为什么交叉熵可以用于计算代价函数
通用的说,熵(Entropy)被用于描述一个系统中的不确定性(the uncertainty of a system)。在不同领域熵有不同的解释,比如热力学的定义和信息论也不大相同。
要想明白交叉熵(Cross Entropy)的意义,可以从熵(Entropy) -> KL散度(Kullback-Leibler Divergence) -> 交叉熵这个顺序入手。当然,也有多种解释方法[1]。
先给出一个"接地气但不严谨"的概念表述:
- 熵:可以表示一个事件A的自信息量,也就是A包含多少信息。
- KL散度:可以用来表示从事件A的角度来看,事件B有多大不同。
- 交叉熵:可以用来表示从事件A的角度来看,如何描述事件B。
一句话总结的话:KL散度可以被用于计算代价,而在特定情况下最小化KL散度等价于最小化交叉熵。而交叉熵的运算更简单,所以用交叉熵来当做代价。
我知道你现在看着有点晕,但请保持耐心继续往下看。*为了通俗易懂,我没有严格按照数学规范来命名概念,比如文中的"事件"指的是"消息",望各位严谨的读者理解。
1. 什么是熵(Entropy)?
放在信息论的语境里面来说,就是一个事件所包含的信息量。我们常常听到"这句话信息量好大",比如"昨天花了10万,终于在西二环买了套四合院"。
这句话为什么信息量大?因为它的内容出乎意料,违反常理。由此引出:
- 越不可能发生的事件信息量越大,比如"我不会死"这句话信息量就很大。而确定事件的信息量就很低,比如"我是我妈生的",信息量就很低甚至为0。
- 独立事件的信息量可叠加。比如"a. 张三今天喝了阿萨姆红茶,b. 李四前天喝了英式早茶"的信息量就应该恰好等于a+b的信息量,如果张三李四喝什么茶是两个独立事件。
因此熵被定义为  , x指的不同的事件比如喝茶,
, x指的不同的事件比如喝茶, 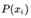 指的是某个事件发生的概率比如和红茶的概率。对于一个一定会发生的事件,其发生概率为1,
指的是某个事件发生的概率比如和红茶的概率。对于一个一定会发生的事件,其发生概率为1, ,信息量为0。
,信息量为0。
2. 如何衡量两个事件/分布之间的不同(一):KL散度
我们上面说的是对于一个随机变量x的事件A的自信息量,如果我们有另一个独立的随机变量x相关的事件B,该怎么计算它们之间的区别?
此处我们介绍默认的计算方法:KL散度,有时候也叫KL距离,一般被用于计算两个分布之间的不同。看名字似乎跟计算两个点之间的距离也很像,但实则不然,因为KL散度不具备有对称性。在距离上的对称性指的是A到B的距离等于B到A的距离。
举个不恰当的例子,事件A:张三今天买了2个土鸡蛋,事件B:李四今天买了6个土鸡蛋。我们定义随机变量x:买土鸡蛋,那么事件A和B的区别是什么?有人可能说,那就是李四多买了4个土鸡蛋?这个答案只能得50分,因为忘记了"坐标系"的问题。换句话说,对于张三来说,李四多买了4个土鸡蛋。对于李四来说,张三少买了4个土鸡蛋。选取的参照物不同,那么得到的结果也不同。更严谨的说,应该是说我们对于张三和李四买土鸡蛋的期望不同,可能张三天天买2个土鸡蛋,而李四可能因为孩子满月昨天才买了6个土鸡蛋,而平时从来不买。
KL散度的数学定义:
-
对于离散事件我们可以定义事件A和B的差别为(2.1):
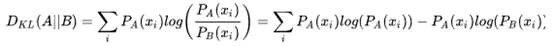
-
对于连续事件,那么我们只是把求和改为求积分而已(2.2)。
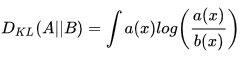
从公式中可以看出:
- 如果
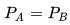 ,即两个事件分布完全相同,那么KL散度等于0。
,即两个事件分布完全相同,那么KL散度等于0。 - 观察公式2.1,可以发现减号左边的就是事件A的熵,请记住这个发现。
-
如果颠倒一下顺序求
 ,那么就需要使用B的熵,答案就不一样了。所以KL散度来计算两个分布A与B的时候是不是对称的,有"坐标系"的问题,
,那么就需要使用B的熵,答案就不一样了。所以KL散度来计算两个分布A与B的时候是不是对称的,有"坐标系"的问题, 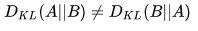
换句话说,KL散度由A自己的熵与B在A上的期望共同决定。当使用KL散度来衡量两个事件(连续或离散),上面的公式意义就是求 A与B之间的对数差 在 A上的期望值。
3. KL散度 = 交叉熵 - 熵?
如果我们默认了用KL散度来计算两个分布间的不同,那还要交叉熵做什么?
