原文compilers-for-free,主要用Ruby来描述,意译为主,文章太长了,typo/翻译错误等请留言,谢谢。
最后,对编译器解释器感兴趣的可以看看
目录
- 介绍
- 执行
- 解释
- 编译
- 部分求值
- 应用
- 二村映射
- 总结
介绍
我喜欢编程,尤其喜欢元编程。当Ruby开发者讨论元编程时他们说的通常是“让程序来写程序”,因为Ruby有很多这方面的特性,如 BasicObject#instance_eval, Module#define_method还有BasicObject#method_missing,这让我们写的程序能在运行时新增功能。
但是我发现元编程还有另一种更有趣的方面:操纵程序表示的程序(programs that manipulate representations of programs)。这些程序将一些程序的源码作为输入,然后在其上做一些事情,如分析,求值,翻译或者转换。
这是一个由解释器、编译器和静态分析器组成的世界,我觉得它很迷人,我们能编写的最纯粹、最自指(self-referential)的软件。
我会给你展示这个世界,并让你对程序有不同的看法。我不会说一些很复杂的技术,我只会说很酷的技术,告诉你操纵其他程序的程序是有趣的,并希望能激励你继续探索这方面的知识。
执行
我们从一个最熟悉的东西开始:程序执行。
假设我们有一个要运行的程序,以及一台运行它的机器。运行程序的第一步是把程序放到机器里面。然后我们输入一些数据作为程序的——命令行参数,或者配置文件,或者标准输入,又或者其它的——总之我们把这些输入放到了机器里面。
原则上,程序在机器上执行,读取输入,并产生一些输出:

但实际上,上图只可能发生在那些硬件能直接执行该程序的情况。对于一个裸机,这意味着除非你的程序是用机器代码写的,否则就不可能像上图那样。(如果程序使用一些高级语言写的,那么机器要想理解这门语言,必须套一个语言虚拟机,比如Java字节码之于JVM)。我们需要一个解释器或者编译器。
解释
解释器的大致工作机制如下:
- 它读取程序源码,接着
- 它解析程序源码,构造出抽象语法树(Abstract syntax tree,AST),最终
- 解释器遍历AST并求值
我们试着构造一门玩具语言SIMPLE的解释器,然后逐步讨论。SIMPLE非常的直观,类似于Ruby,但也不完全一样。下面是一个SIMPLE的示例代码:
a = 19 + 23
x = 2; y = x * 3
if (a < 10) { a = 0; b = 0 } else { b = 10 }
x = 1; while (x < 5) { x = x * 3 }
和Ruby不同的是,SIMPLE明确区分表达式和语句。表达式求值得到一个值。比如表达式19 + 23求值得到42,表达式x * 3将当前x的值乘以3。语句求值不产生任何值,但是可能有副作用(side effect)导致当前的值被修改。对赋值语句a = 19 + 23求值会将a的值修改为42。
除了赋值外,SIMPLE还有一些语句:序列语句(挨个求值,逗号隔开),条件语句(if (…) { … } else { … }),循环语句(while (…) { … })。这些语句不会直接影响变量的值,但是它们的代码块中可能包含赋值语句,这些赋值语句就会影响变量的值。
有一个名为Treetop的Ruby库,可以很容易的构造解析器,所以我们会使用Treetop来构造SIMPLE的解析器。(这里不讨论Treetop的细节,如果想了解更多请参见Treetop documentation)
在使用Treetop之前,我们还得写一个语法文件,就像下面:
grammar Simple
rule statement
sequence
end
rule sequence
first:sequenced_statement '; ' second:sequence
/
sequenced_statement
end
rule sequenced_statement
while / assign / if
end
rule while
'while (' condition:expression ') { ' body:statement ' }'
end
rule assign
name:[a-z]+ ' = ' expression
end
rule if
'if (' condition:expression ') { ' consequence:statement
' } else { ' alternative:statement ' }'
end
rule expression
less_than
end
rule less_than
left:add ' < ' right:less_than
/
add
end
rule add
left:multiply ' + ' right:add
/
multiply
end
rule multiply
left:term ' * ' right:multiply
/
term
end
rule term
number / boolean / variable
end
rule number
[0-9]+
end
rule boolean
('true' / 'false') ![a-z]
end
rule variable
[a-z]+
end
end
这个语法文件包含一些rules,它们很好的显示了表达式和语句有哪些。sequence rule是两个用逗号隔开的语句,while rule表示一个由关键字while开头,后面跟一个圆括号包裹的条件表达式,再后面跟一个花括号包裹的代码体。assignment rule表示变量名跟一个等号,再跟一个表达式。然后number,boolean和variable这些rules分别表示数字字面值,布尔字面值和变量名字。
当我们写完语法文件,就可以使用Treetop读取它,Treetop会生成一个解析器。解析器的代码用Ruby的class组织,所以我们可以实例化解析器,然后给它一个表示字符串让它解析。
假设语法文件名字是simple.treetop,然后我们用IRB演示一下:
>> Treetop.load('simple.treetop')
=> SimpleParser
>> SimpleParser.new.parse('x = 2; y = x * 3')
=> SyntaxNode+Sequence1+Sequence0 offset=0, "x = 2; y = x * 3" (first,second):
SyntaxNode+Assign1+Assign0 offset=0, "x = 2" (name,expression):
SyntaxNode offset=0, "x":
SyntaxNode offset=0, "x"
SyntaxNode offset=1, " = "
SyntaxNode+Number0 offset=4, "2":
SyntaxNode offset=4, "2"
SyntaxNode offset=5, "; "
SyntaxNode+Assign1+Assign0 offset=7, "y = x * 3" (name,expression):
SyntaxNode offset=7, "y":
SyntaxNode offset=7, "y"
SyntaxNode offset=8, " = "
SyntaxNode+Multiply1+Multiply0 offset=11, "x * 3" (left,right):
SyntaxNode+Variable0 offset=11, "x":
SyntaxNode offset=11, "x"
SyntaxNode offset=12, " * "
SyntaxNode+Number0 offset=15, "3":
SyntaxNode offset=15, "3"
解析器产生了一个名为具体语法树(concrete syntax tree)的数据结构,也叫解析树(parse tree),它包含了一大堆细节,但是实际上我们不需要这么多细节,我们更希望一个抽象语法树(abstract syntax tree),它包含更少的细节,更具表现力。
为了产出抽象语法树,我们需要声明一些类,它们是最后生成的抽象语法树的节点。这些通过Struct很容易完成:
Number = Struct.new :value
Boolean = Struct.new :value
Variable = Struct.new :name
Add = Struct.new :left, :right
Multiply = Struct.new :left, :right
LessThan = Struct.new :left, :right
Assign = Struct.new :name, :expression
If = Struct.new :condition, :consequence, :alternative
Sequence = Struct.new :first, :second
While = Struct.new :condition, :body
