Job
容器按照持续运行的时间可分为两类:服务类容器和工作类容器。
服务类容器通常持续提供服务,需要一直运行,比如 http server,daemon 等。工作类容器则是一次性任务,比如批处理程序,完成后容器就退出。
Kubernetes 的 Deployment、ReplicaSet 和 DaemonSet 都用于管理服务类容器;对于工作类容器,我们用 Job。
第一步:
先看一个简单的 Job 配置文件 myjob.yml:
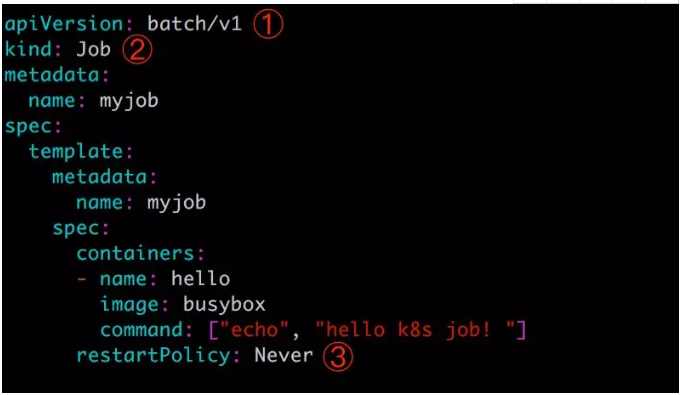
① batch/v1 是当前 Job 的 apiVersion。
② 指明当前资源的类型为 Job。
③ restartPolicy 指定什么情况下需要重启容器。对于 Job,只能设置为 Never 或者 OnFailure。对于其他 controller(比如 Deployment)可以设置为 Always 。
第二步:通过 kubectl apply -f myjob.yml 启动 Job。
[root@ken ~]# kubectl apply -f myjob.yml
job.batch/myjob created
第三步:查看job的状态
[root@ken ~]# kubectl get job NAME COMPLETIONS DURATION AGE myjob 1/1 4s 40s
第四步:查看pod的状态
[root@ken ~]# kubectl get pod NAME READY STATUS RESTARTS AGE myjob-8hczg 0/1 Completed 0 83s
显示completed已经完成
第五步:查看pod的标准输出
[root@ken ~]# kubectl logs myjob-8hczg
hello k8s job!
job失败的情况
讨论了job执行成功的情况,如果失败了会怎么样呢?
第一步:修改 myjob.yml,故意引入一个错误:
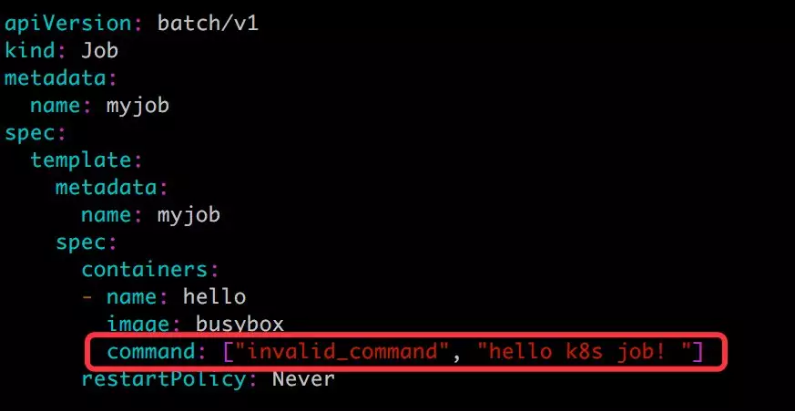
第二步:删除之前的job
[root@ken ~]# kubectl delete -f myjob.yml job.batch "myjob" deleted [root@ken ~]# kubectl get job No resources found.