事实上交叉熵和KL散度的公式非常相近,其实就是KL散度的后半部分(公式2.1):A和B的交叉熵 = A与B的KL散度 - A的熵。 
对比一下这是KL散度的公式:
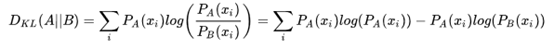
这是熵的公式:
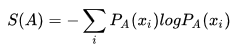
这是交叉熵公式:
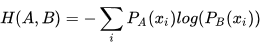
此处最重要的观察是,如果S(A) 是一个常量,那么 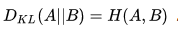 ,也就是说KL散度和交叉熵在特定条件下等价。这个发现是这篇回答的重点。
,也就是说KL散度和交叉熵在特定条件下等价。这个发现是这篇回答的重点。
同时补充交叉熵的一些性质:
- 和KL散度相同,交叉熵也不具备对称性:
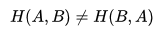 ,此处不再赘述。
,此处不再赘述。 - 从名字上来看,Cross(交叉)主要是用于描述这是两个事件之间的相互关系,对自己求交叉熵等于熵。即
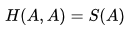 ,注意只是非负而不一定等于0。
,注意只是非负而不一定等于0。
*4. 另一种理解KL散度、交叉熵、熵的角度(选读)- 可跳过
那么问题来了,为什么有KL散度和交叉熵两种算法?为什么他们可以用来求分布的不同?什么时候可以等价使用?
一种信息论的解释是:
- 熵的意义是对A事件中的随机变量进行编码所需的最小字节数。
- KL散度的意义是"额外所需的编码长度"如果我们用B的编码来表示A。
- 交叉熵指的是当你用B作为密码本来表示A时所需要的"平均的编码长度"。
对于大部分读者,我觉得可以不用深入理解。感谢评论区@王瑞欣的指正,不知道为什么@不到他。
一些对比与观察:
- KL散度和交叉熵的不同处:交叉熵中不包括"熵"的部分
- KL散度和交叉熵的相同处:a. 都不具备对称性 b. 都是非负的
- 等价条件(章节3):当 固定不变时,那么最小化KL散度
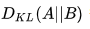 等价于最小化交叉熵
等价于最小化交叉熵 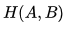 。
。 
既然等价,那么我们优先选择更简单的公式,因此选择交叉熵。
5. 机器如何"学习"?
机器学习的过程就是希望在训练数据上模型学到的分布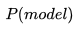 和真实数据的分布
和真实数据的分布 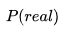 越接近越好,那么我们已经介绍过了....怎么最小化两个分布之间的不同呢?用默认的方法,使其KL散度最小!
越接近越好,那么我们已经介绍过了....怎么最小化两个分布之间的不同呢?用默认的方法,使其KL散度最小!
但我们没有真实数据的分布,那么只能退而求其次,希望模型学到的分布和训练数据的分布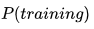 尽量相同,也就是把训练数据当做模型和真实数据之间的代理人。假设训练数据是从总体中独立同步分布采样(Independent and identically distributed sampled)而来,那么我们可以利用最小化训练数据的经验误差来降低模型的泛化误差。简单说:
尽量相同,也就是把训练数据当做模型和真实数据之间的代理人。假设训练数据是从总体中独立同步分布采样(Independent and identically distributed sampled)而来,那么我们可以利用最小化训练数据的经验误差来降低模型的泛化误差。简单说:
- 最终目的是希望学到的模型的分布和真实分布一致:
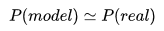
- 但真实分布是不可知的,我们只好假设 训练数据 是从真实数据中独立同分布采样而来:

-
退而求其次,我们希望学到的模型分布至少和训练数据的分布一致
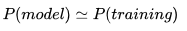
由此非常理想化的看法是如果模型(左)能够学到训练数据(中)的分布,那么应该近似的学到了真实数据(右)的分布:
6. 为什么交叉熵可以用作代价?