现在,我们定义了一堆用来表示表达式和语句的node类:简单的表达式如Number,Boolean只有包含一个value,二元表达式如Add,Multiply有left和right两个表达式。Assign语句的name表示变量名,还有一个expression表示赋值语句的右侧,等等等等。
Treetop还允许这些node类携带语义动作,这个语义动作是一个Ruby方法。我们可以用这个特性将具体语法树的节点转换为抽象语法树的节点,让我们把这个表示语义动作的方面命名为#to_ast。
下面展示了如何定义number,boolean和变量的语义动作方法:
rule number
[0-9]+ {
def to_ast
Number.new(text_value.to_i)
end
}
end
rule boolean
('true' / 'false') ![a-z] {
def to_ast
Boolean.new(text_value == 'true')
end
}
end
rule variable
[a-z]+ {
def to_ast
Variable.new(text_value.to_sym)
end
}
end
当Treetop应用number这条rule时,它继续调用后面紧跟着的to_ast方法,这个方法把整数字面值转换为一个整数字符串(使用String#to_i),然后用Number包裹创造处integer常量。#to_ast的实现在boolean和variable的rule中与之类似,它们最终都构造出合适的AST节点。
下面是一些二元表达式的#to_ast实现:
rule less_than
left:add ' < ' right:less_than {
def to_ast
LessThan.new(left.to_ast, right.to_ast)
end
}
/
add
end
rule add
left:multiply ' + ' right:add {
def to_ast
Add.new(left.to_ast, right.to_ast)
end
}
/
multiply
end
rule multiply
left:term ' * ' right:multiply {
def to_ast
Multiply.new(left.to_ast, right.to_ast)
end
}
/
term
end
在上面三个例子中,#to_ast递归地调用具体语法树的左右子表达式的#to_ast,将它们转换为AST,然后把它们组合起来,放到一个类中。
语句也类似
rule sequence
first:sequenced_statement '; ' second:sequence {
def to_ast
Sequence.new(first.to_ast, second.to_ast)
end
}
/
sequenced_statement
end
rule while
'while (' condition:expression ') { ' body:statement ' }' {
def to_ast
While.new(condition.to_ast, body.to_ast)
end
}
end
rule assign
name:[a-z]+ ' = ' expression {
def to_ast
Assign.new(name.text_value.to_sym, expression.to_ast)
end
}
end
rule if
'if (' condition:expression ') { ' consequence:statement
' } else { ' alternative:statement ' }' {
def to_ast
If.new(condition.to_ast, consequence.to_ast, alternative.to_ast)
end
}
end
一样的,#to_ast递归调用子表达式或者子语句的#to_ast将它们转换为AST,然后组合成一个正确的AST类。
当所有的#to_ast都定义完成后,我们对具体语法树的根节点调用#to_ast,递归地将整个树转换为AST:
>> SimpleParser.new.parse('x = 2; y = x * 3').to_ast
=> #<struct Sequence
first=#<struct Assign
name=:x,
expression=#<struct Number value=2>
>,
second=#<struct Assign
name=:y,
expression=#<struct Multiply
left=#<struct Variable name=:x>,
right=#<struct Number value=3>
>
>
>
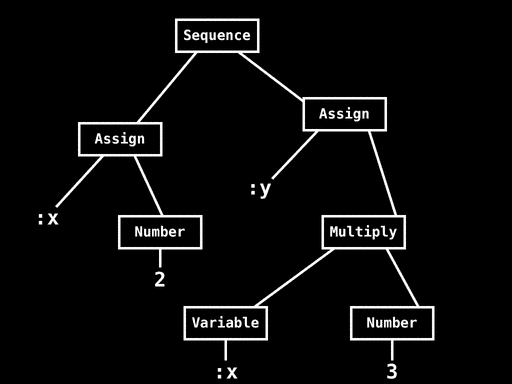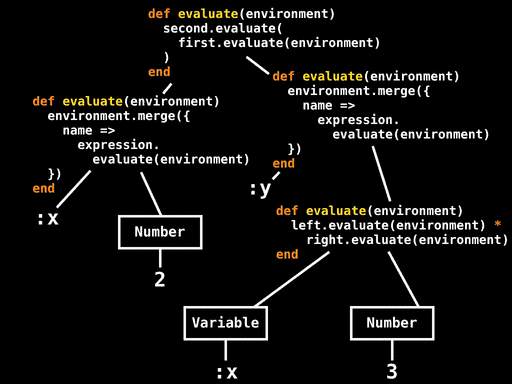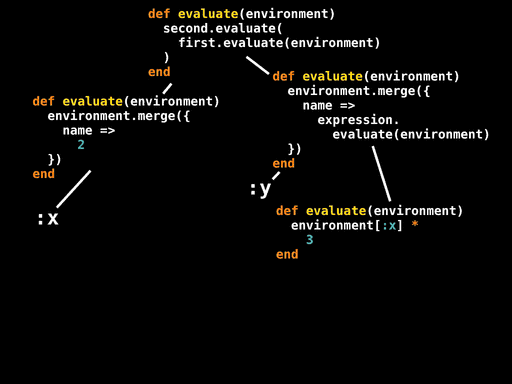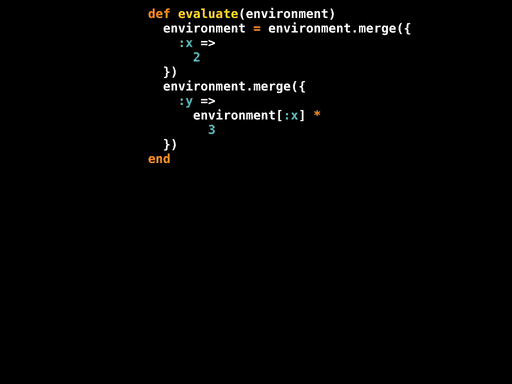
尽管Treetop的设计目的是产出具体语法树,但是用我们定义的node类和语义动作生成的AST是更简单的结构。代码x = 2; y = x * 3的AST如下图所示:
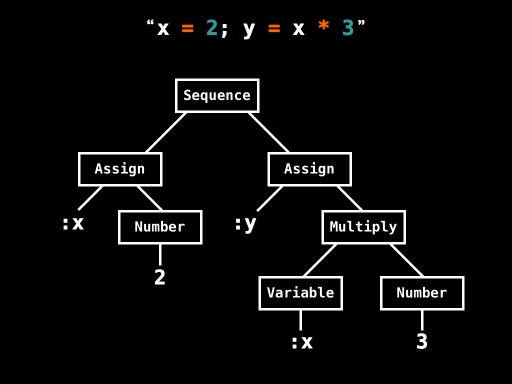
它告诉我们x = 2; y = x * 3 是一个序列语句,包含两个赋值语句:第一个将Number 2赋值给x,第二个将Variable x和Number 3相乘,即Multiply,结果赋值给y。
现在我们获得类AST,可以遍历它并求值。我们为每个AST node类定义一个#evaluate方法,它将对当前节点以及节点的子树求值。当定义好所有的#evaluate方法后,可以调用AST树的根节点的#evaluate求值。
下面是Number,Boolean,Variable的#evaluate定义
class Number
def evaluate(environment)
value
end
end
class Boolean
def evaluate(environment)
value
end
end
class Variable
def evaluate(environment)
environment[name]
end
end
environment(环境)参数是一个哈希表,它将每个变量名和值关联起来。比如说,一个 { x: 7, y: 11 }的environment表示有两个变量,x和y,它们的值分别是7和11.我们假设每个SIMPLE程序的初始environment是一个空的哈希表。后面我们会看到语句求值如何改变environment。
当我们求值Number或者Boolean时,我们不关心它们是否在environment中,因为我们总是返回一个值,这个值是AST node构建的时候的那个值。如果我们对Variable求值,就得看看environment是否存在这个变量的值。
所以如果我们创建一个Number AST节点,然后用空environment开始求值,我们得到原始的Ruby整数:
>> Number.new(3).evaluate({})
=> 3
Boolean与之类似:
>> Boolean.new(false).evaluate({})
=> false
如果我们对一个名为y的Variable求值,并且environment是之前那个,那么我们得到11,然而如果environment中的y的值是另一个,那么对名为y的Variable求值也会得到另一个:
>> Variable.new(:y).evaluate({ x: 7, y: 11 })
=> 11
>> Variable.new(:y).evaluate({ x: 7, y: true })
=> true
下面是二元表达式的#evaluate定义
class Add
def evaluate(environment)
left.evaluate(environment) + right.evaluate(environment)
end
end
class Multiply
def evaluate(environment)
left.evaluate(environment) * right.evaluate(environment)
end
end
class LessThan
def evaluate(environment)
left.evaluate(environment) < right.evaluate(environment)
end
end
这些实现递归地求值左右子表达式,然后对结果执行一些运算。如果是Add节点,那么结果相加;如果是Multiply节点,结果相乘;如果是LessThan节点,结果用<运算符进行比较。
当我们对一个Multiply表达式x * y求值时,environment的x为2,y为3,那么结果是6:
>> Multiply.new(Variable.new(:x), Variable.new(:y)).
