一般来说,redis主从和mysql主从目的差不多,但redis主从配置很简单,主要在从节点配置文件指定主节点ip和端口,比如:slaveof 192.168.10.10 6379,然后启动主从,主从就搭建好了。redis主从中如果主节点发生故障,不会自动切换,需要借助redis的Sentinel(哨兵模式)或者keepalive来实现主的故障转移。
今天介绍下redis cluster集群模式:
redis集群是一个无中心的分布式redis存储架构,可以在多个节点之间进行数据共享,解决了redis高可用、可扩展等问题,redis集群提供了以下两个好处:
1)将数据自动切分(split)到多个节点
2)当集群中的某一个节点故障时,redis还可以继续处理客户端的请求。
一个 Redis 集群包含 16384 个哈希槽(hash slot),数据库中的每个数据都属于这16384个哈希槽中的一个。集群使用公式 CRC16(key) % 16384 来计算键 key 属于哪个槽。集群中的每一个节点负责处理一部分哈希槽。
集群中的主从复制
集群中的每个节点都有1个至N个复制品,其中一个为主节点,其余的为从节点,如果主节点下线了,集群就会把这个主节点的一个从节点设置为新的主节点,继续工作。这样集群就不会因为一个主节点的下线而无法正常工作。
==========从Redis3.x开始已经支持Load Balance功能了===========
Redis Cluster集群功能推出已经有一段时间了。在单机版的Redis中,每个Master之间是没有任何通信的,所以一般在Jedis客户端或者Codis这样的代理中做Pre-sharding。按照CAP理论来说,单机版的Redis属于保证CP(Consistency & Partition-Tolerancy)而牺牲A(Availability),也就说Redis能够保证所有用户看到相同的数据(一致性,因为Redis不自动冗余数据)和网络通信出问题时,暂时隔离开的子系统能继续运行(分区容忍性,因为Master之间没有直接关系,不需要通信),但是不保证某些结点故障时,所有请求都能被响应(可用性,某个Master结点挂了的话,那么它上面分片的数据就无法访问了)。
有了Cluster功能后,Redis从一个单纯的NoSQL内存数据库变成了分布式NoSQL数据库,CAP模型也从CP变成了AP。也就是说,通过自动分片和冗余数据,Redis具有了真正的分布式能力,某个结点挂了的话,因为数据在其他结点上有备份,所以其他结点顶上来就可以继续提供服务,保证了Availability。然而,也正因为这一点,Redis无法保证曾经的强一致性了。这也是CAP理论要求的,三者只能取其二。
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。一个Key到底属于哪个Slot由crc16(key) % 16384 决定。在Redis Cluster里对于负载均衡和HA相关都已经支持的相当完善了。
负载均衡(Load Balance):集群的Redis Instance之间可以迁移数据,以Slot为单位,但不是自动的,需要外部命令触发。
集群成员管理:集群的节点(Redis Instance)和节点之间两两定期交换集群内节点信息并且更新,从发送节点的角度看,这些信息包括:集群内有哪些节点,IP和PORT是什么,节点名字是什么,节点的状态(比如OK,PFAIL,FAIL,后面详述)是什么,包括节点角色(master 或者 slave)等。
关于可用性,集群由N组主从Redis Instance组成。
主可以没有从,但是没有从 意味着主宕机后主负责的Slot读写服务不可用。
一个主可以有多个从,主宕机时,某个从会被提升为主,具体哪个从被提升为主,协议类似于Raft,参见这里。如何检测主宕机?Redis Cluster采用quorum+心跳的机制。从节点的角度看,节点会定期给其他所有的节点发送Ping,cluster-node-timeout(可配置,秒级)时间内没有收到对方的回复,则单方面认为对端节点宕机,将该节点标为PFAIL状态。通过节点之间交换信息收集到quorum个节点都认为这个节点为PFAIL,则将该节点标记为FAIL,并且将其发送给其他所有节点,其他所有节点收到后立即认为该节点宕机。从这里可以看出,主宕机后,至少cluster-node-timeout时间内该主所负责的Slot的读写服务不可用。
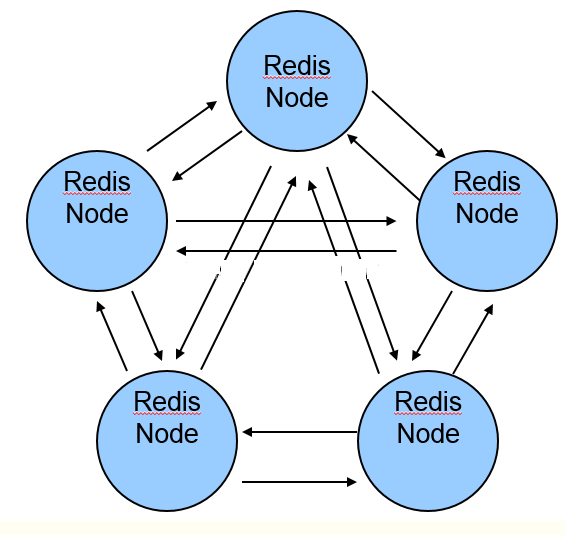
Redis Cluster的特点如下:
- 节点自动发现
- slave->master选举,集群容错
- Hot resharding:在线分片
- 集群管理:clusterxxx
- 基于配置(nodes-port.conf)的集群管理
- ASK 转向/MOVED转向机制
- 布署无需指定master
- 可以支持超过1,000台节点的集群
======Redis-Cluster采用无中心结构,每个节点保存数据和整个集群状态,每个节点都和其他所有节点连接======
redis-cluster架构图如下:

其结构特点:
- 所有的redis节点彼此互联(PING-PONG机制),内部使用二进制协议优化传输速度和带宽。
- 节点的fail是通过集群中超过半数的节点检测失效时才生效。
- 客户端与redis节点直连,不需要中间proxy层.客户端不需要连接集群所有节点,连接集群中任何一个可用节点即可。
- redis-cluster把所有的物理节点映射到[0-16383]slot上(不一定是平均分配),cluster 负责维护node<->slot<->value。