接着上一点说,最小化模型分布 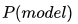 与
与 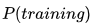 训练数据上的分布 的差异 等价于 最小化这两个分布间的KL散度,也就是最小化 。
训练数据上的分布 的差异 等价于 最小化这两个分布间的KL散度,也就是最小化 。
比照第四部分的公式:
- 此处的A就是数据的真实分布:
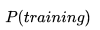
- 此处的B就是模型从训练数据上学到的分布:

巧的是,训练数据的分布A是给定的。那么根据我们在第四部分说的,因为A固定不变,那么求 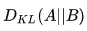 等价于求
等价于求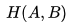 ,也就是A与B的交叉熵。得证,交叉熵可以用于计算"学习模型的分布"与"训练数据分布"之间的不同。当交叉熵最低时(等于训练数据分布的熵),我们学到了"最好的模型"。
,也就是A与B的交叉熵。得证,交叉熵可以用于计算"学习模型的分布"与"训练数据分布"之间的不同。当交叉熵最低时(等于训练数据分布的熵),我们学到了"最好的模型"。
但是,完美的学到了训练数据分布往往意味着过拟合,因为训练数据不等于真实数据,我们只是假设它们是相似的,而一般还要假设存在一个高斯分布的误差,是模型的泛化误差下线。
7. 总结
因此在评价机器学习模型时,我们往往不能只看训练数据上的误分率和交叉熵,还是要关注测试数据上的表现。如果在测试集上的表现也不错,才能保证这不是一个过拟合或者欠拟合的模型。交叉熵比照误分率还有更多的优势,因为它可以和很多概率模型完美的结合。
所以逻辑思路是,为了让学到的模型分布更贴近真实数据分布,我们最小化 模型数据分布 与 训练数据之间的KL散度,而因为训练数据的分布是固定的,因此最小化KL散度等价于最小化交叉熵。
因为等价,而且交叉熵更简单更好计算,当然用它咯 ʕ•ᴥ•ʔ
Tensorflow交叉熵函数:cross_entropy
注意:tensorflow交叉熵计算函数输入中的logits都不是softmax或sigmoid的输出,而是softmax或sigmoid函数的输入,因为它在函数内部进行sigmoid或softmax操作
tf.nn.sigmoid_cross_entropy_with_logits(_sentinel=None,labels=None, logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
Note:
它对于输入的logits先通过sigmoid函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立但互不排斥的情况:例如一幅图可以同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mea(loss)使用
计算公式:

Python 程序:
importtensorflowas tf
import numpy asnp
def sigmoid(x):
return 1.0/(1+np.exp(-x))
# 5个样本三分类问题,且一个样本可以同时拥有多类
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,1,0],[0,1,0]]
logits = np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pred = sigmoid(logits)
E1 = -y*np.log(y_pred)-(1-y)*np.log(1-y_pred)
print(E1) # 按计算公式计算的结果
sess =tf.Session()
y = np.array(y).astype(np.float64) # labels是float64的数据类型
E2 = sess.run(tf.nn.sigmoid_cross_entropy_with_logits(labels=y,logits=logits))
print(E2)
输出的E1,E2结果相同
tf.nn.softmax_cross_entropy_with_logits(_sentinel=None, labels=None, logits=None, dim=-1, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes]
labels:和logits具有相同type和shape的张量(tensor),,是一个有效的概率,sum(labels)=1, one_hot=True(向量中只有一个值为1.0,其他值为0.0)
name:操作的名字,可填可不填
output:
loss,shape:[batch_size]
Note:
它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
计算公式:

Python程序:
importtensorflowas tf
import numpy asnp
def softmax(x):
