一、DRBD介绍
DRBD(Distributed ReplicatedBlock Device)是一种基于软件的,无共享,分布式块设备复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等) 进行镜像。也就是说当某一个应用程序完成写操作后,它提交的数据不仅仅会保存在本地块设备上,DRBD也会将这份数据复制一份,通过网络传输到另一个节点的块设 备上,这样,两个节点上的块设备上的数据将会保存一致,这就是镜像功能。 DRBD是由内核模块和相关脚本而构成,用以构建高可用性的集群,其实现方式是通过网络来镜像整个设备。它允许用户在远程机器上建立一个本地块设备的实时镜像, 与心跳连接结合使用,可以把它看作是一种网络RAID,它允许用户在远程机器上建立一个本地块设备的实时镜像。 DRBD工作在内核当中,类似于一种驱动模块。DRBD工作的位置在文件系统的buffer cache和磁盘调度器之间,通过tcp/ip发给另外一台主机到对方的tcp/ip最终发送 给对方的drbd,再由对方的drbd存储在本地对应磁盘 上,类似于一个网络RAID-1功能。在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵。本地(主节点) 与远程主机(备节点)的数据可以保 证实时同步。当本地系统出现故障时,远程主机上还会保留有一份相同的数据,可以继续使用。
二、DRDB的工作原理
DRBD是linux的内核的存储层中的一个分布式存储系统,可用使用DRBD在两台Linux服务器之间共享块设备,共享文件系统和数据。类似于一个网络RAID-1的功能,
其工作原理的架构图如下:
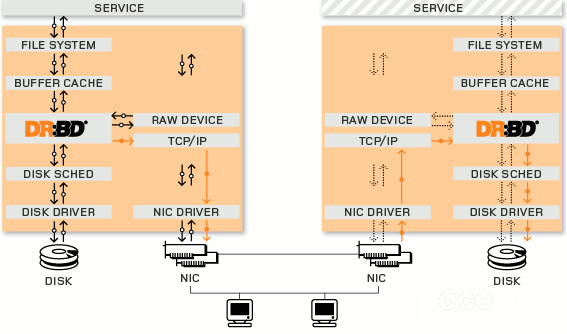
DRBD底层设备支持
DRBD需要构建在底层设备之上,然后构建出一个块设备出来。对于用户来说,一个DRBD设备,就像是一块物理的磁盘,可以在上面内创建文件系统。 DRBD所支持的底层设备有以下这些类: 1)一个磁盘,或者是磁盘的某一个分区; 2)一个soft raid 设备; 3)一个LVM的逻辑卷; 4)一个EVMS(Enterprise Volume Management System,企业卷管理系统)的卷; 5)其他任何的块设备。
DRBD工作原理
DRBD是一种块设备,可以被用于高可用(HA)之中.它类似于一个网络RAID-1功能.当你将数据写入本地 文件系统时,数据还将会被发送到网络中另一台主机上. 以相同的形式记录在一个文件系统中。 本地(主节点)与远程主机(备节点)的数据可以保证实时同步.当本地系统出现故障时,远程主机上还会 保留有一份相 同的数据,可以继续使用.在高可用(HA)中使用DRBD功能,可以代替使用一个共享盘阵.因为数据同时存在于本地主机和远程主机上,切换时,远程主机只要使用 它上面的那份备份数据,就可以继续进行服务了。
DRBD是如何工作的(工作机制)
(DRBD Primary)负责接收数据,把数据写到本地磁盘并发送给另一台主机(DRBD Secondary),另一个主机再将数据存到自己的磁盘中。 目前,DRBD每次只允许对一个节点进行读写访问,但这对于通常的故障切换高可用集群来说已经足够用了。 以后的版本将支持两个节点进行读写存取。 DRBD协议说明 1)数据一旦写入磁盘并发送到网络中就认为完成了写入操作。 2)收到接收确认就认为完成了写入操作。 3)收到写入确认就认为完成了写入操作。
DRBD与HA的关系
一个DRBD系统由两个节点构成,与HA集群类似,也有主节点和备用节点之分,在带有主要设备的节点上,应用程序和操作系统可以运行和访问DRBD设备(/dev/drbd*)。 在主节点写入的数据通过DRBD设备存储到主节点的磁盘设备中,同时,这个数据也会自动发送到备用节点对应的DRBD设备,最终写入备用节点的磁盘设备上,在备用节点上, DRBD只是将数据从DRBD设备写入到备用节点的磁盘中。现在大部分的高可用性集群都会使用共享存储,而DRBD也可以作为一个共享存储设备,使用DRBD不需要太多的硬件的投资。 因为它在TCP/IP网络中运行,所以,利用DRBD作为共享存储设备,要节约很多成本,因为价格要比专用的存储网络便宜很多;其性能与稳定性方面也不错
三、DRBD的特性(基本功能)
分布式复制块设备(DRBD技术)是一种基于软件的,无共享,复制的存储解决方案,在服务器之间的对块设备(硬盘,分区,逻辑卷等)进行镜像。 DRBD镜像数据的特性: 1)实时性:当某个应用程序完成对数据的修改时,复制功能立即发生 2)透明性:应用程序的数据存储在镜像块设备上是独立透明的,他们的数据在两个节点上都保存一份,因此,无论哪一台服务器宕机, 都不会影响应用程序读取数据的操作,所以说是透明的。 3)同步镜像和异步镜像:同步镜像表示当应用程序提交本地的写操作后,数据后会同步写到两个节点上去;异步镜像表示当应用程序提交写操作后, 只有当本地的节点上完成写操作后,另一个节点才可以完成写操作。
四、DRBD的用户空间管理工具
为了能够配置和管理drbd的资源,drbd提供了一些管理工具与内核模块进行通信: 1)drbdadm:高级的DRBD程序管理套件工具。它从配置文件/etc/drbd.conf中获取所有配置参数。drbdadm为drbdsetup和drbdmeta两个命令充当程序的前端应用, 执行drbdadm实际是执行的drbdsetup和drbdeta两个命令。 2)drbdsetup:drbdsetup可以让用户配置已经加载在内核中运行的DRBD模块,它是底层的DRBD程序管理套件工具。使用该命令时,所有的配置参数都需要直接在 命令行中定义,虽然命令很灵活,但是大大的降低了命令的简单易用性,因此很多的用户很少使用drbdsetup。 3)drbdmeta:drbdmeta允许用户创建、转储、还原和修改drbd的元数据结构。这个命令也是用户极少用到。
五、DRBD的模式
