1.关于年龄Age
除了利用平均数来填充,还可以利用正态分布得到一些随机数来填充,首先得到已知年龄的平均数mean和方差std,然后生成[ mean-std, mean+std ]之间的随机数,然后利用这些随机值填充缺失的年龄。
2.关于票价Fare
预处理:训练集不缺,测试集缺失1个,用最高频率值填充
Fare_freq = test.Fare.dropna().mode()[0] # 找出非缺失值中的所有最高频值,取第一个
for dataset in train_test_data:
dataset['Fare'] = dataset['Fare'].fillna(Fare_freq)
特征工程:由于Fare分布非常不均,所以这里不用cut函数,而是qcut,因为它可以根据样本分位数对数据进行面元划分,可以使得到的类别中数目基本一样。
train['FareBins'] = pd.qcut(train['Fare'], 5) # 按照分位数切成5份
train[['FareBins', 'Survived']].groupby(['FareBins'], as_index = False).mean().sort_values(by = 'Survived', ascending = True)
fare = data_train.groupby(['FareBins'])
fare_l = (fare.sum()/fare.count())['Survived']
fare_l.plot(kind='bar')

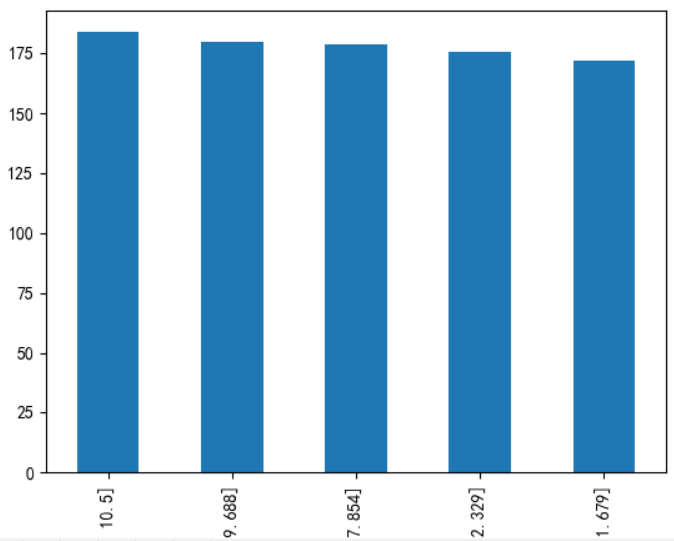

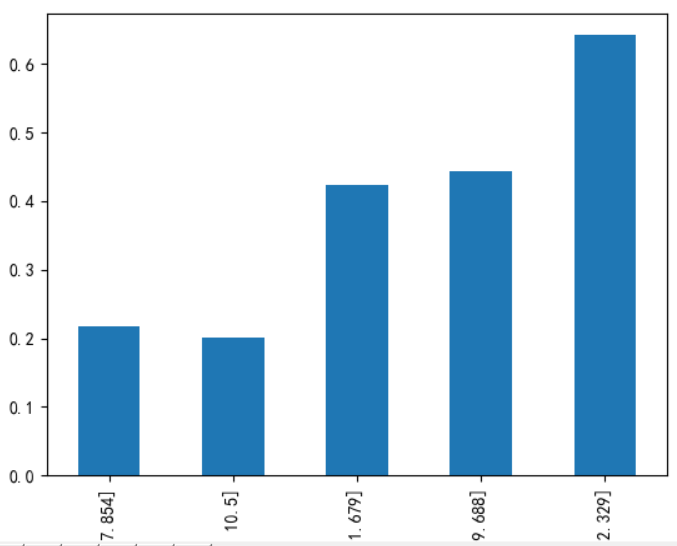
上图左为cut函数结果,中为qcut函数结果,右图为各年龄段的生存率,升序排列,可以看到生存率基本上按照票价增加而增加。然后在数据集中新增FareBins取值0~4,然后删除Fare项。
3.关于亲人SibSp和Parch
新增Family特征为SibSp和Parch的和,删掉SibSp和Parch
dataset["FamilySize"] = dataset['SibSp'] + dataset['Parch']
train[['FamilySize', 'Survived']].groupby(['FamilySize'], as_index = False).mean().sort_values(by = 'Survived', ascending = False)
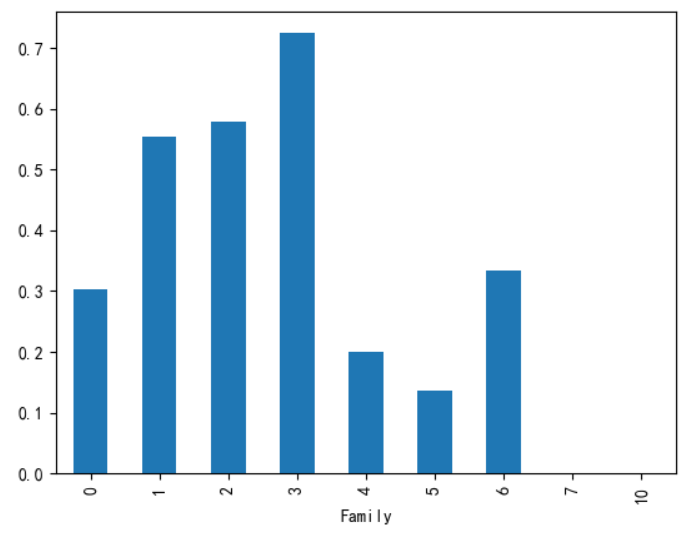
此图是亲人数目与生存率关系,表明有1~3个亲属生存率更高些。所以我考虑将1~3单独作为一类。
4.关于姓名
取出姓名中的’属性‘,例如有:Mr、Miss、Dr、Major等
df =data_train.Name.apply(lambda x: x.split(',')[1].split('.')[0].strip())
df.value_counts().plot(kind='bar')
train_test_data = [train, test] # 将训练集和测试集合并处理
for dset in train_test_data: # 对于人数较少的属性将其统一命名为‘Lamped’
dset["Title"] = dset["Title"].replace(["Melkebeke", "Countess", "Capt", "the Countess", "Col", "Don",
"Dr", "Major", "Rev", "Sir", "Jonkheer", "Dona"] , "Lamped")
dset["Title"] = dset["Title"].replace(["Lady", "Mlle", "Ms", "Mme"] , "Miss") # 将女性称号合并
train[['Title', 'Survived']].groupby(['Title'], as_index = False).mean().sort_values(by = 'Survived', ascending = False)

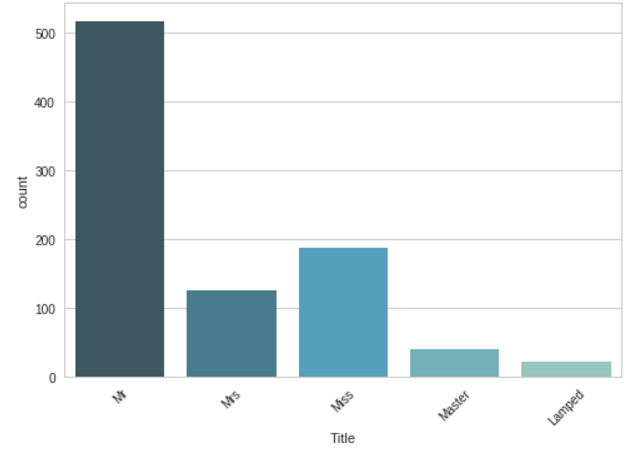
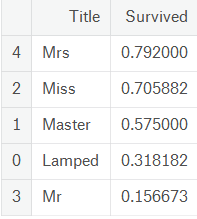
然后将这类特征作为新特征取值0~4加入,删掉原有特征Name。
按照以上思路跑了另一个例子,结果并没有提高多少


