环境不同导致的问题
测试目标
链接测试能通过
表单测试能通过
Cookies测试能通过
数据库测试能通过
性能测试能基本通过,尽量提高性能
可用性测试能通过
兼容性测试能通过firefox,chrome,360
测试策略
测试人员需求、分工
分析、缺陷、矫正测试:马越、李可欣、刘士齐
产品完成验证:马越、翁梦蕾、杨帆
测试方法
手动测试:每个链接、文字都由人工编辑测试
测试为交互验证方式,互相督促,互相验证
压力测试:使用http_upload压力测试
测试工具
Junit单元测试工具
http_upload压力测试工具
WebPagetest 前端性能测试工具
测试阶段预估及日程计划
|
测试阶段
|
测试任务
|
工作量估计 |
人员分配 |
时间安排 |
|
第一阶段 功能测试 |
|
复杂 |
全体人员 |
开发阶段 |
|
第二阶段 系统测试 |
1.完成所有模块的组合测试 2.确定所有业务流向和数据都是正确的。 |
中等 |
前端开发人员、后端开发人员 |
Alpha阶段结束后2天 |
|
第三阶段 性能测试 |
在多用户访问,交替进行负荷压迫测试 |
复杂 |
全体人员、邀请部分用户参与 |
Beta阶段结束后2天 |
|
第四阶段 兼容测试 |
软件在各个软件平台上的运行情况 |
中等 |
全体人员 |
Beta阶段结束后4天 |
测试变量矩阵量
|
|
用户类型 |
屏幕分辨率 |
操作系统 |
默认语言 |
浏览器 |
网络速度 |
组合总数 |
|
变量数目 |
3 |
2 |
3 |
2 |
3 |
3 |
324 |
|
|
管理员 |
800*600(像素) |
Windows10 |
简体中文 |
360 |
拨号 |
|
|
|
已注册用户 |
1024*768(像素) |
Windows7 |
英文 |
Firefox |
ADSL |
|
|
|
未注册用户 |
|
mac |
|
|
局域网 |
|
|
|
|
|
|
|
|
|
|
测试资源
人力资源:全部开发人员及邀请用户测试人员
物力资源:
Windows10操作系统
Windows7 操作系统
Mac操作系统
google浏览器、firefox浏览器
风险评估
网站进度风险:时间较短,开发人员较少,人员配比不平均,可能导致网站按时交付时出现部分问题
网站需求风险:需求分析文档可能会有不足,造成后期的问题
技术开发风险:技术不成熟,可能导致网站性能较差
网站设计风险:并不是由专业人员设计,交互性可能略微落后
人员流失风险:人员流失导致网站进度拖慢
竞争风险:同期可能有较多网站与之进行竞争
其他内容
测试计划制定者:翁梦蕾、李可欣
日期:2018年5月30日
修改记录:暂无
评审人员:马越
开发负责人:李可欣、翁梦蕾、杨帆、刘士齐
测试负责人:马越