https://www.manongdao.com/article-2418812.html
规划使用版本
| 产品名称 | 版本 | url地址 |
|---|---|---|
| prometheus | 2.22.1 | https://github.com/prometheus/prometheus/releases/tag/v2.22.1 |
| alertmanager | v0.21.0 | https://github.com/prometheus/alertmanager/releases/tag/v0.21.0 |
| consul | 1.8.5 | docker.io/consul |
| consulR | latest | https://github.com/qist/registy-consul-service/releases |
| victoriametrics | v1.50.2 | https://github.com/VictoriaMetrics/VictoriaMetrics/releases |
| kube-prometheus | v0.43.2 | https://github.com/prometheus-operator/kube-prometheus |
| kube-prometheus | 修改版本 | https://github.com/qist/k8s/tree/master/k8s-yaml/kube-prometheus |
| grafana | v7.3.2 | docker.io/grafana/grafana |
部署环境
| 部署环境 | 部署IP | 部署方式 |
|---|---|---|
| 阿里云账号1 | 10.8.23.80 | 二进制部署 |
| 阿里云账号2 | 172.16.4.141 | 二进制部署 |
| 华为云 | 10.9.12.133 | 二进制部署 |
| 阿里云ack | kube-prometheus | K8S部署 |
| 办公idc | kube-prometheus | K8S部署 |
| 监控汇总 | 192.168.2.220 | 二进制部署 |
| grafana | K8S 方式部署 |
网络互通
1、阿里云1,2使用阿里云云企网互通
2、阿里云1与华为云,办公IDC 使用ipsec*** 互通 openswan 安装
3、阿里云1自定义路由然后发布 这样云企网就能访问,华为云请关闭网卡安全检查安装openswan 服务器关闭 然后配置路由
部署阿里云1,2,华为云 监控系统(二进制模式)
##### 二进制部署目录 /apps/ 业务名目录
#####下载
cd /apps
wget https://github.com/prometheus/prometheus/releases/download/v2.22.1/prometheus-2.22.1.linux-amd64.tar.gz
wget https://github.com/prometheus/alertmanager/releases/download/v0.21.0/alertmanager-0.21.0.linux-amd64.tar.gz
wget https://github.com/qist/registy-consul-service/releases/download/release/consulR
#### 安装docker consul 使用
yum-config-manager --add-repo http://mirrors.aliyun.com/docker-ce/linux/centos/docker-ce.repo
yum install docker-ce
# 启动consul
docker run -d --restart=always -p 8500:8500 -e CONSUL_BIND_INTERFACE='eth0' --name=consulone consul agent -server -bootstrap -ui -client='0.0.0.0'
# 部署prometheus
cd /apps
mkdir -p prometheus/{bin,conf,data}
tar -xvf prometheus-2.22.1.linux-amd64.tar.gz
mv prometheus-2.22.1.linux-amd64/* prometheus/bin
配置prometheus
cd prometheus/conf
vim prometheus.yml
# my global config
global:
scrape_interval: 1m
scrape_timeout: 1m
evaluation_interval: 10s
external_labels:
environment: aliyun1 # 环境名字 多环境建议配置
alerting:
alertmanagers:
- static_configs:
- targets: ['127.0.0.1:9093'] # 报警地址
rule_files:
- "/apps/prometheus/conf/rules/*.yaml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
#- job_name: 'prometheus'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
#static_configs:
#- targets: ['localhost:9090']
- job_name: 'consul-prometheus' # consul 自动发现名字
scrape_interval: 30s
scrape_timeout: 30s
consul_sd_configs:
- server: '127.0.0.1:8500'
services: []
relabel_configs:
- source_labels: [__meta_consul_service]
regex: "consul|aliyun-exporter" # 需要过滤的自动发现service 名
action: drop
- source_labels: [__meta_consul_service]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [__meta_consul_service]
separator: ;
regex: (.*)
target_label: job # 重写job 名为consul 配置的service 名字
replacement: $1
action: replace
- source_labels: [__meta_consul_service_id]
separator: ;
regex: (.*)
target_label: service_name # 添加标签 报警使用
replacement: $1
action: replace
- job_name: 'aliyun-exporter'# 阿里云api 监控 拉取阿里云监控指标很慢所以改成1分钟拉取一次所以独立出来
scrape_interval: 60s
scrape_timeout: 60s
consul_sd_configs:
- server: '127.0.0.1:8500'
services: []
relabel_configs:
- source_labels: [__meta_consul_service]
regex: "aliyun-exporter" # 需要监控 consul service
action: keep
- source_labels: [__meta_consul_service]
separator: ;
regex: (.*)
target_label: service
replacement: $1
action: replace
- source_labels: [__meta_consul_service]
separator: ;
regex: (.*)
target_label: job
replacement: $1
action: replace
- source_labels: [__meta_consul_service_id]
separator: ;
regex: (.*)
replacement: $1
target_label: service_name # 添加标签 报警使用
action: replace
# 配置prometheus 启动参数
vim prometheus
PROMETHEUS_OPTS="--web.console.templates=/apps/prometheus/bin/consoles \
--web.console.libraries=/apps/prometheus/bin/console_libraries \
--config.file=/apps/prometheus/conf/prometheus.yml \
--storage.tsdb.path=/apps/prometheus/data/prometheus \
--storage.tsdb.retention.time=1d \
--storage.tsdb.min-block-duration=2h \
--storage.tsdb.max-block-duration=2h \
--web.enable-lifecycle \