- Redis集群预分好16384个桶,当需要在 Redis 集群中放置一个 key-value 时,根据 CRC16(key) mod 16384的值,决定将一个key放到哪个桶中。
redis cluster集群是为了降低单节点或单纯主从redis的压力,主主节点之间是不存在同步关系的,各主从之间的数据存在同步关系。有多少主节点,就会把16384个哈希槽(hash slot)平均分配到这些主节点上,当往redis里写入数据时,会根据哈希算法算出这个数的哈希槽,决定它放到哪一个主节点上,然后这个主节点的从节点去自动同步。在客户端随便连接一个主节点即可,主节点之间会进行内部跳转!当取对应数据时,各节点之间会自动跳转到所取数据所在的主节点上!
1)redis cluster节点分配
假设现有有三个主节点分别是:A、 B、C ,它们可以是一台机器上的三个端口,也可以是三台不同的服务器。那么,采用哈希槽 (hash slot)的方式
来分配16384个slot 的话,它们三个节点分别承担的slot 区间是:
节点A 覆盖0-5460;
节点B 覆盖5461-10922;
节点C 覆盖10923-16383.
获取数据:
如果存入一个值,按照redis cluster哈希槽的算法: CRC16('key')%16384 = 6782。 那么就会把这个key 的存储分配到 B 上了。同样,当我连接
(A,B,C)任何一个节点想获取'key'这个key时,也会这样的算法,然后内部跳转到B节点上获取数据
新增一个主节点:
新增一个节点D,redis cluster的这种做法是从各个节点的前面各拿取一部分slot到D上,我会在接下来的实践中实验。大致就会变成这样:
节点A 覆盖1365-5460
节点B 覆盖6827-10922
节点C 覆盖12288-16383
节点D 覆盖0-1364,5461-6826,10923-12287
同样删除一个节点也是类似,移动完成后就可以删除这个节点了。
2)Redis Cluster主从模式
redis cluster 为了保证数据的高可用性,加入了主从模式,一个主节点对应一个或多个从节点,主节点提供数据存取,从节点则是从主节点拉取数据
备份,当这个主节点挂掉后,就会有这个从节点选取一个来充当主节点,从而保证集群不会挂掉。
上面那个例子里, 集群有A、B、C三个主节点, 如果这3个节点都没有加入从节点,如果B挂掉了,我们就无法访问整个集群了。A和C的slot也无法访问。
所以在集群建立的时候,一定要为每个主节点都添加了从节点, 比如像这样, 集群包含主节点A、B、C, 以及从节点A1、B1、C1, 那么即使B挂掉系统也
可以继续正确工作。B1节点替代了B节点,所以Redis集群将会选择B1节点作为新的主节点,集群将会继续正确地提供服务。 当B重新开启后,它就会变成B1的从节点。
不过需要注意,如果节点B和B1同时挂了,Redis集群就无法继续正确地提供服务了。
===========废话不多说,下面记录下搭建redis cluster集群==========
由于最小的redis集群需要3个主节点(即Redis Cluster集群至少需要3个master节点,也就是说至少需要6个节点才能构建Redis cluster集群),一台机器可运行多个redis实例(一般使用两台机器,每台启动3个redis实例,即三个主节点,三个从节点)。很多案例使用单台服务器开6个端口,操作差不多,只是配置基本相对简单点,多台服务器更接近生产环境。【当集群最开始创建好后,要记住各节点的主从关系(或是创建的时候指定主从关系);若是其中一台机器重启,重启后,需重新将其加入到redis cluster集群中;这就需要将这台机器上的各节点之前的从节点变为主节点(客户端执行slaveof no one),然后再根据新的主节点添加这台机器的各节点到集群中,添加后变为从节点】
本案例redis cluster节点信息:
redis01
172.16.51.175:7000
172.16.51.175:7001
172.16.51.175:7002
redis02
172.16.51.176:7003
172.16.51.176:7004
172.16.51.176:7005
redis03
172.16.51.178:7006
172.16.51.178:7007
172.16.51.178:7008
先说下redis01节点的部署过程(其他两台节点部署过程一致)
个人运维习惯,会专门创建一个app账号,用户部署应用程序。本案例应用程序都部署在/data目录下,将/data权限设置成app
[root@bl-redis01 ~]# useradd app
[root@bl-redis01 ~]# passwd app
[root@bl-redis01 ~]# chown -R app.app /data
前提准备
1)安裝 GCC 编译工具 不然会有编译不过的问题
[root@bl-redis01 ~]# yum install -y gcc g++ make gcc-c++ kernel-devel automake autoconf libtool make wget tcl vim ruby rubygems unzip git
2)升级所有的包,防止出现版本过久不兼容问题
[root@bl-redis01 ~]# yum -y update
3)关闭防火墙 节点之前需要开放指定端口,为了方便,生产不要禁用
[root@bl-redis01 ~]# /etc/init.d/iptables stop
[root@bl-redis01 ~]# setenforce 0
[root@bl-redis01 ~]# vim /etc/sysconfig/selinux
......
