线性二次型调节控制
现在我们讨论一个用于连续状态MDP的一个寻找最优策略的一个方法。该方法中我们直接近似V∗,而不采用离散化。该方法称之为值函数近似,在很多实际RL问题都有很好的应用。
- 使用一个模型或
为了发展一个值函数近似算法,我们假设对于MDP,我们有一个模型(model)或仿真器(simulator)。通俗的说,一个仿真器是一个黑盒子,输入是任何一个连续值的状态st,动作at,根据状态转移概率矩阵Pstat输出到下一个状态st+1,如下图:
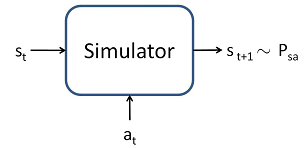
有很多方法来得到该模型。其一是,使用物理仿真。举个例子来说,对于之前提到的倒摆的一个仿真器,该倒摆是通过一些列物理定律来精确计算小车和木杆的位置和方向,即在时间t时,给定一个动作a,如果我们知道了各个参数(比如木板的长度、质量等等),我们就能精确的计算到时间t+1时候的小车和木杆的位置和方向。或者我们可以使用已有的一些物理仿真包来求解,即输入完整的物理参数,以及当前的状态st和要采取的动作at,就可以计算系统在下一秒的状态st+1。
一个获得该模型的方法是从MDP收集的数据中得到。比如说,我们重复试验MDP后,得到了m条链,每条链有T个时间步。这个过程中,我们可以随机的选择动作,或者执行特定的策略或者根据某一方法选择动作。我们得到了m个状态序列,如下:
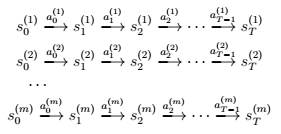
之后,我们可以应用一些算法来预测状态st+1,其参数为st和at。比如,我们可以选择一个线性模型:st+1 = Ast + Bat,使用的该仿真算法类似于线性回归。这里的参数是矩阵A和矩阵B,我们可以使用观测到的m条马尔可夫链进行估计:
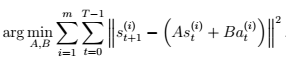
这与最大似然估计参数是一致的。在学得AB之后,一个方法是构建一个确定性(deterministic)的模型,即在给定输入st和at时,输出的st+1是确定的。即我们总是根据得到的方程来计算下一个状态st+1;或者我们可以建立一个随机(deterministic)模型,即st+1是不确定的,根据st+1 = Ast + Bat + εt得到,这里的是εt噪音项,服从N(0,Σ)分布(这里的矩阵Σ也可以通过观测到的数据估计得到)。
因此,我们得到了在当前状态和动作下的下一个状态的线性模型,但是非线性模型该怎么办呢?一个方法是通过变换,即我们可以学习一个模型st+1 = Aφs(st ) + Bφa(at),这里的φs和φa都是状态和动作的一些非线性特征映射函数。另一个方法是使用非线性学习算法,比如局部加权线性回归来学习估计状态st+1。这些模型都可以用来构建确定性的或不确定性的MDP仿真器。
- 拟合值迭代
我们现在描述一个拟合值迭代(fitted value iteration)算法,用于估计连续状态MDP的值函数。这里我们将假设一个问题,含有连续状态空间S=Rn,但是动作空间A是很小的而且是离散的。回想一下值迭代,我们希望的更新如下:
V (s) := R(s) + γ maxa
= R(s) + γ maxa Es′∼Psa[V (s′)]
在之前的部分,对于离散状态的MDP是求和,而这里是连续状态因此是积分。
拟合值迭代的主要是想是:我们将使用有限样本的状态空间s(1), . . . , s(m),特别的,我们将使用监督式学习算法——如下描述的线性回归,用一个线性或非线性的状态函数来近似值函数。V (s) = θTφ(s),这里的φ是状态空间的一些适当的特征映射。
对于我们有限样本的m个状态,拟合值迭代将会首先计算一个量y(i),可以用R(s) + γ maxa Es′∼Psa[V (s′)]来近似,之后采用监督式学习,努力使得V(s)尽可能的接近R(s) + γ maxa Es′∼Psa[V (s′)],即接近y(i)。
具体算法如下:
- 随机样本的m个状态s(1), . . . , s(m)∈ S
- 初始化θ := 0
-
循环 {
对于 i = 1, … , m{
对于每个动作a ∈ A {
样本s′1, . . . , s′k∼ Ps(i)a(使用一个MDP模型)
让 q(a) =
//这里q(a)就是 R(s) + γ maxa Es′∼Psa[V (s′)]的估计
}
令y(i) = maxaq(a) // y(i)是R(s)+γmaxa Es′∼Psa[V (s′)]的估计
}
// 在最开始的值迭代算法中,我们根据V (s(i)) := y(i)更新值函数
// 在该算法中,我们希望采用监督式学习,使得V (s(i)) ≈ y(i)
令θ := arg minθ
}
在上面,我们使用了线性回归算法的拟合值迭代,来努力使得V (s(i)) 接近y(i),算法的步骤和标准的监督式学习都是类似的。尽管算法描述使用了线性模型,但是其他的回归算法(如局部加权线性回归)也是可以使用的。
与离散状态空间的值迭代不同,拟合值迭代不能被证明是一定收敛的。然而在实际应用中,他通常都是收敛的或近似收敛,在许多问题中都能有很好的结果。需要注意,如果我们使用MDP的确定性的仿真器或模型,那么拟合值迭代算法中可以通过在最开始设置k=1来简化算法。因为Es′∼Psa[V (s′)]变成了对确定性分布的期望了,所以一个样本就能够求得期望。此外,上述算法,我们不得不抽取k个样本,然后用均值来近似期望值。
最后,拟合值迭代输出V,是近似于V*,这就含蓄的定义了我们的策略。特别的,当我们的系统在状态s时,我们需要选择一个动作,我们希望选择一个动作满足:
arg maxaEs′∼Psa[V (s′)]
计算该式子的方法类似于拟合值迭代的内循环,即对于每一个动作,用样本s′1, . . . , s′k∼ Ps(i)a来近似期望。同样,对于确定性的仿真器,我们可以设置k=1。
在实际应用中,也会有一些其他的方法来近似这个步骤。比如,常用的一个方法是如果仿真器是st+1 =f (st, at ) + εt的形式,这里的f是一些确定性的状态函数,比如f (st, at ) = Ast + Bat,而ε均值为0的高斯噪声。在这个例子中,我们可以通过arg maxaV (f (s, a))来选择动作。换句话说,这里默认了εt=0(即在仿真器中忽略了噪声),设定k=1。等同于:
Es′[V (s′)] ≈ V (Es′ [s′]) = V (f (s, a))
这里的期望是基于随机变量s′∼ Psa。只要噪声项εt是很小的,这通常都是很合理的近似。然而,对于不适用于该近似方法的,即样本空间为K|A|,如果采用上式进行期望的近似,那么计算量是很大的。