第三步:运行新的job并查看状态
[root@ken ~]# kubectl apply -f myjob.yml job.batch/myjob created [root@ken ~]# kubectl get job NAME COMPLETIONS DURATION AGE myjob 0/1 6s 6s
可以发现完成为0
第四步:查看pod状态
[root@ken ~]# kubectl get pod NAME READY STATUS RESTARTS AGE myjob-hc6ld 0/1 ContainerCannotRun 0 64s myjob-hfblk 0/1 ContainerCannotRun 0 60s myjob-t9f6v 0/1 ContainerCreating 0 11s myjob-v2g7s 0/1 ContainerCannotRun 0 31s
可以看到有多个 Pod,状态均不正常。kubectl describe pod 查看某个 Pod 的启动日志:
第五步:查看pod的启动日志
[root@ken ~]# kubectl describe pod myjob-hc6ld ... node.kubernetes.io/unreachable:NoExecute for 300s Events: Type Reason Age From Message ---- ------ ---- ---- ------- Normal Scheduled 2m21s default-scheduler Successfully assigned default/myjob-hc6ld to host1 Normal Pulling 2m19s kubelet, host1 pulling image "busybox" Normal Pulled 2m18s kubelet, host1 Successfully pulled image "busybox" Normal Created 2m18s kubelet, host1 Created container Warning Failed 2m17s kubelet, host1 Error: failed to start container "hello": Error response from daemon: OCI runtime create failed: container_linux.go:348: starting container process caused "exec: "invlain_commadn": executable file not found in $PATH": unknown
日志显示没有可执行程序,符合我们的预期。
下面解释一个现象:为什么 kubectl get pod 会看到这么多个失败的 Pod?
原因是:当第一个 Pod 启动时,容器失败退出,根据 restartPolicy: Never,此失败容器不会被重启,但 Job DESIRED 的 Pod 是 1,目前 SUCCESSFUL 为 0,不满足,所以 Job controller 会启动新的 Pod,直到 SUCCESSFUL 为 1。对于我们这个例子,SUCCESSFUL 永远也到不了 1,所以 Job controller 会一直创建新的 Pod。为了终止这个行为,只能删除 Job。
[root@ken ~]# kubectl delete -f myjob.yml job.batch "myjob" deleted [root@ken ~]# kubectl get pod NAME READY STATUS RESTARTS AGE
如果将 restartPolicy 设置为 OnFailure 会怎么样?下面我们实践一下,修改 myjob.yml 后重新启动。
[root@ken ~]# kubectl apply -f myjob.yml job.batch/myjob created [root@ken ~]# kubectl get job NAME COMPLETIONS DURATION AGE
完成依然为0
再来查看一下pod的状态
[root@ken ~]# kubectl get pod NAME READY STATUS RESTARTS AGE myjob-5tbxw 0/1 CrashLoopBackOff 2 67s
这里只有一个 Pod,不过 RESTARTS 为 3,而且不断增加,说明 OnFailure 生效,容器失败后会自动重启。
定时执行job
Linux 中有 cron 程序定时执行任务,Kubernetes 的 CronJob 提供了类似的功能,可以定时执行 Job。
第一步:CronJob 配置文件示例如下:
[root@ken ~]# cat myjob1.yml apiVersion: batch/v1beta1 kind: CronJob metadata: name: hello spec: schedule: "*/1 * * * *" jobTemplate: spec: template: spec: containers: - name: hello image: busybox command: ["echo","hello k8s job!"] restartPolicy: OnFailure
① batch/v1beta1 是当前 CronJob 的 apiVersion。
② 指明当前资源的类型为 CronJob。
③ schedule 指定什么时候运行 Job,其格式与 Linux cron 一致。这里 */1 * * * * 的含义是每一分钟启动一次。
④ jobTemplate 定义 Job 的模板,格式与前面 Job 一致。
第二步:接下来通过 kubectl apply 创建 CronJob。
[root@ken ~]# kubectl apply -f myjob1.yml
cronjob.batch/hello created
第三步:查看crontab的状态
[root@ken ~]# kubectl get cronjob NAME SCHEDULE SUSPEND ACTIVE LAST SCHEDULE AGE hello */1 * * * * False 1 22s 3m12s
第四步:等待几分钟查看jobs的执行情况
[root@ken ~]# kubectl get job NAME COMPLETIONS DURATION AGE hello-1548766140 1/1 5s 2m24s hello-1548766200 1/1 18s 83s hello-1548766260 1/1 4s 23s
可以看到每隔一分钟就会启动一个 Job。
过段时间查看pod
第五步:执行 kubectl logs 可查看某个 Job 的运行日志:
[root@ken ~]# kubectl logs hello-1548766260-6s8lp hello k8s job!