DRBD有2中模式,一种是DRBD的主从模式,另一种是DRBD的双主模式 1)DRBD的主从模式 这种模式下,其中一个节点作为主节点,另一个节点作为从节点。其中主节点可以执行读、写操作;从节点不可以挂载文件系统,因此,也不可以执行读写操作。 在这种模式下,资源在任何时间只能存储在主节点上。这种模式可用在任何的文件系统上(EXT3、EXT4、XFS等等)。默认这种模式下,一旦主节点发生故障,从 节点需要手工将资源进行转移,且主节点变成从节点和从节点变成主节点需要手动进行切换。不能自动进行转移,因此比较麻烦。 为了解决手动将资源和节点进行转移,可以将DRBD做成高可用集群的资源代理(RA),这样一旦其中的一个节点宕机,资源会自动转移到另一个节点,从而保证服 务的连续性。 2)DRBD的双主模式 这是DRBD8.0之后的新特性 在双主模式下,任何资源在任何特定的时间都存在两个主节点。这种模式需要一个共享的集群文件系统,利用分布式的锁机制进行管理,如GFS和OCFS2。 部署双主模式时,DRBD可以是负载均衡的集群,这就需要从两个并发的主节点中选取一个首选的访问数据。这种模式默认是禁用的,如果要是用的话必须在配置文 件中进行声明。
六、DRBD的同步协议
DRBD的复制功能就是将应用程序提交的数据一份保存在本地节点,一份复制传输保存在另一个节点上。但是DRBD需要对传输的数据进行确认以便保证另一个节点的 写操作完成,就需要用到DRBD的同步协议,DRBD同步协议有三种: 1)协议A:异步复制协议 一旦本地磁盘写入已经完成,数据包已在发送队列中,则写被认为是完成的。在一个节点发生故障时,可能发生数据丢失,因为被写入到远程节点上的数据可能仍在发送队列。 尽管,在故障转移节点上的数据是一致的,但没有及时更新。这通常是用于地理上分开的节点。
数据在本地完成写操作且数据已经发送到TCP/IP协议栈的队列中,则认为写操作完成。如果本地节点的写操作完成,此时本地节点发生故障,而数据还处在TCP/IP队列中, 则数据不会发送到对端节点上。因此,两个节点的数据将不会保持一致。这种协议虽然高效,但是并不能保证数据的可靠性。 2)协议B:内存同步(半同步)复制协议 一旦本地磁盘写入已完成且复制数据包达到了对等节点则认为写在主节点上被认为是完成的。数据丢失可能发生在参加的两个节点同时故障的情况下,因为在传输中的数据 可能不会被提交到磁盘
数据在本地完成写操作且数据已到达对端节点则认为写操作完成。如果两个节点同时发生故障,即使数据到达对端节点,这种方式同样也会导致在对端节点和本地 节点的数据不一致现象,也不具有可靠性。 3)协议C:同步复制协议 只有在本地和远程节点的磁盘已经确认了写操作完成,写才被认为完成。没有任何数据丢失,所以这是一个群集节点的流行模式,但I / O吞吐量依赖于网络带宽。 只有当本地节点的磁盘和对端节点的磁盘都完成了写操作,才认为写操作完成。这是集群流行的一种方式,应用也是最多的,这种方式虽然不高效,但是最可靠。 以上三种协议中,一般使用协议C,但选择C协议将影响流量,从而影响网络时延。为了数据可靠性,在生产环境使用时须慎重选项使用哪一种协议。
七、DRBD的资源
在DRBD中,资源是所有可复制移动存储设备的总称,它包括: 1)资源名称:资源名称可以是除了空白字符以外的任意ASCII码字符 2)DRBD设备:DRBD的虚拟块设备。在双方节点上,DRBD设备的设备文件命名方式;一般为/dev/drbdN,其主设备号147,N是次设备号 3)磁盘配置:DRBD内部应用需要本地数据副本,元数据。在双方节点上,为各自提供的存储设备。 4)网络配置:双方数据同步时所使用的网络属性;
八、DRBD的配置说明
----------全局配置项(global)---------- 基本上我们可以做的也就是配置usage-count是yes还是no了,usage-count参数其实只是为了让linbit公司收集目前drbd的使用情况。当drbd在安装和升级的时候会通过http 协议发送信息到linbit公司的服务器上面。 ----------公共配置项(common)---------- 这里的common,指的是drbd所管理的多个资源之间的common。配置项里面主要是配置drbd的所有resource可以设置为相同的参数项,比如protocol,syncer等等。 ----------DRBD设备---------- DRBD的虚拟块设备。它有一个主设备号为147的设备,默认的它的次要号码编从0开始。在一组主机上,drbd的设备的设备名称为/dev/drbdN,这个N通常和他的次设备号一致。 资源配置项(resource) resource 项中配置的是drbd所管理的所有资源,包括节点的ip信息,底层存储设备名称,设备大小,meta信息存放方式,drbd对外提供的设备名等等。每一个 resource中都需要配置在每一个节点的信息,而不是单独本节点的信息。并且资源名只能使用纯ascii码而且不能使用空白字符用于表示资源名称。实 际上,在drbd的整个集群中,每一个节点上面的drbd.conf文件需要是完全一致的。 另外,resource还有很多其他的内部配置项: 1)net:网络配置相关的内容,可以设置是否允许双主节点(allow-two-primaries)等。 2)startup:启动时候的相关设置,比如设置启动后谁作为primary(或者两者都是primary:become-primary-on both) 3)syncer: 同步相关的设置。可以设置“重新”同步(re-synchronization)速度(rate)设置,也可以设置是否在线校验节点之间的数据一致性 (verify-alg 检测算法有md5,sha1以及crc32等)。数据校验可能是一个比较重要的事情,在打开在线校验功能后,我们可以通过相关命令(drbdadm verify resource_name)来启动在线校验。在校验过程中,drbd会记录下节点之间不一致的block,但是不会阻塞任何行为,即使是在该不一致的 block上面的io请求。