evaluate({ x: 2, y: 3 })
=> 6
如果在相同environment中对LessThan表达式x < y求值,得到结果true:
>> LessThan.new(Variable.new(:x), Variable.new(:y)).
evaluate({ x: 2, y: 3 })
=> true
对于语句,#evaluate稍有不同。因为对语句求值会更新environment的值,而不是像表达式求值那样简单的返回一个值。表达式的#evaluate接受一个environment参数,返回一个新的environment,返回的environment与environment参数的差异就是语句的效果导致的。
直接影响变量的语句有Assign:
class Assign
def evaluate(environment)
environment.merge({ name => expression.evaluate(environment) })
end
end
要求值Assign,我们得先求值右边的表达式,得到一个值,然后使用Hash#merge创建一个修改后的environment。
如果我们在空environment中对x = 2求值,我们会得到一个新的environment,里面包含了变量名x到值2的映射关系:
>> Assign.new(:x, Number.new(2)).evaluate({})
=> {:x=>2}
类似的,对y = x * 3求值,会在新的environment中关联变量名y和值6:
>> Assign.new(:y, Multiply.new(Variable.new(:x), Number.new(3))).
evaluate({ x: 2 })
=> {:x=>2, :y=>6}
对序列语句的求值是先求第一个语句,作为中间environment,然后求第二个语句,用中间environment作为第二个语句求值的environment,得到最终的environment:
class Sequence
def evaluate(environment)
second.evaluate(first.evaluate(environment))
end
end
如果序列语句中有两个赋值,那么第二个赋值将是最终赢家:
>> Sequence.new(
Assign.new(:x, Number.new(1)),
Assign.new(:x, Number.new(2))
).evaluate({})
=> {:x=>2}
最后,我们还需要为If和While增加#evaluate:
class If
def evaluate(environment)
if condition.evaluate(environment)
consequence.evaluate(environment)
else
alternative.evaluate(environment)
end
end
end
class While
def evaluate(environment)
if condition.evaluate(environment)
evaluate(body.evaluate(environment))
else
environment
end
end
end
If语句根据它的条件选择求值两个子语句中的一个。While在条件为true的情况下反复对循环体求值。
现在,我们已经为所有表达式和语句实现了#evaluate,我们可以解析简单的SIMPLE程序,然后得到AST。让我们看看在空environment中对x = 2; y = x * 3求值会得到什么:
>> SimpleParser.new.parse('x = 2; y = x * 3').
to_ast.evaluate({})
=> {:x=>2, :y=>6}
正如期待的那样,x和y的最终结果分别是2和6。
让我们尝试更复杂的程序:
>> SimpleParser.new.parse('x = 1; while (x < 5) { x = x * 3 }').
to_ast.evaluate({})
=> {:x=>9}
这个程序将初始化x为1,然后反复的将它翻三倍,直到它大于5。当求值结束,x的值为9,因为9是最小的大于等于5且三倍之于x的值。
以上,我们实现了一个解释器:解析器读取源代码,生成具体语法树,然后语法制导翻译将具体语法树转换为AST,最后遍历AST求值。
解释器是单阶段执行(single-stage execution)。我们可以将源程序和其它数据(在SIMPLE的例子中是初始的空environment)作为解释器的输入,然后解释器基于输入得到输出:

所有的过程都发生在运行时——程序执行阶段
编译
现在我们了解了解释器是如何工作的,那编译器呢?
编译器将源码解析为AST,然后遍历它,和解释器一样的套路。但是不同的是,编译器不根据AST节点语义执行代码,它是生成代码。
让我们写一个SIMPLE到JavaScript的编译器来解释这个过程。现在不为AST node定义#evaluate方法,我们定义一个#to_javascript方法,这个方法将所有表达式和语句节点转换为JavaScript代码字符串。
下面是Number,Boolean,Variable的#to_javascript定义:
require 'json'
class Number
def to_javascript
"function (e) { return #{JSON.dump(value)}; }"
end
end
class Boolean
def to_javascript
"function (e) { return #{JSON.dump(value)}; }"
end
end
class Variable
def to_javascript
"function (e) { return e[#{JSON.dump(name)}]; }"
end
end
上面的每个#to_javascript都会生成一个JavaScript的函数,这个函数接受一个environment参数e,然后返回一个值。对于Number表达式,返回的是Number所表达的整数:
>> Number.new(3).to_javascript
=> "function (e) { return 3; }"
我们可以获取编译后的JavaScript代码,然后在浏览器console界面,或者Node.js REPL中调用JavaScript函数:
// 译注:下面是JavaScript代码
> program = function (e) { return 3; }
[Function]
> program({ x: 7, y: 11 })
3
类似的,Boolean AST节点编译后也是一个JS函数,它返回true或者false:
>> Boolean.new(false).to_javascript
=> "function (e) { return false; }"
SIMPLE的Variable AST节点编译后会在环境e中查找合适的变量,并返回这个值:
>> Variable.new(:y).to_javascript
=> "function (e) { return e["y"]; }"
很显然,上面的函数返回的内容取决于环境e的内容:
> program = function (e) { return e["y"]; }
[Function]
> program({ x: 7, y: 11 })
11
> program({ x: 7, y: true })
true
下面是二元表达式的#to_javascript实现
class Add
def to_javascript
"function (e) { return #{left.to_javascript}(e) + #{right.to_javascript}(e); }"
end
end
class Multiply
def to_javascript
"function (e) { return #{left.to_javascript}(e) * #{right.to_javascript}(e); }"
end
end
class LessThan
def to_javascript
"function (e) { return #{left.to_javascript}(e) < #{right.to_javascript}(e); }"
end
end
我们将二元表达式的左右子表达式编译成JavaScript的函数,然后外面再用JavaScript代码包裹。当这段代码真正执行的时候,左右子表达式的js函数都会被调用,得到值,然后两个值做加法、乘法或者比较运算。让我们以x * y为例,看看编译过程:
>> Multiply.new(Variable.new(:x), Variable.new(:y)).to_javascript
=> "function (e) { return function (e) { return e["x"]; }(e) *
function (e) { return e["y"]; }(e); }"
然后将编译得到的JavaScript代码(和上面一样,只是看起来更美观)放到支持的环境中运行:
> program = function (e) {
return function (e) {
return e["x"];
}(e) * function (e) {
return e["y"];
}(e);
}
[Function]
> program({ x: 2, y: 3 })
6
接下来是语句的#to_javascript,If用的是JavaScript的条件语句,While是JavaScript的循环,诸如此类。最外面和表达式一样用一个JavaScript函数包裹,该函数接受一个环境e,语句可以更新环境。
class Assign
def to_javascript
"function (e) { e[#{JSON.dump(name)}] = #{expression.to_javascript}(e); return e; }"
end
end
class If
def to_javascript
"function (e) { if (#{condition.to_javascript}(e))" +
" { return #{consequence.to_javascript}(e); }" +
" else { return #{alternative.to_javascript}(e); }" +
' }'
end
end
class Sequence
def to_javascript
"function (e) { return #{second.to_javascript}(#{first.to_javascript}(e)); }"
end
end
class While
def to_javascript
'function (e) {' +
" while (#{condition.to_javascript}(e)) { e = #{body.to_javascript}(e); }" +
' return e;' +
' }'
end
end
之前我们试过解释器解释x = 1; while (x < 5) { x = x * 3 },现在我们试试编译器编译:
>> SimpleParser.new.parse('x = 1; while (x < 5) { x = x * 3 }').
