https://www.usenix.org/legacy/events/vee05/full_papers/p111-kotzmann.pdf
https://dl.acm.org/doi/10.1145/320385.320386
论文的简版,主要是重要的摘要,和一些个人的观点,酌情采纳⚠️。
连接图符号定义
首先给一些连接图里面的符号的定义,以及简单的连接图长啥样。
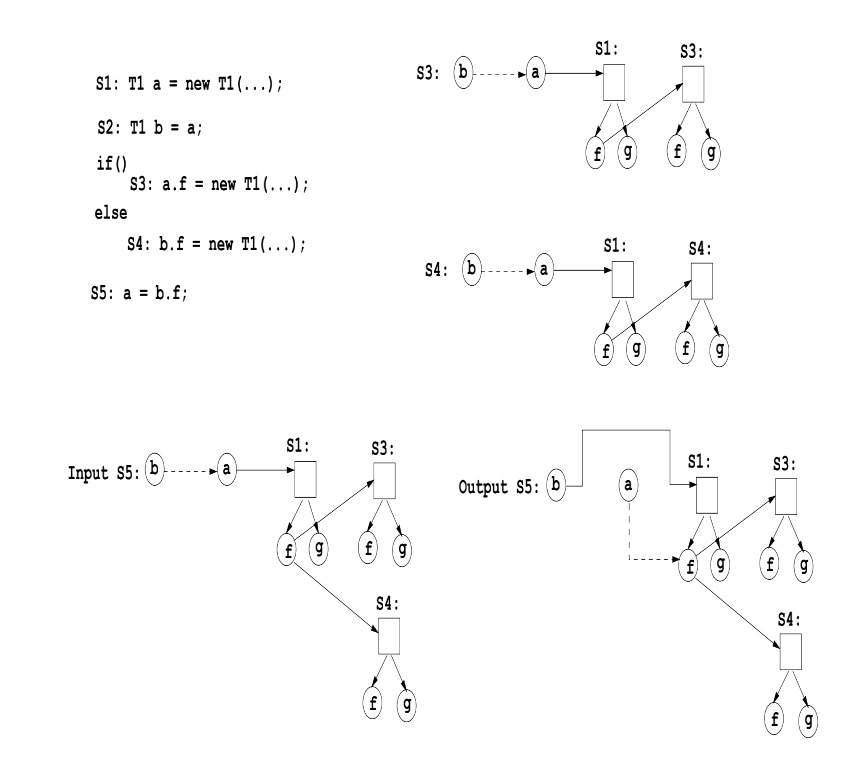
-
a=new T1,就表示为a--PointsTo-->T1
-
b=a表示为b-->DeferredTo-->b
-
a.f=q 可以表示为PointsTo(a)--FieldTo-->f,f--DeferredTo-->q
-
a=b.f可以表示为PointsTo(b)--FieldTo-->f,a--DeferredTo-->f
连接图
接下来正式描述用来建模程序的连接图CG
源码:


CG:
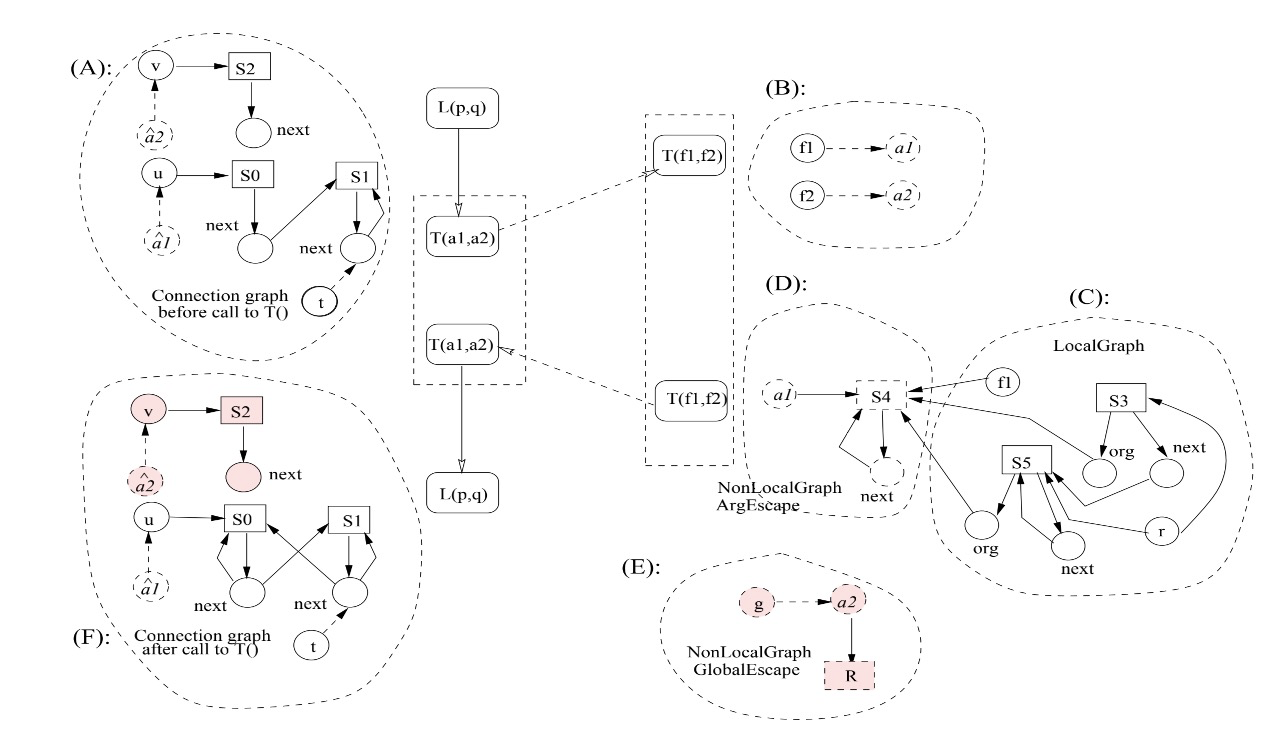
论文主要围绕这幅图展开。
1. 方法入口的CG
假设形参是fi,实参是ai,方法入口就像是有fi = ai这样的代码。因为Java是传值所以fi可以视作方法局部变量。我们为ai创建一个phantom node(见图B),从fi到ai用defered边连接。然后初始化ai和fi逃逸状态,即:EscapeState[fi]=NoEscape ,EscapeState[ai]=ArgEscape
2. 方法结束的CG
执行可达性分析。从GlobalEscape和ArgEscape状态的节点出发,可达的节点构成NonLocalGraph,可以逃逸。从NoEscape出发,可达的节点构成LocalGraph,不可逃逸。其中最初标记为GlobalEscape的节点有static fields和Runnable对象,最初被标记为ArgEscape的节点有哪些表示实参的phantom nodes,比如图B的a1和a2。
3. 调用前的CG
用ai作为实参,ai表示形参。假如有个调用u1.foo(u2,u3,...un),我们把它写成a1=u1;a2=u2;...;foo(a1,a2,...)。换句话说,创建了一堆ai的phantom node,它们和实参以DeferredTo连接。咋一看可能没必要,实际上这是后面更新caller cg必备的。
4. 调用后的CG
此时我们需要根据callee分析的结果来更新caller的cg,包括节点的更新和边的更新。更新节点算法如下。