当不一致的block发生后,drbd就需要有re-synchronization动作,而syncer里面设置的rate 项,主要就是用于re-synchronization的时候,因为如果有大量不一致的数据的时候,我们不可能将所有带宽都分配给drbd做re- synchronization,这样会影响对外提提供服务。rate的设置和还需要考虑IO能力的影响。如果我们会有一个千兆网络出口,但是我们的磁盘 IO能力每秒只有50M,那么实际的处理能力就只有50M,一般来说,设置网络IO能力和磁盘IO能力中最小者的30%的带宽给re- synchronization是比较合适的(官方说明)。另外,drbd还提供了一个临时的rate更改命令,可以临时性的更改syncer的rate 值: 4)drbdsetup /dev/drbd0 syncer -r 100M 这样就临时的设置了re-synchronization的速度为100M。不过在re-synchronization结束之后,需要通过 drbdadm adjust resource_name 来让drbd按照配置中的rate来工作。 ----------角色---------- 在drbd构造的集群中,资源具有角色的概念,分别为primary和secondary。 所有设为primary的资源将不受限制进行读写操作。可以创建文件系统,可以使用裸设备,甚至直接io。所有设为secondary的设备中不能挂载,不能读写。 ----------数据同步协议---------- drbd有三种数据同步模式:同步,异步,半同步 1)异步:指的是当数据写到磁盘上,并且复制的数据已经被放到我们的tcp缓冲区并等待发送以后,就认为写入完成 2)半同步:指的是数据已经写到磁盘上,并且这些数据已经发送到对方内存缓冲区,对方的tcp已经收到数据,并宣布写入 3)同步:指的是主节点已写入,从节点磁盘也写入 drbd 的复制模型是靠protocol关键字来定义的: protocol A表示异步; protocol B表示半同步; protocol C表示同步, 默认为protocol C。在同步模式下只有主、从节点上两块磁盘同时损害才会导致数据丢失。在半同步模式下只有主节点宕机,同时从节点异常停电才会导致数据丢失。 注意:drbd的主不会监控从的状态所以有可能会造成数据重传 -----------------------------------metadata---------------------------------- DRBD将数据的各种信息块保存在一个专用的区域里,这些metadata包括了 1)DRBD设备的大小 2)产生的标识 3)活动日志 4)快速同步的位图 metadata的存储方式有内部和外部两种方式,使用哪种配置都是在资源配置中定义的 内部meta data 内部metadata存放在同一块硬盘或分区的最后的位置上 优点:metadata和数据是紧密联系在一起的,如果硬盘损坏,metadata同样就没有了,同样在恢复的时候,metadata也会一起被恢复回来 缺点:metadata和数据在同一块硬盘上,对于写操作的吞吐量会带来负面的影响,因为应用程序的写请求会触发metadata的更新,这样写操作就会造成两次额外的磁头读写移动。 外部meta data 外部的metadata存放在和数据磁盘分开的独立的块设备上 优点:对于一些写操作可以对一些潜在的行为提供一些改进 缺点:metadata和数据不是联系在一起的,所以如果数据盘出现故障,在更换新盘的时候就需要认为的干预操作来进行现有node对心硬盘的同步了 如果硬盘上有数据,并且硬盘或者分区不支持扩展,或者现有的文件系统不支持shrinking,那就必须使用外部metadata这种方式了。 可以通过下面的命令来计算metadata需要占用的扇区数 ---------------------------------------------split brain脑裂--------------------------------------------- split brain实际上是指在某种情况下,造成drbd的两个节点断开连接,都以primary的身份来运行。当drbd某primary节点连接对方节点准备 发送信息的时候如果发现对方 也是primary状态,那么会立刻自行断开连接,并认定当前已经发生split brain了,这时候他会在系统日志中记录以下信息: "Split-Brain detected,dropping connection!" 当发生split brain之后,如果查看连接状态,其中至少会有一个是StandAlone状态,另外一个可能也是StandAlone(如果是同时发现split brain状态),也有可能是 WFConnection的状态。 如果在配置文件中配置了自动解决split brain(好像linbit不推荐这样做),drbd会自行解决split brain问题,可通过如下策略进行配置。 1)Discarding modifications made on the “younger” primary。在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD会丢弃最后切换到主节点上的主机所修改的数据。 2)Discarding modifications made on the “older” primary. 在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD丢弃首先切换到主节点上的主机后所修改的数据。 3)Discarding modifications on the primary with fewer changes.在这种模式下,当网络重新建立连接并且发现了裂脑,DRBD会比较两台主机之间修改的数据量,并丢弃修 改数据量较少的主机上的所有数据。 4)Graceful recovery from split brain if one host has had no intermediate changes.在这种模式下,如果其中一个主机在脑裂期间并没有数据修改,DRBD会自动重新进 行数据同步,并宣布脑裂问题已解决。