--storage.tsdb.no-lockfile \
--web.route-prefix=/"
# 创建报警规则
mkdir -p /apps/prometheus/conf/rules
cp /apps/prometheus/conf/rules
vim node-rules.yaml
groups:
- name: linux Disk Alerts
rules:
- alert: NodeDiskUseage
expr: 100 - (node_filesystem_avail_bytes{fstype=~"ext4|xfs",mountpoint!="/apps/docker/overlay",mountpoint!="/var/lib/docker/devicemapper",mountpoint!="/var/lib/docker/containers"} / node_filesystem_size_bytes{fstype=~"ext4|xfs",mountpoint!="/apps/docker/overlay",mountpoint!="/var/lib/docker/devicemapper",mountpoint!="/var/lib/docker/containers"} * 100) > 90
for: 1m
labels:
severity: high
annotations:
summary: "{{ $labels.instance }} Partition utilization too high"
description: "{{ $labels.instance }} Partition usage greater than 90%(Currently used:{{$value}}%)"
- alert: DiskIoPerformance
expr: 100 - (avg by(instance,device,job,service,service_name) (irate(node_disk_io_time_seconds_total[1m])) * 100) < 60
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} The IO utilization rate of incoming disk is too high"
description: "{{ $labels.instance }} The incoming disk IO is greater than 60%(Currently used:{{$value}})"
- name: linux Cpu
rules:
- alert: UserCpuUsage
expr: sum(avg without (cpu)(irate(node_cpu_seconds_total{mode='user'}[5m]))*100) by (instance,job,service,service_name) >50
for: 1m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }}"
description: "{{ $labels.instance }} User CPU Use greater than 50%(Currently used:{{$value}}%)"
- alert: CpuUsage
expr: 100 - (avg by(instance,job,service,service_name) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 80
for: 1m
labels:
severity: warning
annotations:
summary: "{{ $labels.instance }} CPU The utilization rate is too high"
description: "{{ $labels.instance }} CPU Use greater than 60%(Currently used:{{$value}}%)"
- alert: NodeCPUUsage95%
expr: 100 - (avg by(instance,job,service,service_name) (irate(node_cpu_seconds_total{mode="idle"}[5m])) * 100) > 95
for: 1m
labels:
severity: critical
annotations:
summary: "{{ $labels.instance }} CPU The utilization rate is too high"
description: "{{ $labels.instance }} CPU Use greater than 95%(Currently used:{{$value}}%)"
- name: linux Memory
rules:
#- alert: MemoryLow
# expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100>80
# for: 1m
# labels:
# severity: high
# annotations:
# summary: "{{ $labels.instance }} High memory usage"
# description: "{{ $labels.instance }} Memory greater than 90%(Currently used:{{$value}}%)"
- alert: NodeMemoryUsageTooHigh95%
expr: (1 - (node_memory_MemAvailable_bytes / (node_memory_MemTotal_bytes)))* 100>95
for: 1m
labels:
severity: high
annotations:
summary: "{{ $labels.instance }} High memory usage"
description: "{{ $labels.instance }} Memory greater than 95%(Currently used:{{$value}}%)"
- name: linux Clock
rules:
- alert: NodeClockSkewDetected
annotations:
message: Clock on {{ $labels.instance }} is out of sync by more than 300s.
Ensure NTP is configured correctly on this host.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodeclockskewdetected
summary: Clock skew detected.
expr: |
(
node_timex_offset_seconds > 0.05
and
deriv(node_timex_offset_seconds[5m]) >= 0
)
or
(
node_timex_offset_seconds < -0.05
and
deriv(node_timex_offset_seconds[5m]) <= 0
)
for: 10m
labels:
severity: warning
- alert: NodeClockNotSynchronising
annotations:
message: Clock on {{ $labels.instance }} is not synchronising. Ensure NTP
is configured on this host.
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodeclocknotsynchronising
summary: Clock not synchronising.
expr: |
min_over_time(node_timex_sync_status[5m]) == 0
for: 10m
labels:
severity: warning
- name: Instance Down
rules:
- alert: InstanceDown
expr: (up{job!="node-exporter",job!="windows-exporter"}) == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Instance {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minute."
- name: Node Down
rules:
- alert: NodeDown
expr: (up{job=~"node-exporter|windows-exporter"}) == 0
for: 2m
labels:
severity: critical
annotations:
summary: "Node {{ $labels.instance }} down"
description: "{{ $labels.instance }} of job {{ $labels.job }} has been down for more than 2 minute."