to_ast.to_javascript
=> "function (e) { return function (e) { while (function (e)
{ return function (e) { return e["x"]; }(e) < function (e)
{ return 5; }(e); }(e)) { e = function (e) { e["x"] =
function (e) { return function (e) { return e["x"]; }(e) *
function (e) { return 3; }(e); }(e); return e; }(e); } return
e; }(function (e) { e["x"] = function (e) { return 1; }(e);
return e; }(e)); }"
尽管编译后的代码比源程序还长,但是至少我们已经将SIMPLE代码转换为了JavaScript代码。如果我们在JavaScript的环境中运行编译后的代码,我们会获得和解释执行一样的结果——x最终是9:
> program = function (e) {
return function (e) {
while (function (e) {
return function (e) {
return e["x"];
}(e) < function (e) {
return 5;
}(e);
}(e)) {
e = function (e) {
e["x"] = function (e) {
return function (e) {
return e["x"];
}(e) * function (e) {
return 3;
}(e);
}(e);
return e;
}(e);
}
return e;
}(function (e) {
e["x"] = function (e) { return 1; }(e);
return e;
}(e));
}
[Function]
> program({})
{ x: 9 }
这个编译器相当的傻——想让它聪明些需要付出更多的努力——但是它向我们展示了如何在只能运行JavaScript的机器上执行SIMPLE程序。
编译器是双阶段执行(two-stage execution)。首先我们提供源程序,编译器接受它并生成目标程序作为输出。接下来,我们拿出目标程序,给它一些输入,然后允许它,得到最终结果:
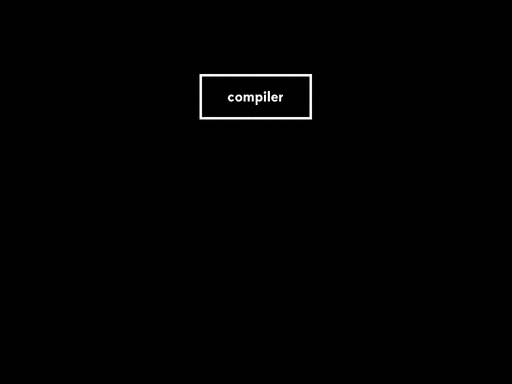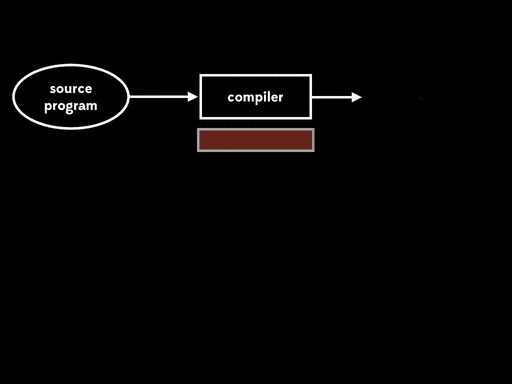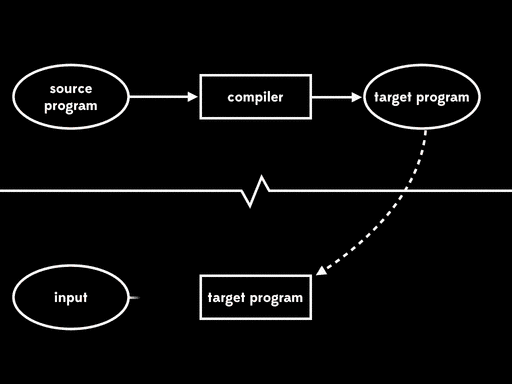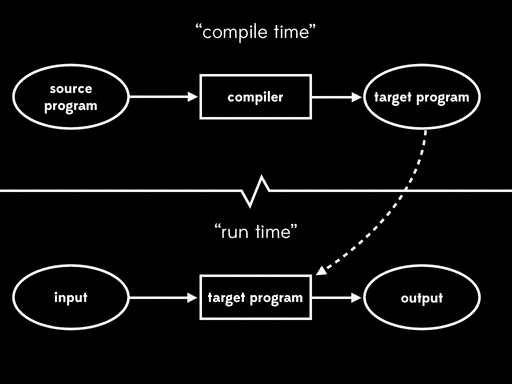
编译和解释的最终结果是一致的——源代码加输入都最终变成了输出——但是它将执行过程分成了两个阶段。第一个阶段是编译时,当目标程序生成后,第二个阶段是运行时,这一阶段读取输入和目标程序,最终得到输出。
好消息是一个好的编译器生成的目标程序会比解释器执行的更快。将计算过程分成两个阶段免除了运行时的解释开销:解析源代码,构造AST,遍历AST树这些过程都在编译时完成,它们不影响程序运行。
(编译还有其它性能受益,比如编译器可以使用更简洁的数据结构和优化让目标程序跑的更快,尤其是在确定了目标程序运行的机器的情况下。)
坏消息是编译会比解释更难实现,原因有很多:
- 编译器必须要考虑两个阶段。当我们写解释器的时候,我们只需要关心解释器的执行,但是编译器还需要考虑到它生成的代码在运行时的行为
- 编译器开发者需要懂两门编程语言。解释器用一门编程语言编写,运行也是这一门语言,而我们的SIMPLE编译器使用Ruby写的,生成的目标程序代码却是JavaScript片段。
- 将动态语言编译为高效的目标程序生来就难。像Ruby和JavaScript这种语言允许程序在运行时改变程序自身或者新增代码,因此程序源码的静态表示没有必要告诉编译器它想知道的关于自己在运行时的情况。
总结来说,写解释器比写编译器要简单,但是解释程序比执行编译后的程序要慢。解释器只有一个阶段,只用一门语言,并且动态语言也是没问题的——如果程序在运行时自身改变了,这没问题,因为AST可以同步更新,解释器也工作正常——但是这种简洁和灵活性会招致运行时性能惩罚。
理想情况下我们想只写一个解释器,但是我们程序要想运行的快一些,通常还是需要再写个编译器。
部分求值
程序员总是使用解释器和编译器,但还有另一种操纵程序的程序不太为人所知:部分求值器。部分求值器是解释器和编译器的混合:

解释器立即执行程序,编译器生成程序稍后执行,而部分求值器立刻执行部分代码,然后剩下的代码稍后执行。
部分求值器读取程序(又叫subject program)和程序的输入,然后只执行部分代码,这些代码直接依赖输入。当这些部分被求值后,剩下的程序部分(又叫residual program)作为输出产出。
部分求值(partial evaluation)允许我们提取程序的一部分执行。现在我们不必一次提供程序的所有输入,我们可以只提供一些,剩下的以后提供。
现在,我们不用一次执行整个subject program,我们可以将它和一些程序输入放到部分求值器里面。部分求值器将执行subject program的一部分,产生一个residual program;接下来,我们执行residual program,并给它剩下的程序输入:

部分求值的总体效果是,通过将一些工作从未来(当我们打算运行程序时)移到现在,将单阶段执行变成了两个阶段,程序运行时可以少执行一些代码。
部分求值器将subject program转换为AST,这一步和解释器编译器一样,接着读取程序的部分输入。它分析整个AST找到哪些地方用到了程序的部分输入,然后这些地方被求值,使用包含求值结果的代码代替。当部分求值完成时,AST重新转换为文本形式,即输出为residual program。
真的构建一个部分求值器太庞大了,不太现实,但是我们可以通过一个示例来了解部分求值的过程。
假设有一个Ruby程序#power,它计算x的n次幂:
def power(n, x)
if n.zero?