(这种情况几乎不可 能存在) 特别注意: 自动裂脑自动修复能不能被接受取决于个人应用。考虑 建立一个DRBD的例子库。在“丢弃修改比较少的主节点的修改”兴许对web应用好过数据库应用。与此相反,财务的数据库 则是对于任何修改的丢失都是不能 容忍的,这就需要不管在什么情况下都需要手工修复裂脑问题。因此需要在启用裂脑自动修复前考虑你的应用情况。 如果没有配置 split brain自动解决方案,我们可以手动解决。首先我们必须要确定哪一边应该作为解决问题后的primary,一旦确定好这一点,那么我们同时也就确定接受丢失 在split brain之后另外一个节点上面所做的所有数据变更了。当这些确定下来后,就可以通过以下操作来恢复了: 1)首先在确定要作为secondary的节点上面切换成secondary并放弃该资源的数据: drbdadm secondary resource_name drbdadm — –discard-my-data connect resource_name 2)在要作为primary的节点重新连接secondary(如果这个节点当前的连接状态为WFConnection的话,可以省略) drbdadm connect resource_name 当作完这些动作之后,从新的primary到secondary的re-synchnorisation会自动开始。
九、DRBD的配置文件说明
DRBD的主配置文件为/etc/drbd.conf;为了管理的便捷性,
目前通常会将配置文件分成多个部分,且都保存至/etc/drbd.d目录中,主配置文件中仅使用"include"指令将这些配置文件片断整合起来。通常,/etc/drbd.d目录中的配置文件
为global_common.conf和所有以.res结尾的文件。其中global_common.conf中主要定义global段和common段,而每一个.res的文件用于定义一个资源。
在配置文件中,global段仅能出现一次,且如果所有的配置信息都保存至同一个配置文件中而不分开为多个文件的话,global段必须位于配置文件的最开始处。目前global段中
可以定义的参数仅有minor-count, dialog-refresh, disable-ip-verification和usage-count。
common段则用于定义被每一个资源默认继承的参数,可以在资源定义中使用的参数都可以在common段中定义。实际应用中,common段并非必须,但建议将多个资源共享的参数定
义为common段中的参数以降低配置文件的复杂度。
resource段则用于定义DRBD资源,每个资源通常定义在一个单独的位于/etc/drbd.d目录中的以.res结尾的文件中。资源在定义时必须为其命名,名字可以由非空白的ASCII字符
组成。每一个资源段的定义中至少要包含两个host子段,以定义此资源关联至的节点,其它参数均可以从common段或DRBD的默认中进行继承而无须定义。
DRBD配置文件
[root@huanqiu ~]# cat /etc/drbd.d/global_common.conf
global {
usage-count yes; //是否参加DRBD使用者统计,默认是参加
# minor-count dialog-refresh disable-ip-verification //这里是global可以使用的参数
#minor-count:32 //从(设备)个数,取值范围1~255,默认值为32。该选项设定了允许定义的resource个数,当要定义的resource超过了此选项的设定时,需要重新载入DRBD内核模块。
#disable-ip-verification:no //是否禁用ip检查
}
common {
protocol C; //指定复制协议,复制协议共有三种,为协议A,B,C,默认协议为协议C
handlers { //该配置段用来定义一系列处理器,用来回应特定事件。
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
# pri-on-incon-degr "/usr/lib/DRBD/notify-pri-on-incon-degr.sh; /usr/lib/DRBD/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# pri-lost-after-sb "/usr/lib/DRBD/notify-pri-lost-after-sb.sh; /usr/lib/DRBD/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# local-io-error "/usr/lib/DRBD/notify-io-error.sh; /usr/lib/DRBD/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/DRBD/crm-fence-peer.sh";
# split-brain "/usr/lib/DRBD/notify-split-brain.sh root";
# out-of-sync "/usr/lib/DRBD/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/DRBD/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/DRBD/unsnapshot-resync-target-lvm.sh;
}
startup { //#DRBD同步时使用的验证方式和密码。该配置段用来更加精细地调节DRBD属性,它作用于配置节点在启动或重启时。常用选项有:
# wfc-timeout degr-wfc-timeout outdated-wfc-timeout wait-after-sb
wfc-timeout: //该选项设定一个时间值,单位是秒。在启用DRBD块时,初始化脚本DRBD会阻塞启动进程的运行,直到对等节点的出现。该选项就是用来限制这个等待时间的,默认为0,即不限制,永远等待。