sum_raw = np.sum(np.exp(x),axis=-1)
x1 = np.ones(np.shape(x))
for i inrange(np.shape(x)[0]):
x1[i] = np.exp(x[i])/sum_raw[i]
return x1
y = np.array([[1,0,0],[0,1,0],[0,0,1],[1,0,0],[0,1,0]])# 每一行只有一个1
logits =np.array([[12,3,2],[3,10,1],[1,2,5],[4,6.5,1.2],[3,6,1]])
y_pred =softmax(logits)
E1 = -np.sum(y*np.log(y_pred),-1)
print(E1)
sess = tf.Session()
y = np.array(y).astype(np.float64)
E2 = sess.run(tf.nn.softmax_cross_entropy_with_logits(labels=y,logits=logits))
print(E2)
输出的E1,E2结果相同
tf.nn.sparse_softmax_cross_entropy_with_logits(_sentinel=None,labels=None,logits=None, name=None)
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes]
labels: shape为[batch_size],labels[i]是{0,1,2,……,num_classes-1}的一个索引, type为int32或int64
name:操作的名字,可填可不填
output:
loss,shape:[batch_size]
Note:
它对于输入的logits先通过softmax函数计算,再计算它们的交叉熵,但是它对交叉熵的计算方式进行了优化,使得结果不至于溢出
它适用于每个类别相互独立且排斥的情况,一幅图只能属于一类,而不能同时包含一条狗和一只大象
output不是一个数,而是一个batch中每个样本的loss,所以一般配合tf.reduce_mean(loss)使用
计算公式:
和tf.nn.softmax_cross_entropy_with_logits()一样,只是要将labels转换成tf.nn.softmax_cross_entropy_with_logits()中labels的形式
tf.nn.weighted_cross_entropy_with_logits(labels,logits, pos_weight, name=None)
计算具有权重的sigmoid交叉熵sigmoid_cross_entropy_with_logits()
argument:
_sentinel:本质上是不用的参数,不用填
logits:一个数据类型(type)是float32或float64;
shape:[batch_size,num_classes],单样本是[num_classes]
labels:和logits具有相同的type(float)和shape的张量(tensor),
pos_weight:正样本的一个系数
name:操作的名字,可填可不填
output:
loss,shape:[batch_size,num_classes]
计算公式:
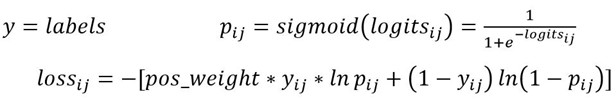
GAN对抗生成网络
上述这种博弈式的训练过程,如果采用神经网络作为模型类型,则被称为生成式对抗网络(GAN)。用数学语言描述整个博弈过程的话,就是:假设我们的生成模型是g(z),其中z是一个随机噪声,而g将这个随机噪声转化为数据类型x,仍拿图片问题举例,这里g的输出就是一张图片。D是一个判别模型,对任何输入x,D(x)的输出是0-1范围内的一个实数,用来判断这个图片是一个真实图片的概率是多大。令Pr和Pg分别代表真实图像的分布与生成图像的分布,我们判别模型的目标函数如下:
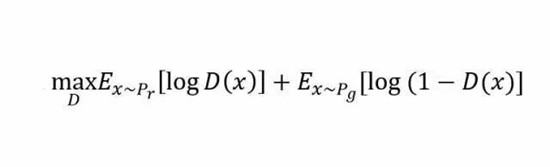
类似的生成模型的目标是让判别模型无法区分真实图片与生成图片,那么整个的优化目标函数如下:
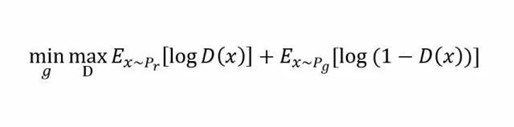
这个最大最小化目标函数如何进行优化呢?最直观的处理办法就是分别对D和g进行交互迭代,固定g,优化D,一段时间后,固定D再优化g,直到过程收敛。

一个简单的例子如下图所示:假设在训练开始时,真实样本分布、生成样本分布以及判别模型分别是图中的黑线、绿线和蓝线。可以看出,在训练开始时,判别模型是无法很好地区分真实样本和生成样本的。接下来当我们固定生成模型,而优化判别模型时,优化结果如第二幅图所示,可以看出,这个时候判别模型已经可以较好的区分生成数据和真实数据了。第三步是固定判别模型,改进生成模型,试图让判别模型无法区分生成图片与真实图片,在这个过程中,可以看出由模型生成的图片分布与真实图片分布更加接近,这样的迭代不断进行,直到最终收敛,生成分布和真实分布重合。
 以上就是生成式对抗网络的基本核心知识,下面我们看几个在实际中应用的例子
以上就是生成式对抗网络的基本核心知识,下面我们看几个在实际中应用的例子