caller的ai^对应callee的ai,我们从这个出发,寻找callee节点对应的caller节点,如果找不到就创建一个NoEscape的caller节点和它的field节点,然后把这些field节点再update一次。
例子参见图F,我们从a1和a1出发,将它们作为最初的“field”节点。然后将a1指向的S4映射到a1指向的S0.接下面有个环会导致将S1映射为S4。同时更新S1和S4的next节点(field节点),互相指向。
EA具体实现
C2的ea概念上遵从论文,高度一致,但是实现上和论文还是有很大区别的。它属于flow-insensitive的分析,代码主要位于ConnectionGraph::compute_escape。可以分为五个部分:
- 创建CG的点和边
- 完成CG构造
- 调整节点的标量替换状态
- 基于EA分析的结果优化IR
- 精确化内存节点的类型范围
最核心的过程是前两步,后面三步是利用前两步建模的CG来做优化。说白了,就是用CG建模Ideal graph,让每个IR中重要的node(EA关心的那些操作,比如局部变量创建)都能在CG中有对应的PointsTo。
1. 创建CG的点和边
bool ConnectionGraph::compute_escape() {
....
// 1. 产生CG,该图由PointsTo节点组成
ideal_nodes.map(C->live_nodes(), NULL); // preallocate space
// =====从Root节点出发,遍历整个IR
if (C->root() != NULL) {
ideal_nodes.push(C->root());
}
ptnodes_worklist.append(phantom_obj);
java_objects_worklist.append(phantom_obj);
for( uint next = 0; next < ideal_nodes.size(); ++next ) {
Node* n = ideal_nodes.at(next);
// =====每次拿到IR中的节点n,就创建n对应的PointsToNode,然后把它加到CG。
// =====CG的所有节点都是PointsToNode(及其子类)
add_node_to_connection_graph(n, &delayed_worklist);
...
// =====补充之前不完整的CG
while(delayed_worklist.size() > 0) {
Node* n = delayed_worklist.pop();
add_final_edges(n);
}
...