degr-wfc-timeout: //该选项也设定一个时间值,单位为秒。也是用于限制等待时间,只是作用的情形不同:它作用于一个降级集群(即那些只剩下一个节点的集群)在重启时的等待时间。
outdated-wfc-timeout: //同上,也是用来设定等待时间,单位为秒。它用于设定等待过期节点的时间
}
disk {
# on-io-error fencing use-bmbv no-disk-barrier no-disk-flushes //这里是disk段内可以定义的参数
# no-disk-drain no-md-flushes max-bio-bvecs //这里是disk段内可以定义的参数
on-io-error: detach //选项:此选项设定了一个策略,如果底层设备向上层设备报告发生I/O错误,将按照该策略进行处理。有效的策略包括:
detach //发生I/O错误的节点将放弃底层设备,以diskless mode继续工作。在diskless mode下,只要还有网络连接,DRBD将从secondary node读写数据,而不需要failover(故障转移)。该策略会导致一定的损失,但好处也很明显,DRBD服务不会中断。官方推荐和默认策略。
pass_on //把I/O错误报告给上层设备。如果错误发生在primary节点,把它报告给文件系统,由上层设备处理这些错误(例如,它会导致文件系统以只读方式重新挂载),它可能会导致DRBD停止提供服务;如果发生在secondary节点,则忽略该错误(因为secondary节点没有上层设备可以报告)。该策略曾经是默认策略,但现在已被detach所取代。
call-local-io-error //调用预定义的本地local-io-error脚本进行处理。该策略需要在resource(或common)配置段的handlers部分,预定义一个相应的local-io-error命令调用。该策略完全由管理员通过local-io-error命令(或脚本)调用来控制如何处理I/O错误。
fencing: //该选项设定一个策略来避免split brain的状况。有效的策略包括:
dont-care: //默认策略。不采取任何隔离措施。
resource-only: //在此策略下,如果一个节点处于split brain状态,它将尝试隔离对端节点的磁盘。这个操作通过调用fence-peer处理器来实现。fence-peer处理器将通过其它通信路径到达对等节点,并在这个对等节点上调用DRBDadm outdate res命令
resource-and-stonith: //在此策略下,如果一个节点处于split brain状态,它将停止I/O操作,并调用fence-peer处理器。处理器通过其它通信路径到达对等节点,并在这个对等节点上调用DRBDadm outdate res命令。如果无法到达对等节点,它将向对等端发送关机命令。一旦问题解决,I/O操作将重新进行。如果处理器失败,你可以使用resume-io命令来重新开始I/O操作。
}
net { //该配置段用来精细地调节DRBD的属性,网络相关的属性。常用的选项有:
# sndbuf-size rcvbuf-size timeout connect-int ping-int ping-timeout max-buffers //这里是net段内可以定义的参数
# max-epoch-size ko-count allow-two-primaries cram-hmac-alg shared-secret //这里是net段内可以定义的参数
# after-sb-0pri after-sb-1pri after-sb-2pri data-integrity-alg no-tcp-cork //这里是net段内可以定义的参数
sndbuf-size: //该选项用来调节TCP send buffer的大小,DRBD 8.2.7以前的版本,默认值为0,意味着自动调节大小;新版本的DRBD的默认值为128KiB。高吞吐量的网络(例如专用的千兆网卡,或负载均衡中绑定的连接)中,增加到512K比较合适,或者可以更高,但是最好不要超过2M。
timeout: //该选项设定一个时间值,单位为0.1秒。如果搭档节点没有在此时间内发来应答包,那么就认为搭档节点已经死亡,因此将断开这次TCP/IP连接。默认值为60,即6秒。该选项的值必须小于connect-int和ping-int的值。
connect-int: //如果无法立即连接上远程DRBD设备,系统将断续尝试连接。该选项设定的就是两次尝试间隔时间。单位为秒,默认值为10秒。
ping-timeout: //该选项设定一个时间值,单位是0.1秒。如果对端节点没有在此时间内应答keep-alive包,它将被认为已经死亡。默认值是500ms。
max-buffers: //该选项设定一个由DRBD分配的最大请求数,单位是页面大小(PAGE_SIZE),大多数系统中,页面大小为4KB。这些buffer用来存储那些即将写入磁盘的数据。最小值为32(即128KB)。这个值大一点好。
max-epoch-size: //该选项设定了两次write barriers之间最大的数据块数。如果选项的值小于10,将影响系统性能。大一点好
ko-count: //该选项设定一个值,把该选项设定的值 乘以 timeout设定的值,得到一个数字N,如果secondary节点没有在此时间内完成单次写请求,它将从集群中被移除(即,primary node进入StandAlong模式)。取值范围0~200,默认值为0,即禁用该功能。
allow-two-primaries: //这个是DRBD8.0及以后版本才支持的新特性,允许一个集群中有两个primary node。该模式需要特定文件系统的支撑,目前只有OCFS2和GFS可以,传统的ext3、ext4、xfs等都不行!