SELINUX=disabled
......
redis cluster集群部署
4)下载并编译安装redis
[root@bl-redis01 ~]# su - app
[app@bl-redis01 ~]$ mkdir /data/software/
[app@bl-redis01 software]$ wget http://download.redis.io/releases/redis-4.0.1.tar.gz
[app@bl-redis01 software]$ tar -zvxf redis-4.0.1.tar.gz
[app@bl-redis01 software]$ mv redis-4.0.1 /data/
[app@bl-redis01 software]$ cd /data/redis-4.0.1/
[app@bl-redis01 redis-4.0.1]$ make
--------------------------------------------------------------------------------------
如果因为上次编译失败,有残留的文件,做法如下:
[app@bl-redis01 redis-4.0.1]$ make distclean
--------------------------------------------------------------------------------------
5)创建节点
首先在172.16.51.175机器(redis01)上/data/redis-4.0.1目录下创建redis-cluster目录
[app@bl-redis01 redis-4.0.1]$ mkdir /data/redis-4.0.1/redis-cluster
接着在redis-cluster目录下,创建名为7000、7001、7002的目录
[app@bl-redis01 redis-cluster]$ mkdir 7000
[app@bl-redis01 redis-cluster]$ mkdir 7001
[app@bl-redis01 redis-cluster]$ mkdir 7002
分别修改这三个配置文件redis.conf
[app@bl-redis01 redis-4.0.1]$ cd redis-cluster/
[app@bl-redis01 redis-cluster]$ ll
total 12
drwxrwxr-x 2 app app 4096 Nov 16 17:38 7000
drwxrwxr-x 2 app app 4096 Nov 16 17:39 7001
drwxrwxr-x 2 app app 4096 Nov 16 17:39 7002
[app@bl-redis01 redis-cluster]$ cat 7000/redis.conf
port 7000
bind 172.16.51.175
daemonize yes
pidfile /var/run/redis_7000.pid
cluster-enabled yes
cluster-config-file nodes_7000.conf
cluster-node-timeout 10100
appendonly yes
[app@bl-redis01 redis-cluster]$ cat 7001/redis.conf
port 7001
bind 172.16.51.175
daemonize yes
pidfile /var/run/redis_7001.pid
cluster-enabled yes
cluster-config-file nodes_7001.conf
cluster-node-timeout 10100
appendonly yes
[app@bl-redis01 redis-cluster]$ cat 7002/redis.conf
port 7002
bind 172.16.51.175
daemonize yes
pidfile /var/run/redis_7002.pid
cluster-enabled yes
cluster-config-file nodes_7002.conf
cluster-node-timeout 10100
appendonly yes
----------------------------------------------------------------------------------------------------
redis.conf的配置说明:
#端口7000,7001,7002
port 7000
#默认ip为127.0.0.1,需要改为其他节点机器可访问的ip,否则创建集群时无法访问对应的端口,无法创建集群
bind 172.16.51.175
#redis后台运行
daemonize yes
#pidfile文件对应7000,7001,7002
pidfile /var/run/redis_7000.pid
#开启集群,把注释#去掉
cluster-enabled yes
#集群的配置,配置文件首次启动自动生成 7000,7001,7002
cluster-config-file nodes_7000.conf
#请求超时,默认15秒,可自行设置
cluster-node-timeout 10100
#aof日志开启,有需要就开启,它会每次写操作都记录一条日志
appendonly yes
----------------------------------------------------------------------------------------------------
接着在另外两台机器上(172.16.51.176,172.16.51.178)重复以上三步,只是把目录改为7003、7004、7005和7006、7007、7008,对应的配置文件也按照这个规则修改即可(即修改redis.conf文件中的端口就行了)
6)启动集群(依次启动7000-7008端口)
#第一个节点机器上执行 3个节点
[app@bl-redis01 redis-cluster]$ for((i=0;i<=2;i++)); do /data/redis-4.0.1/src/redis-server /data/redis-4.0.1/redis-cluster/700$i/redis.conf; done
#第二个节点机器上执行 3个节点
[app@bl-redis01 redis-cluster]$ for((i=3;i<=5;i++)); do /data/redis-4.0.1/src/redis-server /data/redis-4.0.1/redis-cluster/700$i/redis.conf; done
#第三个节点机器上执行 3个节点
[app@bl-redis01 redis-cluster]$ for((i=6;i<=8;i++)); do /data/redis-4.0.1/src/redis-server /data/redis-4.0.1/redis-cluster/700$i/redis.conf; done
7)检查服务
检查各 Redis 各个节点启动情况
[app@bl-redis01 redis-cluster]$ ps -ef | grep redis
app 2564 2405 0 20:13 pts/0 00:00:00 grep redis
app 15197 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7000 [cluster]
app 15199 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7001 [cluster]
app 15201 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7002 [cluster]
[app@bl-redis01 redis-cluster]$ ps -ef | grep redis
app 2566 2405 0 20:13 pts/0 00:00:00 grep redis
app 15197 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7000 [cluster]
app 15199 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7001 [cluster]
app 15201 1 0 17:57 ? 00:00:05 /data/redis-4.0.1/src/redis-server 172.16.51.175:7002 [cluster]
8)安装 Ruby(需要切换到root账号下进行安装,app账号下权限不够)
[root@bl-redis01 ~]# yum -y install ruby ruby-devel rubygems rpm-build
[root@bl-redis01 ~]# gem install redis
-----------------------------------------------------------------------------------------------------
注意:在centos6.x下执行上面的"gem install redis"操作可能会报错,坑很多!