}
c2从Root节点出发遍历整个IR图,遇到每个节点都先调用add_node_to_connection_graph初步构造出CG的“草图”。为什么说是草图呢?因为add_node_to_connection_graph这里创建的PointsToNode可能是不完整的,比如对于CMove节点,它只会创建CMove节点本身对应的PointsToNode,但是CMove输入节点到CMove的边不会创建,因为它的输入节点对应的PointsToNode可能还没有构建,需要放到delayed_worklist。
在add_final_edges的时候,会从delayed_workerlist里面拿节点,这时候CMove和CMove输入对应的PointsToNode都创建完毕了,所以这个时候可以创建这些PointsToNode的边,即CG中的边,这一步完成之后“草图”就变成了可用的图了。
除了CMove之外,很多节点都需要add_node_to_connection_graph和add_final_edges两步处理。这里讨论一下最重要的Call节点。在add_node_to_connection_graph第一次处理Call节点的时候,它检查:
- Call是否返回新创建的未逃逸的对象,如果是,则创建一个表示Java对象的PointsNode(即JavaObjectNode),然后将它标记为NoEscape
- Call是否返回参数,如果是,则将Call节点映射为一个PointsNode,然后标记为ArgEscape
- 否则,将Call节点映射为一个phantom_obj(即未知对象)
换句话说,视情况为Call节点创建对应的PointsNode,然后设置逃逸状态(ConnectionGraph::add_call_node)。
考虑到Call节点的参数们对应的PointsToNode可能还没有创建,所以add_node_to_connection_graph这一步对CallNode的处理是不完整的,需要add_final_edges来补充一下,它遍历Call节点的参数,根据BCEscapeAnalyzer的结果调整参数逃逸状态(ConnectionGraph::process_call_arguments)
2.完成CG构造
这一步位于complete_connection_graph。它会从逃逸状态(GlobalEscape和ArgEscape)的节点出发,标记这些节点的field节点,将它们状态也置为逃逸(我理解这一步应该对应论文里面的方法结束时的可达性分析)。除此之外,这一步还会找到那些没有逃逸的对象且其字段被初始化为null的field节点。
到这里,CG已经建模完成了,是不是感觉漏了什么?论文中大段讨论的更新caller CG的过程好像没看到?是的,C2对与callee并不是再上一次逃逸分析,它使用之前提到的BCEscapeAnalyzer基于字节码(因为caller知道callee的字节码)做了一个保守的分析,来判断参数是ArgEscape了,还是GlobalEscape了,又或者没有逃逸。这个分析器不会产生callee CG,当然也就不需要更新caller CG了。
3. 调整节点的标量替换状态
4. 基于EA分析的结果优化IR
这一步很简单,代码可以全部贴出来
void ConnectionGraph::optimize_ideal_graph(GrowableArray<Node*>& ptr_cmp_worklist,
GrowableArray<Node*>& storestore_worklist) {
Compile* C = _compile;
PhaseIterGVN* igvn = _igvn;
if (EliminateLocks) {
// Mark locks before changing ideal graph.
int cnt = C->macro_count();
for (int i = 0; i < cnt; i++) {
Node *n = C->macro_node(i);
if (n->is_AbstractLock()) { // Lock and Unlock nodes
AbstractLockNode* alock = n->as_AbstractLock();
if (!alock->is_non_esc_obj()) {
if (not_global_escape(alock->obj_node())) {
assert(!alock->is_eliminated() || alock->is_coarsened(), "sanity");
// The lock could be marked eliminated by lock coarsening
// code during first IGVN before EA. Replace coarsened flag
// to eliminate all associated locks/unlocks.
alock->set_non_esc_obj();
}
}
}
}
}
if (OptimizePtrCompare) {
for (int i = 0; i < ptr_cmp_worklist.length(); i++) {
Node *n = ptr_cmp_worklist.at(i);
const TypeInt* tcmp = optimize_ptr_compare(n);
if (tcmp->singleton()) {
Node* cmp = igvn->makecon(tcmp);
igvn->replace_node(n, cmp);
}
}
}
// For MemBarStoreStore nodes added in library_call.cpp, check
// escape status of associated AllocateNode and optimize out
// MemBarStoreStore node if the allocated object never escapes.
for (int i = 0; i < storestore_worklist.length(); i++) {
Node* storestore = storestore_worklist.at(i);
assert(storestore->is_MemBarStoreStore(), "");
Node* alloc = storestore->in(MemBarNode::Precedent)->in(0);
if (alloc->is_Allocate() && not_global_escape(alloc)) {
MemBarNode* mb = MemBarNode::make(C, Op_MemBarCPUOrder, Compile::AliasIdxBot);
mb->init_req(TypeFunc::Memory, storestore->in(TypeFunc::Memory));
mb->init_req(TypeFunc::Control, storestore->in(TypeFunc::Control));
igvn->register_new_node_with_optimizer(mb);
igvn->replace_node(storestore, mb);
}
}
}
做了三个优化
- 如果有lock,unlock节点,且它们没有GlobalEscape,那么锁可以消除。
- 优化指针比较为常量
- 如果有StoreStore的membar,但是它们关联的分配操作没有GlobalEscape,那么这些分配没有逃逸出线程,可以将StoreStore优化为MemBarCPUOrder
5. 精确化内存节点的类型范围
to write