cram-hmac-alg: //该选项可以用来指定HMAC算法来启用对端节点授权。DRBD强烈建议启用对端点授权机制。可以指定/proc/crypto文件中识别的任一算法。必须在此指定算法,以明确启用对端节点授权机制,实现数据加密传输。
shared-secret: //该选项用来设定在对端节点授权中使用的密码,最长64个字符。
data-integrity-alg: //该选项设定内核支持的一个算法,用于网络上的用户数据的一致性校验。通常的数据一致性校验,由TCP/IP头中所包含的16位校验和来进行,而该选项可以使用内核所支持的任一算法。该功能默认关闭。
}
syncer { //该配置段用来更加精细地调节服务的同步进程。常用选项有
# rate after al-extents use-rle cpu-mask verify-alg csums-alg
rate: //设置同步时的速率,默认为250KB。默认的单位是KB/sec,也允许使用K、M和G,如40M。注意:syncer中的速率是以bytes,而不是bits来设定的。配置文件中的这个选项设置的速率是永久性的,但可使用下列命令临时地改变rate的值:DRBDsetup /dev/DRBDN syncer -r 100M。如果想重新恢复成drbd.conf配置文件中设定的速率,执行如下命令: DRBDadm adjust resource
verify-alg: //该选项指定一个用于在线校验的算法,内核一般都会支持md5、sha1和crc32c校验算法。在线校验默认关闭,必须在此选项设定参数,以明确启用在线设备校验。DRBD支持在线设备校验,它以一种高效的方式对不同节点的数据进行一致性校验。在线校验会影响CPU负载和使用,但影响比较轻微。DRBD 8.2.5及以后版本支持此功能。一旦启用了该功能,你就可以使用下列命令进行一个在线校验: DRBDadm verify resource。该命令对指定的resource进行检验,如果检测到有数据块没有同步,它会标记这些块,并往内核日志中写入一条信息。这个过程不会影响正在使用该设备的程序。
如果检测到未同步的块,当检验结束后,你就可以如下命令重新同步它们:DRBDadm disconnect resource or DRBDadm connetc resource
}
}
common段是用来定义共享的资源参数,以减少资源定义的重复性。common段是非必须的。resource段一般为DRBD上每一个节点来定义其资源参数的。
资源配置文件详解
[root@huanqiu ~]# cat /etc/drbd.d/web.res
resource web { //web为资源名称
on ha1.xsl.com { //on后面为节点的名称,有几个节点就有几个on段,这里是定义节点ha1.xsl.com上的资源
device /dev/DRBD0; //定义DRBD虚拟块设备,这个设备事先不要格式化。
disk /dev/sda6; //定义存储磁盘为/dev/sda6,该分区创建完成之后就行了,不要进行格式化操作
address 192.168.108.199:7789; //定义DRBD监听的地址和端口,以便和对端进行通信
meta-disk internal; //该参数有2个选项:internal和externally,其中internal表示将元数据和数据存储在同一个磁盘上;而externally表示将元数据和数据分开存储,元数据被放在另一个磁盘上。
}
on ha2.xsl.com { //这里是定义节点ha2.xsl.com上的资源
device /dev/DRBD0;
disk /dev/sda6;
address 192.168.108.201:7789;
meta-disk internal;
}
}
----------------------------------------------------------------------------------------------------------------------------------------
十、Centos下DRBD的安装记录(主从模式)
DRBD(Distributed Replicated Block Device) 可以理解为它其实就是个网络RAID-1,两台服务器间就算某台因断电或者宕机也不会对数据有任何影响,
而真正的热切换可以通过Keepalived或Heartbeat方案解决,不需要人工干预。废话不多说了,下面记录下在centos下安装DRBD的操作记录
1)服务器信息(centos6.8)
192.168.1.151 主服务器 主机名:Primary
192.168.1.152 备服务器 主机名:Secondary
-------------------------------------------------------------------------------------------------------------------------
2)两台机器的防火墙要相互允许访问。最好是关闭selinux和iptables防火墙(两台机器同样操作)
[root@Primary ~]# setenforce 0 //临时性关闭;永久关闭的话,需要修改/etc/sysconfig/selinux的SELINUX为disabled
[root@Primary ~]# /etc/init.d/iptables stop
-------------------------------------------------------------------------------------------------------------------------
3)设置hosts文件(两台机器同样操作)
[root@Primary drbd-8.4.3]# vim /etc/hosts
......
192.168.1.151 Primary
192.168.1.152 Secondary
-------------------------------------------------------------------------------------------------------------------------
4)两台机器同步时间
[root@Primary ~]# yum install -y netpdate
[root@Primary ~]# ntpdate -u asia.pool.ntp.org
-------------------------------------------------------------------------------------------------------------------------
5)DRBD的安装配置(两台机器上同样操作)
这里采用yum方式安装
[root@Primary ~]# rpm -ivh http://www.elrepo.org/elrepo-release-6-6.el6.elrepo.noarch.rpm
[root@Primary ~]# yum -y install drbd83-utils kmod-drbd83
注意:上面是centos6的安装方式,如果是centos7,则安装方式如下:
# rpm -ivh http://www.elrepo.org/elrepo-release-7.0-2.el7.elrepo.noarch.rpm
# yum install -y drbd84-utils kmod-drbd84
加载模块:
[root@Primary ~]# modprobe drbd
查看模块是否已加上
[root@Primary ~]# lsmod |grep drbd
drbd 332493 0
-------------------------------------------------------------------------------------------------------------------------
6)DRBD配置(两台机器上同样操作)
[root@Primary ~]# cat /etc/drbd.conf
# You can find an example in /usr/share/doc/drbd.../drbd.conf.example
include "drbd.d/global_common.conf";
include "drbd.d/*.res";
[root@Primary ~]# cp /etc/drbd.d/global_common.conf /etc/drbd.d/global_common.conf.bak
[root@Primary ~]# vim /etc/drbd.d/global_common.conf
global {
usage-count yes;
# minor-count dialog-refresh disable-ip-verification
}
common {
protocol C;