默认yum安装的ruby版本是1.8.7,版本太低,需要升级到ruby2.2以上,否则执行上面安装会报错!
首先安装rvm(或者直接下载证书:https://pan.baidu.com/s/1slTyJ7n 密钥:7uan 下载并解压后直接执行"curl -L get.rvm.io | bash -s stable"即可)
[root@bl-redis01 ~]# curl -L get.rvm.io | bash -s stable //可能会报错,需要安装提示进行下面一步操作
[root@bl-redis01 ~]# curl -sSL https://rvm.io/mpapis.asc | gpg2 --import - //然后再接着执行:curl -L get.rvm.io | bash -s stable
[root@bl-redis01 ~]# find / -name rvm.sh
/etc/profile.d/rvm.sh
[root@bl-redis01 ~]# source /etc/profile.d/rvm.sh
[root@bl-redis01 ~]# rvm requirements
然后升级ruby到2.3
[root@bl-redis01 ~]# rvm install ruby 2.3.1
[root@bl-redis01 ~]# ruby -v
ruby 2.3.1p112 (2016-04-26 revision 54768) [x86_64-linux]
列出所有ruby版本
[root@bl-redis01 ~]# rvm list
设置默认的版本
[root@bl-redis01 ~]# rvm --default use 2.3.1
更新下载源
[root@bl-redis01 ~]# gem sources --add https://gems.ruby-china.org/ --remove https://rubygems.org
https://gems.ruby-china.org/ added to sources
source https://rubygems.org not present in cache
[root@bl-redis01 ~]# gem sources
*** CURRENT SOURCES ***
https://rubygems.org/
https://gems.ruby-china.org/
最后就能顺利安装了
[root@bl-redis01 src]# gem install redis
Successfully installed redis-4.0.1
Parsing documentation for redis-4.0.1
Done installing documentation for redis after 1 seconds
1 gem installed
-----------------------------------------------------------------------------------------------------
9)创建集群
千万注意:在任意一台上运行即可,不要在每台机器上都运行,一台就够了!!!!
Redis 官方提供了 redis-trib.rb 这个工具,就在解压目录的 src 目录中
[root@bl-redis01 ~]# su - app
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-trib.rb create --replicas 1 172.16.51.175:7000 172.16.51.175:7001 172.16.51.175:7002 172.16.51.176:7003 172.16.51.176:7004 172.16.51.176:7005 172.16.51.178:7006 172.16.51.178:7007 172.16.51.178:7008
出现下面信息,从下面信息可以看出,本案例三台服务器启动9个实例,配置成4主5从,其中有一个是一主两从,其他3个都是一主一从。
>>> Creating cluster
>>> Performing hash slots allocation on 9 nodes...
Using 4 masters:
172.16.51.175:7000
172.16.51.176:7003
172.16.51.178:7006
172.16.51.175:7001
Adding replica 172.16.51.176:7004 to 172.16.51.175:7000
Adding replica 172.16.51.178:7007 to 172.16.51.176:7003
Adding replica 172.16.51.175:7002 to 172.16.51.178:7006
Adding replica 172.16.51.176:7005 to 172.16.51.175:7001
Adding replica 172.16.51.178:7008 to 172.16.51.175:7000
M: 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf 172.16.51.175:7000
slots:0-4095 (4096 slots) master
M: 44c81c15b01d992cb9ede4ad35477ec853d70723 172.16.51.175:7001
slots:12288-16383 (4096 slots) master
S: 38f03c27af39723e1828eb62d1775c4b6e2c3638 172.16.51.175:7002
replicates f1abb62a8c9b448ea14db421bdfe3f1d8075189c
M: 987965baf505a9aa43e50e46c76189c51a8f17ec 172.16.51.176:7003
slots:4096-8191 (4096 slots) master
S: 6555292fed9c5d52fcf5b983c441aff6f96923d5 172.16.51.176:7004
replicates 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf
S: 2b5ba254a0405d4efde4c459867b15176f79244a 172.16.51.176:7005
replicates 44c81c15b01d992cb9ede4ad35477ec853d70723
M: f1abb62a8c9b448ea14db421bdfe3f1d8075189c 172.16.51.178:7006
slots:8192-12287 (4096 slots) master
S: eb4067373d36d8a8df07951f92794e67a6aac022 172.16.51.178:7007
replicates 987965baf505a9aa43e50e46c76189c51a8f17ec
S: 2919e041dd3d1daf176d6800dcd262f4e727f366 172.16.51.178:7008
replicates 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf
Can I set the above configuration? (type 'yes' to accept): yes
输入 yes
>>> Nodes configuration updated
>>> Assign a different config epoch to each node
>>> Sending CLUSTER MEET messages to join the cluster
Waiting for the cluster to join.........