1
else
x * power(n - 1, x)
end
end
现在让我们扮演一个Ruby部分求值器的角色,假设我们已经获得了足够的程序输入,知道将用实参5作为第一个形参n调用power。我们可以很容易地生成一个新版本的方法,称之为#power_5,其中形参n已被删除,所有出现n的地方都被替换为5(这也叫常量传播):
def power_5(x)
if 5.zero?
1
else
x * power(5 - 1, x)
end
end
我们找到了两个表达式——5.zero?和5 - 1——这是潜在的部分求值对象。让我们选一个,对5.zero?求值,用结果false代替这个表达式:
def power_5(x)
if false
1
else
x * power(5 - 1, x)
end
end
这个部分求值行为使得我们还能再求值整个条件语句——if false ... else ... end总是走else分支(稀疏常量传播):
def power_5(x)
x * power(5 - 1, x)
end
现在对5 - 1求值,用常量4代替(常量折叠):
def power_5(x)
x * power(4, x)
end
现在停一下,因为我们知道#power的行为,这里有一个优化机会,用#power方法的代码代替这里的power(4,x)调用(内联展开),然后再用4代替所有形参n
def power_5(x)
x *
if 4.zero?
1
else
x * power(4 - 1, x)
end
end
情况和之前一样,我们知道4.zero?,用false代替:
def power_5(x)
x *
if false
1
else
x * power(4 - 1, x)
end
end
继续,知道条件语句走else分支:
def power_5(x)
x *
x * power(4 - 1, x)
end
知道4 - 1的值是3:
def power_5(x)
x *
x * power(3, x)
end
如此继续。通过将#power调用内联,然后对常量表达式求值,我们能用乘法代替它们,直到0:
def power_5(x)
x *
x *
x *
x *
x * power(0, x)
end
让我们再手动展开一次:
def power_5(x)
x *
x *
x *
x *
x *
if 0.zero?
1
else
x * power(0 - 1, x)
end
end
我们直到0.zero?是true:
def power_5(x)
x *
x *
x *
x *
x *
if true
1
else
x * power(0 - 1, x)
end
end
这是我们第一次在例子中遇到if true而不是if false的情况,现在选择then分支,而不是else分支:
def power_5(x)
x *
x *
x *
x *
x *
1
end
最终效果是,我们把#power_5转换为x重复乘以自身五次,然后乘以1。乘以1对计算没有影响,所以可以消除它,最终得到的代码如下:
def power_5(x)
x * x * x * x * x
end
下面是图形化的过程:

#power加上程序输入5,最终经过部分求值,得到residual program#power_5。没有新的代码产生,#power_5的代码是由#power组成的,只是重新安排并以新的方式结合在一起。
#power_5的优势是当输入为5的时候它比#power跑的更快。#power_5简单的重复乘以x五次,而#power是执行了五次递归的方法调用,零值检查,条件计算和减法。这些工作都由部分求值器完成,然后结果保留在residual program中,现在redisual program只依赖未知的程序输入x。
所以,如果我们直到n为5,那么#power_5就是#power优化改进版。
注意部分求值和部分应用(partial application)是不一样的。基于部分应用的#power_5和部分求值得到的residual program是不一样的:
def power_5(x)
power(5, x)
end
通过部分应用,我们固定一个常量到代码中,成功的将#power转换为了#power_5,这个实现也是没问题的:
>> power_5(2)
=> 32
但是这个版本的#power_5不见得比#power更高效——实际上它还会慢一些,因为它引入了额外的方法调用。
或者,我们也可以不定义新的方法,而是用Method#to_proc和Proc#curry将#power柯里化(currying)为一个过程,然后用实参5调用柯里化后的过程:
>> power_5 = method(:power).to_proc.curry.call(5)
=> #<Proc (lambda)>
接着,我们调用部分应用后的代码,传入的参数是#power的第二个形参,即x:
>> power_5.call(2)
=> 32
不难看出,部分应用和部分求值很像是,但是仔细审视后可以看出,部分应用是程序内的行为:当我们写代码时,部分应用允许我们固定一些参数,然后得到一个方法的更少参数的版本。而部分求值是程序外部的行为:它是一个源码级别的转换,通过特化一些程序输入,可以得到更高效的方法的版本。
应用
部分求值有很多有用的应用场景。固定程序的一些输入,即特化,可以提供两方面的好处:我们可以编写一个通用的、灵活的程序来支持许多不同的输入,然后,当我们真正知道如何使用这个程序时,我们可以使用一个部分求值器来自动生成一个特化后的版本,该版本移除了代码的通用性,但是提高了性能。
例如,像nginx或[Apache(http://httpd.apache.org/)这样的web服务器在启动时会读取配置文件。该文件的内容会影响服务器后续每个HTTP请求的处理,因此web服务器必须花费一些执行时间来检查其配置数据,以决定要做什么。如果我们对web服务器使用部分求值器专门针对一个特定的配置文件进行部分求值,我们将得到一个新版本,它只执行该文件所说的操作;在启动期间解析配置文件并在每个请求期间检查其数据的开销将不再是程序的一部分。
另一个经典的例子是光线跟踪。要制作一部摄影机在三维场景中移动的电影,我们可能最终会使用光线跟踪器渲染数千个单独的帧。但是如果场景对于每一帧都是相同的,我们可以使用一个部分求值器来专门处理光线跟踪器对于我们特定场景的描述,我们会得到一个新的光线跟踪器,它只能渲染该场景。然后,每次我们使用专门的光线跟踪器渲染帧时,都会避免读取场景文件、设置表示其几何体所需的数据结构以及对光线在场景中的行为做出与相机无关的决策的开销。
一个更实际(有一些争议)的例子是OpenGL管道。在OS X中,OpenGL管道的一部分是用LLVM中间语言编写的,这其中包括一些GPU硬件就实现了的。不管GPU支持与否,都可以用软件的方式实现,而有了部分求值,Apple公司可以对LLVM部分求值,删除掉特定GPU上不需要的代码,剩下的代码是硬件没有直接实现的。
二村映射
首先,我想说一个cool story。
1971年,Yoshihiko Futamura在Hitachi Central Research Laboratory工作时发表了一些有趣的论文。他在思考部分求值如何更早的处理subject program的一些输入,然后产出后续可以执行的residual program。
具体来说,Futamura将解释器作为部分求值的输入并思考了一些问题。他意识到解释器只是一个计算机程序而已,它读取输入,执行,然后得到输出。解释器的输入之一是源码,但是除了这个比较特别外解释器和普通程序没啥两样。

他在思考,如果我们先用部分求值器做一些解释器的工作,会发生什么?