import pandas as pd import numpy as np import matplotlib.pyplot as plt from pandas import Series, DataFrame from sklearn.model_selection import train_test_split from sklearn.preprocessing import StandardScaler from sklearn.metrics import classification_report from learning_curve import * from pylab import mpl from sklearn.model_selection import cross_val_score mpl.rcParams['font.sans-serif'] = ['SimHei'] #使得plt操作可以显示中文 from sklearn.feature_extraction import DictVectorizer data_train = pd.read_csv('train.csv') data_test = pd.read_csv('test.csv') feature = ['Pclass','Age','Sex','Fare','Embarked','SibSp','Parch','Cabin','Name'] X_train = data_train[feature] y_train = data_train['Survived'] X_test = data_test[feature] X_train_test = [X_train, X_test] """ 填充操作 """ # 填充Age, Cabin:训练集合测试集都缺,且填补方式一样 def age_fill(X): for df in X: age_mean = df['Age'].dropna().mean() age_std = df['Age'].dropna().std() age = np.random.randint(age_mean-age_std, age_mean+age_std, size=df['Age'].isnull().sum()) df['Age'][np.isnan(df['Age'])] = age df['Cabin'][df['Cabin'].isnull()] = 0 df['Cabin'][df['Cabin']!=0] = 1 return X age_fill(X_train_test) # 填充Embarked:只有训练集缺一个 X_train['Embarked'][X_train['Embarked'].isnull()] = X_train.Embarked.dropna().mode()[0] # 填充Fare:只有测试集缺一个 X_test['Fare'][X_test['Fare'].isnull()] = X_test.Fare.dropna().mode()[0] """ 特征工程 """ # Pclass def Pclass_f(df): dummies_Pclass = pd.get_dummies(df['Pclass'], prefix='Pclass') df = pd.concat([df, dummies_Pclass], axis=1) df.drop(['Pclass'], axis=1, inplace=True) return df X_train = Pclass_f(X_train) X_test = Pclass_f(X_test) # Sex def Sex_f(df): dummies_Sex = pd.get_dummies(df['Sex'], prefix='Sex') df = pd.concat([df, dummies_Sex], axis=1) df.drop(['Sex'], axis=1, inplace=True) return df X_train = Sex_f(X_train) X_test = Sex_f(X_test) # Embarked def Embarked_f(df): dummies_Embarked = pd.get_dummies(df['Embarked'], prefix='Embarked') df = pd.concat([df, dummies_Embarked], axis=1) df.drop(['Embarked'], axis=1, inplace=True) return df X_train = Embarked_f(X_train) X_test = Embarked_f(X_test) X_train_test = [X_train, X_test] # SibSp+Parch for df in X_train_test: df['Family'] = df['SibSp'] + df['Parch'] df.drop(['SibSp', 'Parch'], axis=1, inplace=True) # Age for df in X_train_test: df['Age_new'] = (df['Age'] / 8).astype(int) df.drop(['Age'], axis=1, inplace=True) # Fare for df in X_train_test: df['Fare_new'] = pd.qcut(df['Fare'], 5) df.loc[df['Fare'] <= 7.854, 'Fare'] = 0 df.loc[(df['Fare'] > 7.84) & (df['Fare'] <= 10.5), 'Fare'] = 