>>> Performing Cluster Check (using node 172.16.51.175:7000)
M: 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf 172.16.51.175:7000
slots:0-4095 (4096 slots) master
2 additional replica(s)
S: 6555292fed9c5d52fcf5b983c441aff6f96923d5 172.16.51.176:7004
slots: (0 slots) slave
replicates 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf
M: 44c81c15b01d992cb9ede4ad35477ec853d70723 172.16.51.175:7001
slots:12288-16383 (4096 slots) master
1 additional replica(s)
S: 2919e041dd3d1daf176d6800dcd262f4e727f366 172.16.51.178:7008
slots: (0 slots) slave
replicates 7c622ac191edd40dd61d9b79b27f6f69d02a5bbf
M: f1abb62a8c9b448ea14db421bdfe3f1d8075189c 172.16.51.178:7006
slots:8192-12287 (4096 slots) master
1 additional replica(s)
S: eb4067373d36d8a8df07951f92794e67a6aac022 172.16.51.178:7007
slots: (0 slots) slave
replicates 987965baf505a9aa43e50e46c76189c51a8f17ec
S: 38f03c27af39723e1828eb62d1775c4b6e2c3638 172.16.51.175:7002
slots: (0 slots) slave
replicates f1abb62a8c9b448ea14db421bdfe3f1d8075189c
S: 2b5ba254a0405d4efde4c459867b15176f79244a 172.16.51.176:7005
slots: (0 slots) slave
replicates 44c81c15b01d992cb9ede4ad35477ec853d70723
M: 987965baf505a9aa43e50e46c76189c51a8f17ec 172.16.51.176:7003
slots:4096-8191 (4096 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
10)关闭集群
推荐做法:
[app@bl-redis01 ~]$ pkill redis
[app@bl-redis02 ~]$ pkill redis
[app@bl-redis03 ~]$ pkill redis
或者循环节点逐个关闭
[app@bl-redis01 ~]$ for((i=0;i<=2;i++)); do /opt/redis-4.0.1/src/redis-cli -c -h 172.16.51.175 -p 700$i shutdown; done
[app@bl-redis02 ~]$ for((i=3;i<=5;i++)); do /opt/redis-4.0.1/src/redis-cli -c -h 172.16.51.176 -p 700$i shutdown; done
[app@bl-redis03 ~]$ for((i=6;i<=8;i++)); do /opt/redis-4.0.1/src/redis-cli -c -h 172.16.51.178 -p 700$i shutdown; done
11)集群验证
连接集群测试
参数-C可连接到集群,因为redis.conf将bind改为了ip地址,所以-h参数不可以省略,-p参数为端口号
可以先在172.16.51.175机器redis 7000 的节点set一个key
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-cli -h 172.16.51.175 -c -p 7000
172.16.51.175:7000> set name www.ymq.io
-> Redirected to slot [5798] located at 172.16.51.176:7003
OK
172.16.51.176:7003> get name
"www.ymq.io"
172.16.51.176:7003>
由上面信息可发现redis set name 之后重定向到172.16.51.176机器 redis 7003 这个节点
然后在172.16.51.178机器redis 7008 的节点get一个key
[app@bl-redis03 ~]$ /data/redis-4.0.1/src/redis-cli -h 172.16.51.178 -c -p 7008
172.16.51.178:7008> get name
-> Redirected to slot [5798] located at 172.16.51.176:7003
"www.ymq.io"
172.16.51.176:7003>
发现redis get name 重定向到172.16.51.176机器 redis 7003 这个节点.
如果看到这样的现象,说明redis cluster集群已经是可用的了!!!!!!