handlers {
# These are EXAMPLE handlers only.
# They may have severe implications,
# like hard resetting the node under certain circumstances.
# Be careful when chosing your poison.
# pri-on-incon-degr "/usr/lib/drbd/notify-pri-on-incon-degr.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# pri-lost-after-sb "/usr/lib/drbd/notify-pri-lost-after-sb.sh; /usr/lib/drbd/notify-emergency-reboot.sh; echo b > /proc/sysrq-trigger ; reboot -f";
# local-io-error "/usr/lib/drbd/notify-io-error.sh; /usr/lib/drbd/notify-emergency-shutdown.sh; echo o > /proc/sysrq-trigger ; halt -f";
# fence-peer "/usr/lib/drbd/crm-fence-peer.sh";
# split-brain "/usr/lib/drbd/notify-split-brain.sh root";
# out-of-sync "/usr/lib/drbd/notify-out-of-sync.sh root";
# before-resync-target "/usr/lib/drbd/snapshot-resync-target-lvm.sh -p 15 -- -c 16k";
# after-resync-target /usr/lib/drbd/unsnapshot-resync-target-lvm.sh;
}
startup {
wfc-timeout 240;
degr-wfc-timeout 240;
outdated-wfc-timeout 240;
}
disk {
on-io-error detach;
}
net {
cram-hmac-alg md5;
shared-secret "testdrbd";
}
syncer {
rate 30M;
}
}
[root@Primary ~]# vim /etc/drbd.d/r0.res
resource r0 {
on Primary {
device /dev/drbd0; //这是Primary机器上的DRBD虚拟块设备,事先不要格式化
disk /dev/vdd1;
address 192.168.1.151:7898;
meta-disk internal;
}
on Secondary {
device /dev/drbd0; //这是Secondary机器上的DRBD虚拟块设备,事先不要格式化
disk /dev/vde1;
address 192.168.1.152:7898; //DRBD监听的地址和端口。端口可以自己定义
meta-disk internal;
}
}
-------------------------------------------------------------------------------------------------------------------------
7)在两台机器上添加DRBD磁盘
在Primary机器上添加一块10G的硬盘作为DRBD,分区为/dev/vdd1,不做格式化,并在本地系统创建/data目录,不做挂载操作。
[root@Primary ~]# fdisk -l
......
[root@Primary ~]# fdisk /dev/vdd
依次输入"n->p->1->1->回车->w" //分区创建后,再次使用"fdisk /dev/vdd",输入p,即可查看到创建的分区,比如/dev/vdd1
在Secondary机器上添加一块10G的硬盘作为DRBD,分区为/dev/vde1,不做格式化,并在本地系统创建/data目录,不做挂载操作。
[root@Secondary ~]# fdisk -l
......
[root@Secondary ~]# fdisk /dev/vde
依次输入"n->p->1->1->回车->w"
-------------------------------------------------------------------------------------------------------------------------
8)在两台机器上分别创建DRBD设备并激活r0资源(下面操作在两台机器上都要执行)
[root@Primary ~]# mknod /dev/drbd0 b 147 0
mknod: `/dev/drbd0': File exists
[root@Primary ~]# drbdadm create-md r0
Writing meta data...
initializing activity log
NOT initialized bitmap
New drbd meta data block successfully created.
再次输入该命令进行激活r0资源
[root@Primary ~]# drbdadm create-md r0
You want me to create a v08 style flexible-size internal meta data block.
There appears to be a v08 flexible-size internal meta data block
already in place on /dev/vdd1 at byte offset 10737340416
Do you really want to overwrite the existing v08 meta-data?
[need to type 'yes' to confirm] yes //这里输入"yes"
Writing meta data...
initializing activity log
NOT initialized bitmap
New drbd meta data block successfully created.
启动drbd服务(注意:需要主从共同启动方能生效)
[root@Primary ~]# /etc/init.d/drbd start
Starting DRBD resources: [ d(r0) s(r0) n(r0) ]....
[root@Primary ~]# ps -ef|grep drbd
root 5174 2 0 02:25 ? 00:00:00 [drbd0_worker]
root 5193 2 0 02:25 ? 00:00:00 [drbd0_receiver]
root 5207 2 0 02:25 ? 00:00:00 [drbd0_asender]
root 5211 18667 0 02:25 pts/0 00:00:00 grep --color drbd
查看状态(两台机器上都执行查看)
[root@Primary ~]# cat /proc/drbd
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
0: cs:Connected ro:Secondary/Secondary ds:Inconsistent/Inconsistent C r-----
ns:0 nr:0 dw:0 dr:0 al:0 bm:0 lo:0 pe:0 ua:0 ap:0 ep:1 wo:f oos:10485332
或者
[root@Primary ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary Inconsistent/Inconsistent C
由上面两台主机的DRBD状态查看结果里的ro:Secondary/Secondary表示两台主机的状态都是备机状态,ds是磁盘状态,显示的状态内容为“不一致”,这是因为DRBD无法判断哪一方为主机,
应以哪一方的磁盘数据作为标准。
-------------------------------------------------------------------------------------------------------------------------
9)接着将Primary主机配置为DRBD的主节点
[root@Primary ~]# drbdsetup /dev/drbd0 primary --force
分别查看主从DRBD状态:
[root@Primary ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
... sync'ed: 1.5% (10096/10236)M
0:r0 SyncSource Primary/Secondary UpToDate/Inconsistent C
[root@Secondary ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
