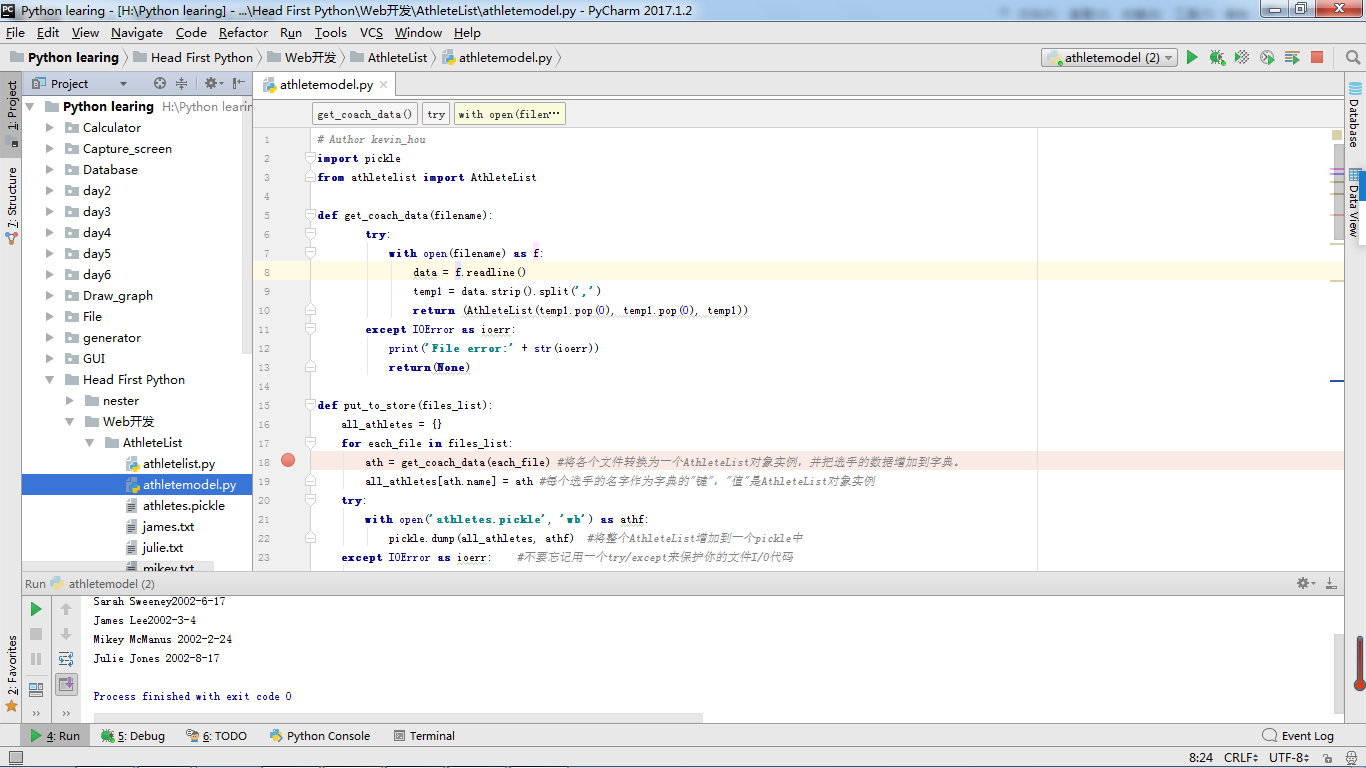
把文本文件中的数据转换为AthleteList对象实例,存储在一个字典中(按选手索引),然后保存为一个pickle文件。
# Author kevin_hou
import pickle
from athletelist import AthleteList
def get_coach_data(filename):
try:
with open(filename) as f:
data = f.readline()
temp1 = data.strip().split(',')
return (AthleteList(temp1.pop(0), temp1.pop(0), temp1))
except IOError as ioerr:
print('File error:' + str(ioerr))
return(None)
def put_to_store(files_list):
all_athletes = {}
for each_file in files_list:
ath = get_coach_data(each_file) #将各个文件转换为一个AthleteList对象实例,并把选手的数据增加到字典。
all_athletes[ath.name] = ath #每个选手的名字作为字典的"键","值"是AthleteList对象实例
try:
with open('athletes.pickle', 'wb') as athf:
pickle.dump(all_athletes, athf) #将整个AthleteList增加到一个pickle中
except IOError as ioerr: #不要忘记用一个try/except来保护你的文件I/O代码
print('File error (put_and_store):' + str(ioerr))
return (all_athletes)
def get_from_store():
all_athletes = {}
try:
with open('athletes.pickle', 'rb') as athf:
all_athletes = pickle.load(athf) #只需将整个pickle读入字典
except IOError as ioerr:
print('File error(get_from_store):' + str(ioerr))
return (all_athletes)
print(dir())
#['AthleteList', '__annotations__', '__builtins__', '__cached__',
# '__doc__', '__file__', '__loader__', '__name__', '__package__', '__spec__',
# 'get_coach_data', 'get_from_store', 'pickle', 'put_to_store']
the_files = ['sarah.txt', 'james.txt', 'mikey.txt', 'julie.txt']
data = put_to_store(the_files)
print(data)
#{'Sarah Sweeney': ['2.58', '2:39', '2-25', '2-25', '2:54', '2.18', '2:55', '2:55'],
# 'James Lee': ['3:21', '2:34', '2.45', '3.01', '2:01', '2:01', '3:10', '2:22'],
# 'Mikey': ['3.01', '3:01', '3.02', '3:02', '3.02', '3:22', '2.49', '2:38'],
# 'Julie Jones': ['2.11', '2:11', '2:23', '3:10', '2:23', '3:10', '3:21', '3-21']}
for each_athlete in data:
print(data[each_athlete].name + '' + data[each_athlete].dob)
# Sarah Sweeney2002-6-17
# James Lee2002-3-4
# Mikey McManus 2002-2-24
# Julie Jones 2002-8-17