12)检查集群状态(通过下面的命令,可以看到本案例实现的是4主5从,4个主节点会默认分配到三个机器上,每个机器上都要有master;另:创建集群的时候可以指定master和slave。这里我是默认创建的)
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-cli -h 172.16.51.175 -c -p 7000
172.16.51.175:7000>
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-trib.rb check 172.16.51.175:7000
>>> Performing Cluster Check (using node 172.16.51.175:7000)
M: 5a43e668f53ff64da68be31afe6dc6ea1f3c14c5 172.16.51.175:7000
slots:0-4095 (4096 slots) master
2 additional replica(s)
M: c64b0839e0199f73c5c192cc8c90f12c999f79b2 172.16.51.175:7001
slots:12288-16383 (4096 slots) master
1 additional replica(s)
S: 81347f01cf38d8f0faef1ad02676ebb4cffbec9e 172.16.51.176:7005
slots: (0 slots) slave
replicates c64b0839e0199f73c5c192cc8c90f12c999f79b2
M: da5dde3f2f02c232784bf3163f5f584b8cf046f2 172.16.51.178:7006
slots:8192-12287 (4096 slots) master
1 additional replica(s)
M: b217ab2a6c05497af3b2a859c1bb6b3fae5e0d92 172.16.51.176:7003
slots:4096-8191 (4096 slots) master
1 additional replica(s)
S: 0420c49fbc9f1fe16066d189265cca2f5e71c86e 172.16.51.178:7007
slots: (0 slots) slave
replicates b217ab2a6c05497af3b2a859c1bb6b3fae5e0d92
S: 5ad89453fb36e50ecc4560de6b4acce1dbbb78b3 172.16.51.176:7004
slots: (0 slots) slave
replicates 5a43e668f53ff64da68be31afe6dc6ea1f3c14c5
S: bbd1f279b99b95cf00ecbfab22b6b8dd5eb05989 172.16.51.178:7008
slots: (0 slots) slave
replicates 5a43e668f53ff64da68be31afe6dc6ea1f3c14c5
S: e95407b83bfeb30e3cc537161eadc372d6aa1fa2 172.16.51.175:7002
slots: (0 slots) slave
replicates da5dde3f2f02c232784bf3163f5f584b8cf046f2
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.
13)列出集群节点
列出集群当前已知的所有节点(node),以及这些节点的相关信息
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-cli -h 172.16.51.175 -c -p 7000
172.16.51.175:7000> cluster nodes
5a43e668f53ff64da68be31afe6dc6ea1f3c14c5 172.16.51.175:7000@17000 myself,master - 0 1510836027000 1 connected 0-4095
c64b0839e0199f73c5c192cc8c90f12c999f79b2 172.16.51.175:7001@17001 master - 0 1510836030068 2 connected 12288-16383
81347f01cf38d8f0faef1ad02676ebb4cffbec9e 172.16.51.176:7005@17005 slave c64b0839e0199f73c5c192cc8c90f12c999f79b2 0 1510836031000 6 connected
da5dde3f2f02c232784bf3163f5f584b8cf046f2 172.16.51.178:7006@17006 master - 0 1510836031000 7 connected 8192-12287
b217ab2a6c05497af3b2a859c1bb6b3fae5e0d92 172.16.51.176:7003@17003 master - 0 1510836030000 4 connected 4096-8191
0420c49fbc9f1fe16066d189265cca2f5e71c86e 172.16.51.178:7007@17007 slave b217ab2a6c05497af3b2a859c1bb6b3fae5e0d92 0 1510836029067 8 connected
5ad89453fb36e50ecc4560de6b4acce1dbbb78b3 172.16.51.176:7004@17004 slave 5a43e668f53ff64da68be31afe6dc6ea1f3c14c5 0 1510836032672 5 connected
bbd1f279b99b95cf00ecbfab22b6b8dd5eb05989 172.16.51.178:7008@17008 slave 5a43e668f53ff64da68be31afe6dc6ea1f3c14c5 0 1510836031000 9 connected
e95407b83bfeb30e3cc537161eadc372d6aa1fa2 172.16.51.175:7002@17002 slave da5dde3f2f02c232784bf3163f5f584b8cf046f2 0 1510836031672 7 connected
14)打印集群信息
[app@bl-redis01 ~]$ /data/redis-4.0.1/src/redis-cli -h 172.16.51.175 -c -p 7000
172.16.51.175:7000> cluster info
cluster_state:ok
cluster_slots_assigned:16384
cluster_slots_ok:16384
cluster_slots_pfail:0
cluster_slots_fail:0
cluster_known_nodes:9
cluster_size:4
cluster_current_epoch:9
cluster_my_epoch:1
cluster_stats_messages_ping_sent:8627
cluster_stats_messages_pong_sent:8581
cluster_stats_messages_sent:17208
cluster_stats_messages_ping_received:8573
cluster_stats_messages_pong_received:8626
cluster_stats_messages_meet_received:8
cluster_stats_messages_received:17207
------------------------------------------------------------------------------------------------
[root@bl-redis01 src]# pwd
/data/redis-4.0.1/src
[root@bl-redis01 src]# ./redis-trib.rb help
Usage: redis-trib <command> <options> <arguments ...>
create host1:port1 ... hostN:portN
--replicas <arg>
check host:port
info host:port
fix host:port
--timeout <arg>
reshard host:port
--from <arg>
--to <arg>
--slots <arg>
--yes
--timeout <arg>
--pipeline <arg>
rebalance host:port
--weight <arg>
--auto-weights
--use-empty-masters
--timeout <arg>
--simulate
--pipeline <arg>
--threshold <arg>
add-node new_host:new_port existing_host:existing_port
--slave
--master-id <arg>
del-node host:port node_id
set-timeout host:port milliseconds
call host:port command arg arg .. arg
import host:port
--from <arg>
--copy
--replace
help (show this help)
For check, fix, reshard, del-node, set-timeout you can specify the host and port of any working node in the cluster.
