1. join()方法不止是拼接
我先把那个问题化简一下吧:
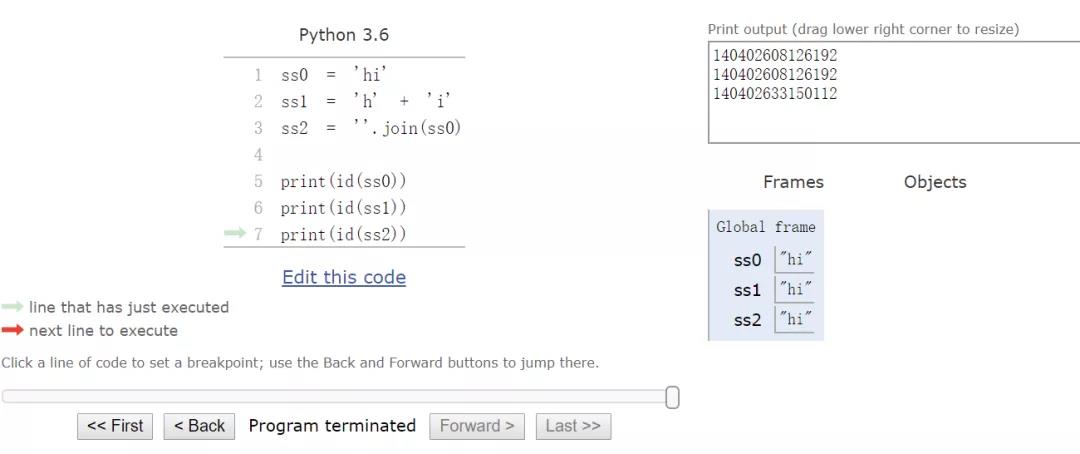
ss0 = 'hi' ss1 = 'h' + 'i' ss2 = ''.join(ss0) print(ss0 == ss1 == ss2) >>> True print(id(ss0) == id(ss1)) >>> True print(id(ss0) == id(ss2)) >>> False
上面代码中,奇怪的地方就在于 ss2 竟然是一个独立的对象!按照最初想当然的认知,我认定它会被 Intern 机制处理掉,所以是不会占用独立内存的。上篇文章快写完的时候,我突然想到 join 方法,所以没做验证就临时加进去,导致了意外的发生。
按照之前在“特权种族”那篇文章的总结,我对字符串 Intern 机制有这样的认识:
Python中,字符串使用Intern机制实现内存地址共用,长度不超过20,且仅包括下划线、数字、字母的字符串才会被intern;涉及字符串拼接时,编译期优化结果会与运行期计算结果不同
为什么 join 方法拼接字符串时,可以不受 Intern 机制作用呢?
回看那篇文章,发现可能存在编译期与运行期的差别!
# 编译对字符串拼接的影响 s1 = "hell" s2 = "hello" "hell" + "o" is s2 >>>True s1 + "o" is s2 >>>False # "hell" + "o"在编译时变成了"hello", # 而s1+"o"因为s1是一个变量,在运行时才拼接,所以没有被intern
实验一下,看看:
ss3 = ''.join('hi') print(id(ss0) == id(ss3)) >>> False
ss3 仍然是独立对象,难道这种写法还是在运行期时拼接?那怎么判断某种写法在编译期还是在运行期起作用呢?继续实验:
s0 = "Python猫" import copy s1 = copy.copy(s0) s2 = copy.copy("Python猫") print(id(s0) == id(s1)) >>> True print(id(s0) == id(s2)) >>> False
看来,不能通过是否显性传值来判断。
那就只能从 join 方法的实现原理入手查看了。经某交流群的小伙伴提醒,可以去 Python Tutor 网站,看看可视化执行过程。但是,很遗憾,也没看出什么底层机制。
我找了分析 CPython 源码的资料(含上期荐书栏目的《Python源码剖析》)来学习,但是,这些资料只比较 join() 方法与 + 号拼接法在原理与使用内存上的差异,并没提及为何 Intern 机制对前者会失效,而对后者却是生效的。
现象已经产生,我只能暂时解释说,join 方法可能会不受 Intern 机制控制,它有独享内存的“特权”。
那就是说,其实有复制字符串的方法!上篇《Python是否支持复制字符串呢?》由于没有发现这点,最后得出了错误的结论!