... sync'ed: 12.5% (8960/10236)M
0:r0 SyncTarget Secondary/Primary Inconsistent/UpToDate C
ro在主从服务器上分别显示 Primary/Secondary和Secondary/Primary
ds显示UpToDate/UpToDate 表示主从配置成功
-------------------------------------------------------------------------------------------------------------------------
10)挂载DRBD (Primary主节点机器上操作)
从上面Primary主节点的DRBD状态上看到mounted和fstype参数为空,所以这步开始挂载DRBD到系统目录
先格式化/dev/drbd0
[root@Primary ~]# mkfs.ext4 /dev/drbd0
创建挂载目录,然后执行DRBD挂载
[root@Primary ~]# mkdir /data
[root@Primary ~]# mount /dev/drbd0 /data
[root@Primary ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
156G 36G 112G 25% /
tmpfs 2.9G 0 2.9G 0% /dev/shm
/dev/vda1 190M 98M 83M 55% /boot
/dev/drbd0 9.8G 23M 9.2G 1% /data
特别注意:
Secondary节点上不允许对DRBD设备进行任何操作,包括只读,所有的读写操作只能在Primary节点上进行。
只有当Primary节点挂掉时,Secondary节点才能提升为Primary节点
-------------------------------------------------------------------------------------------------------------------------
11)DRBD主备故障切换测试
模拟Primary节点发生故障,Secondary接管并提升为Primary
下面是在Primary主节点上操作记录:
[root@Primary ~]# cd /data
[root@Primary data]# touch wangshibo wangshibo1 wangshibo2 wangshibo3
[root@Primary data]# cd ../
[root@Primary /]# umount /data
[root@Primary /]# drbdsetup /dev/drbd0 secondary //将Primary主机设置为DRBD的备节点。在实际生产环境中,直接在Secondary主机上提权(即设置为主节点)即可。
[root@Primary /]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
0:r0 Connected Secondary/Secondary UpToDate/UpToDate C
注意:这里实际生产环境若Primary主节点宕机,在Secondary状态信息中ro的值会显示为Secondary/Unknown,只需要进行DRBD提权操作即可。
下面是在Secondary 备份节点上操作记录:
先进行提权操作,即将Secondary手动升级为DRBD的主节点
[root@Secondary ~]# drbdsetup /dev/drbd0 primary
[root@Secondary ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C
然后挂载DRBD
[root@Secondary ~]# mkdir /data
[root@Secondary ~]# mount /dev/drbd0 /data
[root@Secondary ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup00-LogVol00
156G 13G 135G 9% /
tmpfs 2.9G 0 2.9G 0% /dev/shm
/dev/vda1 190M 89M 92M 50% /boot
/dev/vdd 9.8G 23M 9.2G 1% /data2
/dev/drbd0 9.8G 23M 9.2G 1% /data
发现DRBD挂载目录下已经有了之前在远程Primary主机上写入的内容
[root@Secondary ~]# cd /data
[root@Secondary data]# ls
wangshibo wangshibo1 wangshibo2 wangshibo3
[root@Secondary ~]# /etc/init.d/drbd status
drbd driver loaded OK; device status:
version: 8.3.16 (api:88/proto:86-97)
GIT-hash: a798fa7e274428a357657fb52f0ecf40192c1985 build by phil@Build64R6, 2014-11-24 14:51:37
m:res cs ro ds p mounted fstype
0:r0 Connected Primary/Secondary UpToDate/UpToDate C /data ext4
在Secondary节点上继续写入数据
[root@Secondary data]# touch huanqiu huanqiu1 huanqiu2 huanqiu3
然后模拟Secondary节点故障,Primary节点再提权升级为DRBD主节点(操作同上,此处省略.......)
最后,使用命令fdisk -l查看本机磁盘情况,可以发现DRBD的磁盘/dev/drbd0
[root@Secondary ~]# fdisk -l
.......
.......
Disk /dev/drbd0: 10.7 GB, 10736979968 bytes
255 heads, 63 sectors/track, 1305 cylinders
Units = cylinders of 16065 * 512 = 8225280 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disk identifier: 0x00000000
到此,DRBD的主从环境的部署工作已经完成。不过上面是记录的是主备手动切换,至于保证DRBD主从结构的智能切换,实现高可用,还需里用到Keepalived或Heartbeat来实现了(会在DRBD主端挂掉的情况下,自动切换从端为主端并自动挂载/data分区)
---------------------------------------------------------------------------------------------------------------------------------- 最后说一下"Split-Brain"(脑裂)的情况: 假设把Primary主机的的eth0设备宕掉,然后直接在Secondary主机上进行提权升级为DRBD的主节点,并且mount挂载DRBD,这时会发现之前在Primary主机上写入的数据文件确实同步过来了。 接着再把Primary主机的eth0设备恢复,看看有没有自动恢复 主从关系。经过查看,发现DRBD检测出了Split-Brain的状况,也就是两个节点都处于standalone状态, 故障描述如下:Split-Brain detected,dropping connection! 这就是传说中的“脑裂”。 DRBD官方推荐的手动恢复方案: 1)Secondary主机上的操作 # drbdadm secondary r0 # drbdadm disconnect all # drbdadm --discard-my-data connect r0 //或者"drbdadm -- --discard-my-data connect r0" 2)Primary主机上的操作 # drbdadm disconnect all # drbdadm connect r0 # drbdsetup /dev/drbd0 primary ---------------------------------------------------------------------------------------------------------------------------------- 另外,还可以使用下面的命令查看DRBD状态: [root@Primary ~]# drbd-overview 0:r0 Connected Primary/Secondary UpToDate/UpToDate C r----- /data ext4 9.8G 23M 9.2G 1% [root@Secondary ~]# drbd-overview 0:r0 Connected Secondary/Primary UpToDate/UpToDate C r-----