上面已经多次出现了slot这个词,略为解释一下:
redis-cluster把整个集群的存储空间划分为16384个slot(译为:插槽?),当9个实例分为3主6从时,相当于整个cluster中有3组HA的节点,
3个master会平均分摊所有slot,每次向cluster中的key做操作时(比如:读取/写入缓存),redis会对key值做CRC32算法处理,得到一个数值,
然后再对16384取模,通过余数判断该缓存项应该落在哪个slot上,确定了slot,也就确定了保存在哪个master节点上,当cluster扩容或删除
节点时,只需要将slot重新分配即可(即:把部分slot从一些节点移动到其它节点)。
---------------------------------------------------------------------------------------------------------
在代码里连接以上redis cluster集群节点配置如下:
spring.redis.cluster.nodes = 172.16.51.175:7000,172.16.51.175:7001,172.16.51.175:7002,172.16.51.176:7003,172.16.51.176:7004,172.16.51.176:7005,172.16.51.178:7006,172.16.51.178:7007,172.16.51.178:7008
==========================集群模式配置======================
以下这种方式貌似不能按照自己的思路添加主从 redis-trib.rb create --replicas 1 192.168.1.101:6381 192.168.1.102:6382 192.168.1.103:6383 192.168.1.102:6381 192.168.1.103:6382 192.168.1.101:6383 思路改为先加主库 再加从库 添加主库 redis-trib.rb create 192.168.1.101:6381 192.168.1.102:6382 192.168.1.103:6383 添加从库 把 102的6381 作为从库加入 101的6381 redis-trib.rb add-node --slave 192.168.1.102:6381 192.168.1.101:6381 redis-trib.rb add-node --slave 192.168.1.103:6382 192.168.1.102:6382 redis-trib.rb add-node --slave 192.168.1.101:6383 192.168.1.103:6383 检测 redis-trib.rb check 192.168.1.101:6381 redis-trib.rb check 192.168.1.102:6382 redis-trib.rb check 192.168.1.103:6383
==========================redis cluster常见的几个问题======================
1)问题一
由于redis clster集群节点宕机(或节点的redis服务重启),导致了部分slot数据分片丢失;在用check检查集群运行状态时,遇到错误;
[root@slave2 redis]# redis-trib.rb check 192.168.1.100:7000
........
[ERR] Not all 16384 slots are covered by nodes.
原因分析:
这个往往是由于主node移除了,但是并没有移除node上面的slot,从而导致了slot总数没有达到16384,其实也就是slots分布不正确。
所以在删除节点的时候一定要注意删除的是否是Master主节点。
解决办法:
官方是推荐使用redis-trib.rb fix 来修复集群。通过cluster nodes看到7001这个节点被干掉了。可以按照下面操作进行修复
[root@slave2 redis]# redis-trib.rb fix 192.168.1.100:7000
修复完成后再用check命令检查下是否正确(查看别的节点)
[root@slave2 redis]# redis-trib.rb check 192.168.1.101:7002
只要输入任意集群中节点即可,会自动检查所有相关节点。
可以查看相应的输出看下是否是每个Master都有了slots。
如果分布不均匀那可以使用下面的方式重新分配slot:
[root@slave2 redis]# redis-trib.rb reshard 192.168.1.100:7000
特别注意:
在部分节点重启后重新回到集群中的过程期间,在check集群状态的时候会出现"[ERR] Not all 16384 slots are covered by nodes."这个报错,
需要稍微等待一会,等重启节点完全回到集群中后,这个报错就会消失!
======================================================
问题二:
在往redis cluster集群环境中添加节点时遇到一个问题,提示新增的Node不为空:
[root@slave2 redis]# redis-trib.rb add-node --slave 192.168.1.103:7004 192.168.1.102:7002
.......
[ERR] Node 192.168.1.103:7004 is not empty. Either the nodealready knows other nodes (check with CLUSTER NODES) or
contains some key in database 0.
解决办法:(如果redis cluster所有节点同时断电同时宕机, 则节点重启后, 只能重新创建集群, 之前的集群数据全部丢失! 重新创建集群前,各节点要如下操作)
1)将192.168.1.103节点机redis下的aof、rdb等本地备份文件全部删除
2)同时将新Node的集群配置文件删除,也即是删除redis.conf里面cluster-config-file指定所在的文件;
3)"redis-cli -c -h 192.168.1.103 -p 7004"登陆后,执行 "flushdb"命令进行清除操作
4)重启reds服务
5)最后再次执行节点添加操作
=============================================================================================
温馨提示:
- 集群中只要有一组master-slave节点同时挂点,则集群服务也会挂掉;待该组master和slave节点的redis恢复后,这部分slot槽的数据也会丢失。
- 集群中1/2或master节点挂掉,则集群服务也会挂掉;待这些master节点服务重启后,会自动加入到集群中,需等待一段时间,集群恢复正常,数据不会丢失。
- 集群中master节点关闭,需要等待一小段时间,它对应的slave节点就会变成master节点,集群服务正常,数据会随之到新的maser节点的slot。
- master节点挂掉后,重启redis服务(一定要在原来的aof和nodes*.conf文件路径下启动),则会自动加入到cluster集群中,并会变成slave节点。
- 新添加的master节点的slot默认为0,master主节点如果没有slots,存取数据就都不会被选中! 故要为新增加的master节点进行reshard重新分配slot。
- slave从节点的slot为0,数据不会存储在slave节点!只会存储在master主节点中,master节点才有slot数值。
======================================================
注意:每一组的master-slave节点不能同时挂掉或短时间内先后挂掉,否则这部分slot内的数据就会丢失。
比如说一主一从,当master节点挂掉后,数据都保存到slave节点内,稍过一会,slave节点就会被选举为新的master节点。
老的master节点重启后重新回到集群中,并自动变为它原来的slave(现在是新的master)的slave节点,并自动同步数据。
这个时候新的master节点如果挂掉,则数据同样会保存到新的slave节点中,新的slave节点过一段时间同样会被再次选举为新的master,如此类推....