由于这个特例,我要修改上篇文章的结论了:Python 本身并不限制字符串的复制操作,CPython 解释器出于优化性能的考虑,加入了一些小把戏,试图使字符串对象在内存中只有一份,尽管如此,仍存在有效复制字符串的方法,那就是 join() 方法。
2. Intern 机制失效的情况
join() 方法的神奇用处使我不得不改变对 Intern 机制的认识,本小节就带大家重新学习一下 Intern 机制吧。
所谓 Intern 机制,即字符串滞留(string interning),它通过维护一个字符串常量池(string intern pool),从而试图只保存唯一的字符串对象,达到既高效又节省内存地处理字符串的目的。在创建一个新的字符串对象后,Python 先比较常量池中是否有相同的对象(interned),有的话则将指针指向已有对象,并减少新对象的指针,新对象由于没有引用计数,就会被垃圾回收机制回收掉,释放出内存。
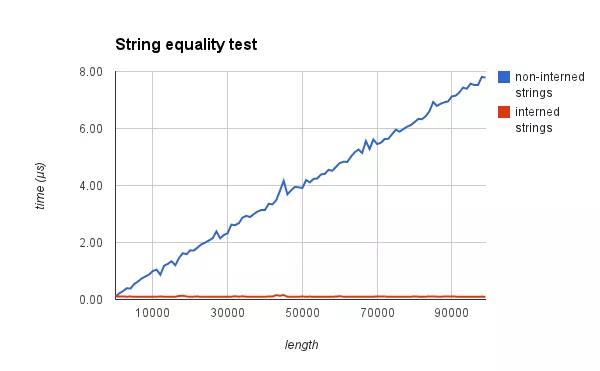
Intern 机制不会减少新对象的创建与销毁,但最终会节省出内存。这种机制还有另一个好处,即被 Interned 的相同字符串作比较时,几乎不花时间。实验数据如下(资料来源:http://t.cn/ELu9n7R):
Intern 机制的大致原理很好理解,然而影响结果的还有 CPython 解释器的其它编译及运行机制,字符串对象受到这些机制的共同影响。实际上,只有那些“看起来像” Python 标识符的字符串才会被处理。源代码StringObject.h的注释中写道:
/* … … This is generally restricted to strings that “looklike” Python identifiers, although the intern() builtin can be used to force interning of any string … … */
这些机制的相互作用,不经意间带来了不少混乱的现象:
# 长度超过20,不被intern VS 被intern 'a' * 21 is 'aaaaaaaaaaaaaaaaaaaaa' >>> False 'aaaaaaaaaaaaaaaaaaaaa' is 'aaaaaaaaaaaaaaaaaaaaa' >>> True # 长度不超过20,不被intern VS 被intern s = 'a' s * 5 is 'aaaaa' >>> False 'a' * 5 is 'aaaaa' >>> True # join方法,不被intern VS 被intern ''.join('hi') is 'hi' >>> False ''.join('h') is 'h' >>> True # 特殊符号,不被intern VS 被"intern" 'python!' is 'python!' >>> False a, b = 'python!', 'python!' a is b >>> True
这些现象当然都能被合理解释,然而由于不同机制的混合作用,就很容易造成误会。比如第一个例子,很多介绍 Intern 机制的文章在比较出 'a' * 21 的id有变化后,就认为 Intern 机制只对长度不超过20的字符串生效,可是,当看到长度超过20的字符串的id还相等时,这个结论就变错误了。当加入常量合并(Constant folding) 的机制后,长度不超过20的字符串会被合并的现象才得到解释。可是,在 CPython 的源码中,只有长度不超过1字节的字符串才会被 intern ,为何长度超标的情况也出现了呢? 再加入 CPython 的编译优化机制,才能解释。
所以,看似被 intern 的两个字符串,实际可能不是 Intern 机制的结果,而是其它机制的结果。同样地,看似不能被 intern 的两个字符串,实际可能被其它机制以类似方式处理了。
如此种种,便提高了理解 Intern 机制的难度。
就我在上篇文章中所关心的“复制字符串”话题而言,只有当 Intern 机制与其它这些机制统统失效时,才能做到复制字符串。目前看来,join 方法最具通用性。
3. 学习的方法论
总而言之,因为重新学习 join 方法的神奇用处与 Intern 机制的例外情况,我得以修正上篇文章的错误。在此过程中,我得到了新的知识,以及思考学习的乐趣。
《超人》电影中有一句著名的台词,在今年上映的《头号玩家》中也出现了:
有的人从《战争与和平》里看到的只是一个普通的冒险故事,
有的人则能通过阅读口香糖包装纸上的成分表来解开宇宙的奥秘。
我读到的是一种敏锐思辨的思想、孜孜求索的态度和以小窥大的方法。作为一个低天赋的人,受此鼓舞,我会继续追问那些看似没意义的问题(“如何删除字符串”、“如何复制字符串”…),一点一点地学习 Python ,以我的方式理解它。同时,希望能给我的读者们带来一些收获。