如果我们使用部分求值器特化解释器和它的某个程序的输入,我们会得到residual program。然后,我们可以用程序的剩下的输入加上residual program,得到最终结果:

最终效果和用解释器直接运行程序一样,只是现在单阶段执行变成了两阶段。
Futamura注意到residual program读取剩下的程序输入,然后产生输出,我们通常把这个residual program称为目标程序——一个能被底层机器直接执行的源程序的新版本。这意味着部分求值器读取源程序,产出目标程序,它实际上扮演了编译器的角色。
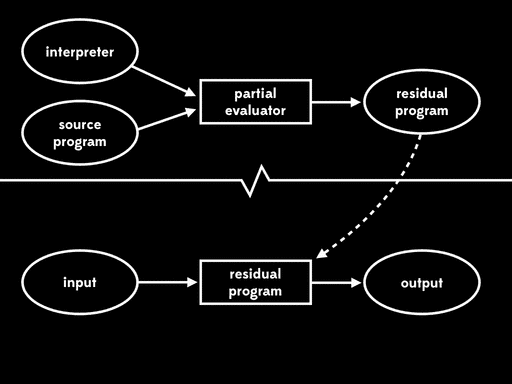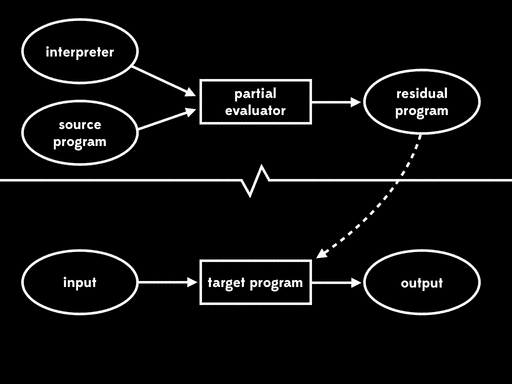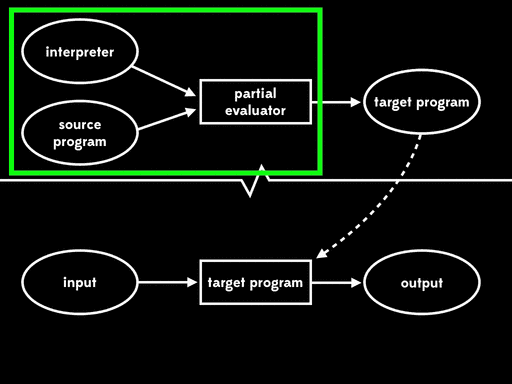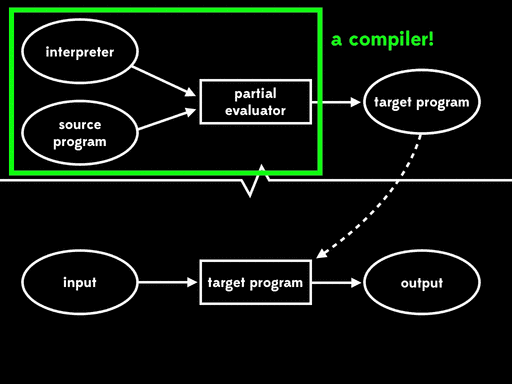
看起来难以置信。它是怎么工作的?让我们看一个示例。下面是SIMPLE解释器的top level环境:
source, environment = read_source, read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse(source).to_ast
puts ast.evaluate(environment)
解释器读取源程序和初始化environment(从哪读的我们不关心)。它加载Treetop语法文件,实例化解析器,然后解析器产出AST,然后对AST求值并输出。#evaluate的定义和前面解释器小结是一样的。
让我们想象一下将这个解释器和SIMPLE源代码 x = 2; y = x * 3作为输入放入Ruby部分求值器。这意味这上面代码中的#read_source将返回字符串 x = 2; y = x * 3,所以我们可以用字符串代替它:
source, environment = 'x = 2; y = x * 3', read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse(source).to_ast
puts ast.evaluate(environment)
现在,让我手动做一下复写传播,由于source变量只在代码中用到了一次,我们可以完全消除它,用值代替:
environment = read_environment
Treetop.load('simple.treetop')
ast = SimpleParser.new.parse('x = 2; y = x * 3').to_ast
puts ast.evaluate(environment)
构造AST的数据都已经备起了,Treetop语法文件也准备好了,现在我们还知道待解析的字符串是什么。让我们手动求值表达式,创建一个手工AST代替解析过程:
environment = read_environment
ast = Sequence.new(
Assign.new(
:x,
Number.new(2)
),
Assign.new(
:y,
Multiply.new(
Variable.new(:x),
Number.new(3)
)
)
)
puts ast.evaluate(environment)
我们将解释器简化为读取环境、构建AST字面值、在AST根节点上调用#evaluate。
在特定节点上调用#evaluate会发生什么?我们早已直到每种节点的#evaluate定义,现在可以遍历树,然后找到AST节点的#evaluate调用,进行部分求值,和我们之前对#power做的差不多。AST包含了所有我们需要的数据,所以我们可以逐步将所有的#evaluate归纳为几行Ruby代码:
对于Number和Variable,我们直到它的值和变量名字,所以我们可以将这些信息传播到其它节点。对于Multiply和Assign节点,我们可以内联方法调用。对于序列语句,我们可以先内联first.evaluate再内联second.evaluate,使用临时变量保持中间environment。
下面的代码隐藏了大量的细节,但重要的是,我们拥有最终代码和数据,它们可以帮助我们对AST根节点的#evaluate方法进行部分求值:
def evaluate(environment)
environment = environment.merge({ :x => 2 })
environment.merge({ :y => environment[:x] * 3 })
end
让我们回到解释器的主要代码:
environment = read_environment
ast = Sequence.new(
Assign.new(
:x,
Number.new(2)
),
Assign.new(
:y,
Multiply.new(
Variable.new(:x),
Number.new(3)
)
)
)
puts ast.evaluate(environment)
既然我们已经生成了AST根节点的#evaluate方法,现在我们可以对ast.evaluate(environment)部分求值,方法是展开这个调用:
environment = read_environment
environment = environment.merge({ :x => 2 })
puts environment.merge({ :y => environment[:x] * 3 })
这个Ruby代码和原始的SIMPLE代码产生了相同的行为:它将x设置为2,将y设置为x乘以3,x和y都存放到environment中。所以,从某种意义上说,我们通过对解释器进行部分求值,将SIMPLE程序编译为Ruby代码——虽然还有一些其它environment的内容,但是总之,我们最终的Ruby代码做的还是x = 2; y = x * 3这件事。
和#power那个例子一样,我们没有写Ruby代码,residual program是重新安排解释器的代码并以新的方式结合在一起,这样它就完成了与最初的SIMPLE程序相同的功能。
这种方式被称为第一二村映射(first futamura projection):如果我们将源代码和解释器一起进行部分求值,我们将得到目标程序。
Futamura很高兴他意识到了这一点。然后他继续思考更多,他继续意识到将源代码和解释器一起进行部分求值得到目标程序这件事本身,其实就是给一个程序多个参数。如果我们先使用部分求值来完成部分求值器的一些工作,然后通过运行剩余程序来完成其余的工作,会发生什么情况?