如果master节点和它的slave节点同时挂掉,或者在其中一个挂掉后还没有来得及恢复到集群中,另一个就挂掉,这种情况下,这部分slot槽的数据肯定就没有了。
所以说,一般会重启一个节点,待该节点恢复到集群中后,再可以重启它对应的slave或master节点。
redis作为纯缓存服务时,数据丢失,一般对业务是无感的,不影响业务,丢失后会再次写入。但如果作为存储服务(即作为存储数据库),数据丢失则对业务影响很大。
不过一般业务场景,存储数据库会用mysql、oracle或mongodb。
======================================================
redis cluster集群节点重启后,要想恢复集群状态,正确的做法是:
1)要在各个节点原来的appendonly.aof ,dump.rdb,nodes_*.conf 文件所在路径下重启redis服务。这样就能确保redis启动后用到之前的数据文件。
(可以使用find命令查找这些文件所在路径,然后在这个路径下启动redis服务)
2)各个节点的redis服务正常启动后,就可以直接查看redis cluster状态了,检查集群状态是否恢复。
注意:
一定要在原来的数据文件的路径下启动redis,如果启动的路径错误,则读取的数据文件就不是之前的了,这样集群就很难恢复了。这个时候就需要删除之前的数据文件,
重新创建集群了。(或者直接在/data/redis-4.0.6/redis-cluster/700*目录下的redis.conf文件里的cluster-config-file指定文件的绝对路径)
集群节点的redis服务重启后,check集群状态,如有下面告警信息,处理如下:
[root@redis-node01 redis-cluster]# /data/redis-4.0.6/src/redis-trib.rb check 192.168.1.100:7000
...........
...........
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
[WARNING] Node 192.168.1.100:7000 has slots in importing state (5798,11479).
[WARNING] Node 192.168.1.100:7001 has slots in importing state (1734,5798).
[WARNING] Node 192.168.1.101:7002 has slots in importing state (11479).
[WARNING] The following slots are open: 5798,11479,1734
>>> Check slots coverage...
[OK] All 16384 slots covered.
解决办法:
一定要登录到告警信息中的节点和对应的端口上进行操作。
执行"cluster setslot <slot> stable"命令,表示取消对槽slot 的导入( import)或者迁移( migrate)。
执行后,这部分slot槽的数据就没了。
[root@redis-node01 redis-cluster]# /data/redis-4.0.6/src/redis-cli -h 192.168.1.100 -c -p 7000
192.168.1.100:7000> cluster setslot 5798 stable
OK
192.168.1.100:7000> cluster setslot 11479 stable
OK
[root@redis-node01 redis-cluster]# /data/redis-4.0.6/src/redis-cli -h 192.168.1.100 -c -p 7001
192.168.1.100:7001> cluster setslot 1734 stable
OK
192.168.1.100:7001> cluster setslot 5798 stable
OK
[root@redis-node01 redis-cluster]# /data/redis-4.0.6/src/redis-cli -h 192.168.1.101 -c -p 7002
192.168.1.101:7002> cluster setslot 11479 stable
OK
再次检查redis cluster集群状态,就会发现一切正常了!
[root@redis-node01 redis-cluster]# /data/redis-4.0.6/src/redis-trib.rb check 192.168.1.100:7000
>>> Performing Cluster Check (using node 192.168.1.100:7000)
M: 39737de1c48fdbaec304f0d11294286593553365 192.168.1.100:7000
slots:0-5460 (5461 slots) master
1 additional replica(s)
S: 61a0cc84069ced156b6e1459bb71cab225182385 192.168.1.101:7003
slots: (0 slots) slave
replicates 39737de1c48fdbaec304f0d11294286593553365
S: 75de8c46eda03aee1afdd39de3ffd39cc42a5eec 172.16.60.209:7005
slots: (0 slots) slave
replicates 70a24c750995e2f316ee15320acb73441254a7aa
M: 70a24c750995e2f316ee15320acb73441254a7aa 192.168.1.101:7002
slots:5461-10922 (5462 slots) master
1 additional replica(s)
S: 5272bd14768e3e32e165284c272525a7da47b47e 192.168.1.100:7001
slots: (0 slots) slave
replicates c1b71d52b0d804f499c9166c0c1f4e3c35077ee9
M: c1b71d52b0d804f499c9166c0c1f4e3c35077ee9 172.16.60.209:7004
slots:10923-16383 (5461 slots) master
1 additional replica(s)
[OK] All nodes agree about slots configuration.
>>> Check for open slots...
>>> Check slots coverage...
[OK] All 16384 slots covered.