这里使用的是requests库和pyquery库,传说中的爬虫神器。
Requests 是python的一个简单优雅的HTTP库,基于urllib3。
直接贴一下逗逼的官方说明:
Requests is an elegant and simple HTTP library for Python, built for human beings.
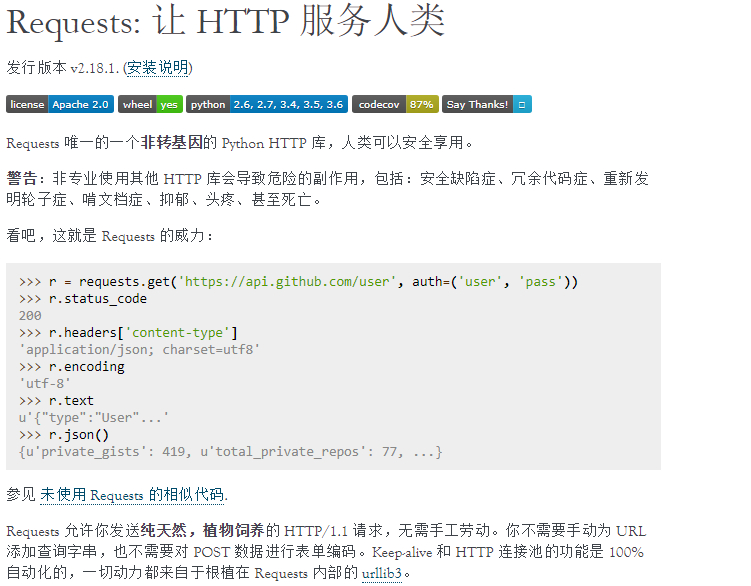
相比urllib,确实简单好用,更多详情请自行查询官网。
Pyquery,a jquery-like library for python,是jquery的python实现,可以让你在python中使用jquery语法解析HTML网页内容。
安装requests和pyquery:
# pip3 install requests
# pip3 install pyquery
查看一下帮助文档:
>>> import requests
>>> r = requests.get('https://github.com/timeline.json')
>>> type(r)
<class 'requests.models.Response'>
>>> dir(r)
['__attrs__', '__bool__', '__class__', '__delattr__', '__dict__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getstate__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__module__', '__ne__', '__new__', '__nonzero__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__', '__weakref__', '_content', '_content_consumed', 'apparent_encoding', 'close', 'connection', 'content', 'cookies', 'elapsed', 'encoding', 'headers', 'history', 'is_permanent_redirect', 'is_redirect', 'iter_content', 'iter_lines', 'json', 'links', 'ok', 'raise_for_status', 'raw', 'reason', 'request', 'status_code', 'text', 'url']
>>> r.text
>>> import pyquery
>>> dir(pyquery)
['PyQuery', '__builtins__', '__cached__', '__doc__', '__file__', '__loader__', '__name__', '__package__', '__path__', '__spec__', 'cssselectpatch', 'openers', 'pyquery']
>>> help(pyquery.pyquery)
- requests.get() 用来获取网页内容。
- pyquery.pyquery() 用来解析获取到的内容。
示例,爬取豆瓣电影TOP250,输出电影名称和评分:
# cat spider.py
#导入模块
import requests
from pyquery import PyQuery as pq
for i in range(10):
#定义url,由于每页只显示25个,需要遍历10次
num = i * 25
url = 'https://movie.douban.com/top250?start='+ str(num)
#抓取页面内容
r = requests.get(url)
#使用pyquery解析获取到的页面内容
for movie in pq(r.text).find('.item'):
#过滤出电影名称'.title'
print(pq(movie).find('.title').html(),end=' ')
#过滤出评分'.rating_num'
print(pq(movie).find('.rating_num').html())
运行结果:
# python3 spider.py
肖申克的救赎 9.6
霸王别姬 9.5
这个杀手不太冷 9.4
阿甘正传 9.4
美丽人生 9.5
千与千寻 9.2
辛德勒的名单 9.4
泰坦尼克号 9.2
盗梦空间 9.2
机器人总动员 9.3
海上钢琴师 9.2
三傻大闹宝莱坞 9.1
忠犬八公的故事 9.2
放牛班的春天 9.2
大话西游之大圣娶亲 9.2
龙猫 9.1
教父 9.2
楚门的世界 9.1
乱世佳人 9.2
天堂电影院 9.1
触不可及 9.1
当幸福来敲门 8.9
熔炉 9.2
无间道 9.0
搏击俱乐部 9.0
...
...
# python3 spider.py | wc -l
250
另外,还有名声在外的scrapy爬虫框架,上手成本较高。
参考:
http://docs.python-requests.org/zh_CN/latest/user/quickstart.html
https://pypi.python.org/pypi/pyquery
http://www.cnblogs.com/tangdongchu/p/4229049.html