如果我们用部分求值来特化部分求值器的一个输入—— 解释器——我们会得到residual program。然后后面我们可以运行这个residual program,将源程序作为输入,得到目标程序,最后运行目标程序,传入剩余程序输入,得到最终结果:
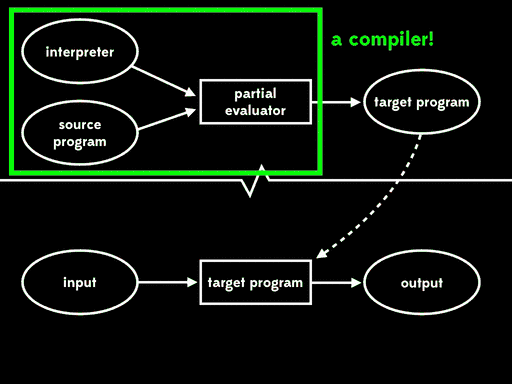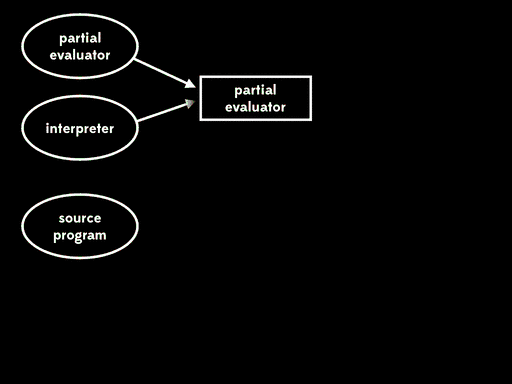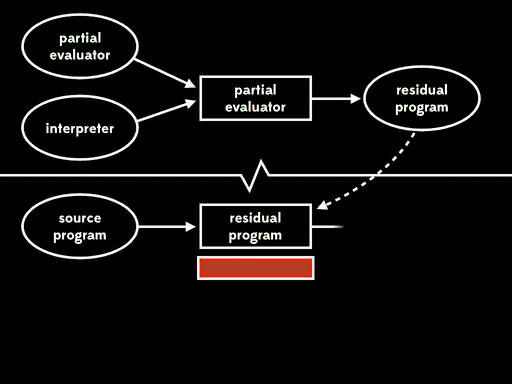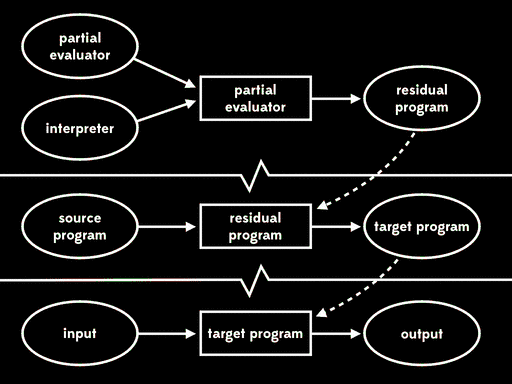
总体的效果与给出程序输入,直接用解释器运行源程序行为一致,但现在执行已分为三个阶段。
Futamura注意到residual program读取源程序产生目标程序,这个过程是我们常说的编译器做的事情。这意味着部分求值器将解释器作为输入,输出来编译器。换句话说,部分求值器此时成了编译器生成器。
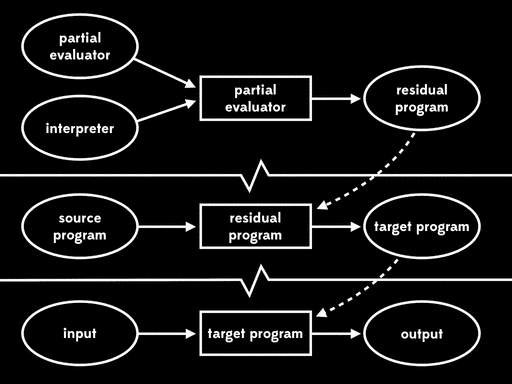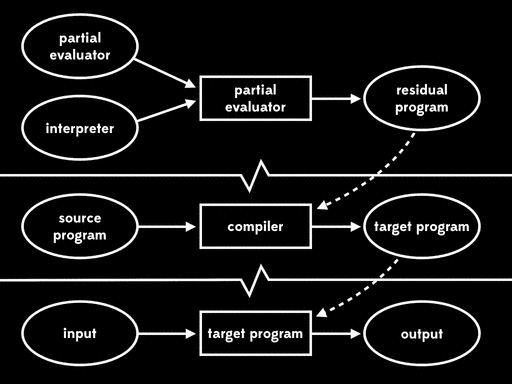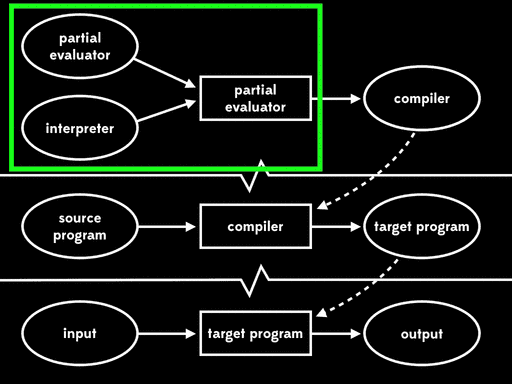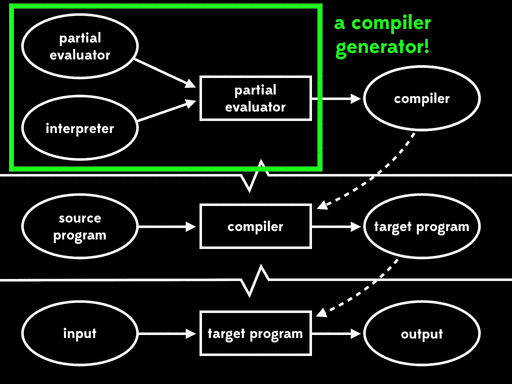
这种方式被称为第二二村映射(second futamura projection):如果我们将部分求值器和解释器一起进行部分求值,我们将得到编译器。
Futamura很高兴他意识到了这一点。然后他继续思考更多,他继续意识到将部分求值器和解释器一起进行部分求值得到编译器这件事本身,其实就是给一个程序多个参数。如果我们先使用部分求值来完成部分求值器的一些工作,然后通过运行剩余程序来完成其余的工作,会发生什么情况?