1 df.loc[(df['Fare'] > 10.5) & (df['Fare'] <= 21.679), 'Fare'] = 2 df.loc[(df['Fare'] > 21.679) & (df['Fare'] <= 39.688), 'Fare'] = 3 df.loc[(df['Fare'] > 39.688) & (df['Fare'] <= 5512.329), 'Fare'] = 4 df.drop(['Fare_new'], axis=1, inplace=True) # Name for df in X_train_test: df['Name_new'] = df['Name'].apply(lambda x: x.split(',')[1].split('.')[0].strip()) df["Name_new"] = df["Name_new"].replace(["Melkebeke", "Countess", "Capt", "the Countess", "Col", "Don", "Dr", "Major", "Rev", "Sir", "Jonkheer", "Dona"], "Lamped") df["Name_new"] = df["Name_new"].replace(["Lady", "Mlle", "Ms", "Mme"], "Miss") df['Name_new'] = df['Name_new'].map({'Mr': 1, 'Miss': 2, 'Mrs': 3, 'Master': 4, 'Lamped': 5}).astype(int) df.drop(['Name'], axis=1, inplace=True) """ MACHINE LEARNING """ from sklearn.model_selection import train_test_split from sklearn.metrics import accuracy_score from sklearn.linear_model import LogisticRegression, Perceptron, SGDClassifier from sklearn.svm import SVC, LinearSVC from sklearn.ensemble import RandomForestClassifier, AdaBoostClassifier, BaggingClassifier from sklearn.tree import DecisionTreeClassifier from sklearn.neighbors import KNeighborsClassifier from sklearn.naive_bayes import GaussianNB dec = LogisticRegression(C=1.2, penalty='l2', tol=1e-6, max_iter=150) # dec = GaussianNB() # dec = DecisionTreeClassifier() # dec = RandomForestRegressor(n_estimators = 100) # dec =DecisionTreeClassifier() # dec = RandomForestClassifier(n_estimators=100) # dec = SVC(C=1.3,kernel='poly') # dec = LinearSVC() # dec= SGDClassifier(max_iter=8, tol=None) dec.fit(X_train, y_train) y_pre = dec.predict(X_test) # 交叉验证 X_cro = X_train.as_matrix() y_cro = y_train.as_matrix() # est = LogisticRegression(C=1.0, penalty='l1', tol=1e-6) scores = cross_val_score(dec, X_cro, y_cro, cv=5) print(scores) print(scores.mean()) """ KNN """ # k_range = list(range(1, 30)) # scores_knn = [] # for k in k_range: # knn = KNeighborsClassifier(n_neighbors=k) # knn.fit(X_train, y_train) # scores_knn.append(cross_val_score(knn, X_cro, y_cro, cv=5).mean()) # print(k, scores_knn[k-1]) # # plt.plot(k_range, scores_knn) # plt.xlabel('K Values') # plt.ylabel('Accuracy') """ Perceptron """ # scores_P = [] # for i in range(1,30): # clf = Perceptron(max_iter=i, tol=None) # clf.fit(X_train, y_train) # scores_P.append(cross_val_score(clf, X_cro, y_cro, cv=5).mean()) # print(i, scores_P[i-1]) # # # Plot # plt.plot(range(1,30), scores_P) # plt.xlabel('max_iter') # plt.ylabel('Accuracy') """ AdaBoost """ # e_range = list(range(1, 25)) # scores_A = [] # for est in e_range: # ada = AdaBoostClassifier(n_estimators=est) # ada.fit(X_train, y_train) # scores_A.append(cross_val_score(ada, X_cro, y_cro, cv=5).mean()) # print(i, scores_A[est-1]) # # plt.plot(e_range, scores_A) # plt.xlabel('estimator values') # plt.ylabel('Accuracy') """ Bagging """ # e_range = list(range(1, 30)) # scores_B = [] # for est in e_range: # ada = BaggingClassifier(n_estimators=est) # ada.fit(X_train, y_train) # scores_B.append(cross_val_score(ada, X_cro, y_cro, cv=5).mean()) # print(i, scores_B[est-1]) # # plt.plot(e_range, scores_B) # plt.xlabel('estimator values') # plt.ylabel('Accuracy') # 学习曲线 plot_learning_curve(dec, u"学习曲线", X_train, y_train) # 查看各个特征的相关性 columns = list(X_train.columns) plt.figure(figsize=(8,8)) plot_df = pd.DataFrame(dec.coef_.ravel(), index=columns) plot_df.plot(kind='bar') plt.show() # 保存结果 # result = pd.DataFrame({'PassengerId':data_test['PassengerId'].as_matrix(), 'Survived':y_pre.astype(np.int32)}) # result.to_csv("my_logisticregression_1.csv", index=False) # Logistic Regression [ 0.82681564 0.82122905 0.78089888 0.82022472 0.83050847] 0.815935352 # Guassian Naive Bayes [ 0.73184358 0.73184358 0.75842697 0.79775281 0.80225989] 0.764425362625 # Decision Trees [ 0.77094972 0.74860335 0.80898876 0.7752809 0.84180791] 0.78912612903 # Random Forest [ 0.81564246 0.77653631 0.83146067 0.80898876 0.84745763] 0.816017167254 # SVM [ 0.84916201 0.81564246 0.81460674 0.80337079 0.85875706] 0.828307811902 # Linear SVC [ 0.81564246 0.82681564 0.79213483 0.81460674 0.84180791] 0.81820151663933 # Stochastic Gradient Decent (SGD) [ 0.7877095 0.79329609 0.7247191 0.79213483 0.7740113 ] 0.774374163722 # KNN MAX: 0.82722180788832633 # Perceptron MAX: 0.79691590180393057 # AdaBoost MAX: 0.8260603371814963 # Bagging MAX: 0.81936277456417805 # dec = SVC(C=1.2,kernel='poly') [ 0.84916201 0.82681564 0.82022472 0.79775281 0.8700565 ] 0.832802335779