如果我们用部分求值来特化部分求值器的一个输入—— 部分求值器——我们会得到residual program。然后后面我们可以运行这个residual program,将解释器作为输入,得到编译器,最后运行编译器,将源程序作为输入得到目标程序,在运行目标程序,给它剩下的程序输入,得到最终结果:
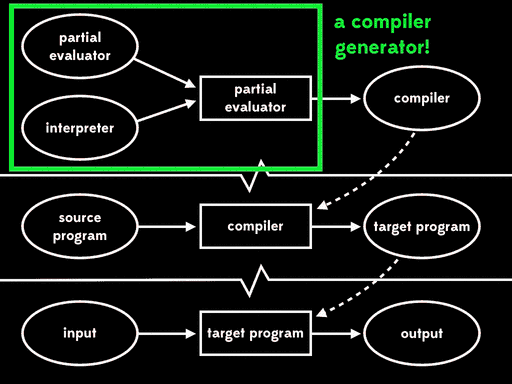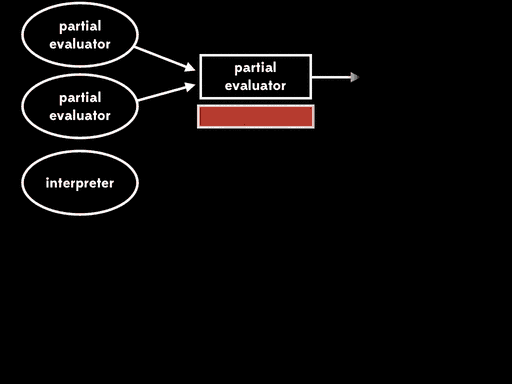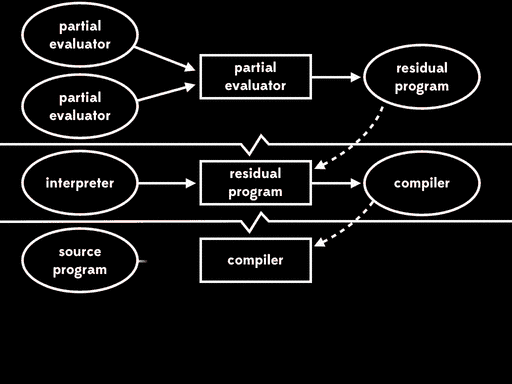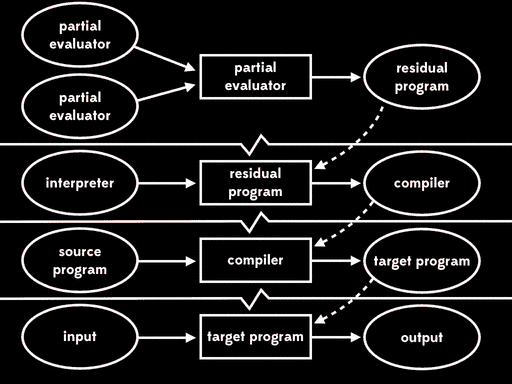
总体的效果与给出程序输入,直接用解释器运行源程序行为一致,但现在执行已分为四个阶段。
Futamura注意到residual program读取解释器产生编译器,这个过程是我们常说的编译器做的事情。这意味着部分求值器产出来一个编译器生成器。换句话说,部分求值器此时成了编译器生成器的生成器。
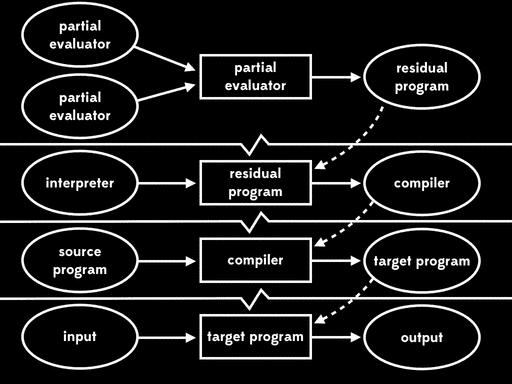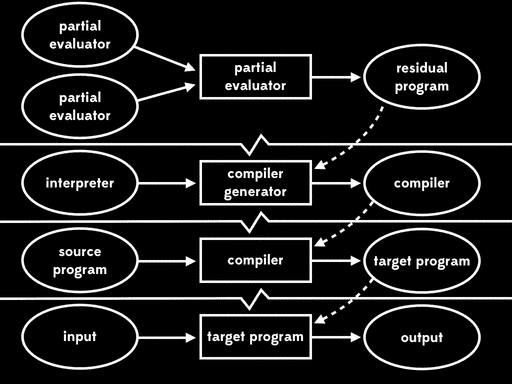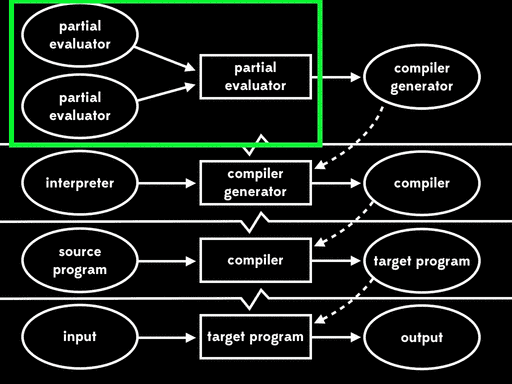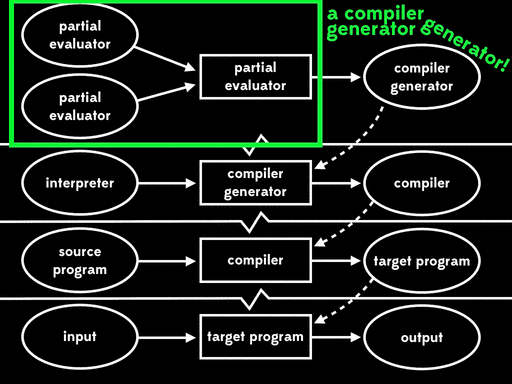
这种方式被称为第三二村映射(third futamura projection):如果我们将部分求值器和部分求值器一起进行部分求值,我们将得到编译器生成器。
谢天谢地,我们不能再进一步了,因为如果我们重复这个过程,我们仍然会对部分求值器本身进行部分求值。只有三个二村映射。
结论
二村映射非常有趣,但不是说有了它编译器工程师就是多余的了。部分求值是一种适用于任何计算机程序的完全通用的技术;当应用于解释器时,它可以消除解析源代码和操作AST的开销,但它不会自动地发明和创造具备工业级水平的编译器的数据结构和优化。 我们仍然需要聪明的人写编译器,使我们的程序尽可能快地运行。
如果你想了解更多关于部分求值的知识,有一本叫做“Partial Evaluation and Automatic Program Generation”的免费书籍详细的讨论了它。LLVM的JIT,PyPy工具链的一部分——即RPython和VM以及它底层依赖的JIT)——也使用相关技术让程序更高效执行。这些项目与Ruby直接相关,因为Rubinius依赖LLVM,还有一个用Python编写的Ruby实现,名为Topaz,也依赖PyPy工具链。
撇开部分求值不谈,Rubinius和JRuby也是高质量的编译器,代码很有趣,可以免费下载。如果你对操纵程序的程序感兴趣,你可以深入Rubinius或JRuby,看看它们是如何工作的,并且(根据Matz的RubyConf 2013主题演讲提到的)参与它们的开发。