- name: linux Network err
rules:
- alert: NodeNetworkReceiveErrs
annotations:
description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered
{{ printf "%.0f" $value }} receive errors in the last two minutes.'
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodenetworkreceiveerrs
summary: Network interface is reporting many receive errors.
expr: |
increase(node_network_receive_errs_total[2m]) > 10
for: 1h
labels:
severity: warning
- alert: NodeNetworkTransmitErrs
annotations:
description: '{{ $labels.instance }} interface {{ $labels.device }} has encountered
{{ printf "%.0f" $value }} transmit errors in the last two minutes.'
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodenetworktransmiterrs
summary: Network interface is reporting many transmit errors.
expr: |
increase(node_network_transmit_errs_total[2m]) > 10
for: 1h
labels:
severity: warning
- alert: NodeHighNumberConntrackEntriesUsed
annotations:
description: '{{ $value | humanizePercentage }} of conntrack entries are used'
runbook_url: https://github.com/kubernetes-monitoring/kubernetes-mixin/tree/master/runbook.md#alert-name-nodehighnumberconntrackentriesused
summary: Number of conntrack are getting close to the limit
expr: |
(node_nf_conntrack_entries / node_nf_conntrack_entries_limit) > 0.75
labels:
severity: warning
vim windows-rules.yaml
groups:
- name: Windows Disk Alerts
rules:
# Sends an alert when disk space usage is above 95%
#- alert: DiskSpaceUsage
# expr: 100.0 - 100 * (windows_logical_disk_free_bytes / windows_logical_disk_size_bytes) > 80
# for: 10m
# labels:
# severity: high
# annotations:
# summary: "Disk Space Usage (instance {{ $labels.instance }})"
# description: "Disk Space on Drive is used more than 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: NodeDiskUseage
expr: 100.0 - 100 * (windows_logical_disk_free_bytes / windows_logical_disk_size_bytes) > 90
for: 10m
labels:
severity: critical
annotations:
summary: "Disk Space Usage (instance {{ $labels.instance }})"
description: "Disk Space on Drive is used more than 95%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: DiskFilling
expr: 100 * (windows_logical_disk_free_bytes / windows_logical_disk_size_bytes) < 15 and predict_linear(windows_logical_disk_free_bytes[6h], 4 * 24 * 3600) < 0
for: 10m
labels:
severity: warning
annotations:
summary: "Disk full in four days (instance {{ $labels.instance }})"
description: "{{ $labels.volume }} is expected to fill up within four days. Currently {{ $value | humanize }}% is available.\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- name: Windows Cpu
rules:
- alert: CpuUsage
expr: 100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 80
for: 10m
labels:
severity: warning
annotations:
summary: "CPU Usage (instance {{ $labels.instance }})"
description: "CPU Usage is more than 80%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- alert: NodeCPUUsage95%
expr: 100 - (avg by (instance) (irate(windows_cpu_time_total{mode="idle"}[2m])) * 100) > 95
for: 1m
labels:
severity: critical
annotations:
summary: "CPU Usage (instance {{ $labels.instance }})"
description: "CPU Usage is more than 95%\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"
- name: Windows Memory
rules:
# Alert on hosts that have exhausted all available physical memory
- alert: MemoryExhausted
expr: windows_os_physical_memory_free_bytes == 0
for: 10m
labels:
severity: high
annotations:
summary: "Host {{ $labels.instance }} is out of memory"
description: "{{ $labels.instance }} has exhausted all available physical memory"
#- alert: MemoryLow
# expr: 100 - 100 * windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes > 80
# for: 10m
# labels:
# severity: warning
# annotations:
# summary: "Memory usage for host {{ $labels.instance }} is greater than 80%"
- alert: NodeMemoryUsageTooHigh95%
expr: 100 - 100 * windows_os_physical_memory_free_bytes / windows_cs_physical_memory_bytes > 95
for: 1m
labels:
severity: critical
annotations:
summary: "Memory usage for host {{ $labels.instance }} is greater than 95%"
#- name: Microsoft SQL Server Alerts
#rules:
#- alert: SQL Server Agent DOWN
# expr: windows_service_state{instance="SQL",exported_name="sqlserveragent",state="running"} == 0
# for: 3m
# labels:
# severity: high
# annotations:
# summary: "Service {{ $labels.exported_name }} down"
# description: "Service {{ $labels.exported_name }} on instance {{ $labels.instance }} has been down for more than 3 minutes."
vim docker-exporter.yaml
groups:
- name: DockerContainer
rules:
- alert: DockerContainerDown
expr: rate(container_last_seen{id=~"/docker/.+"}[5m]) < 0.5
for: 1m
labels:
severity: critical
# Prometheus templates apply here in the annotation and label fields of the alert.
annotations:
description: '服务器: {{ $labels.service_name }}中镜像名为: {{ $labels.image }},容器名: {{ $labels.name }} 挂了'
summary: 'Container {{ $labels.instance }} dow'
vim mysql-rules.yaml
groups:
- name: GaleraAlerts
rules:
- alert: MySQLGaleraNotReady
expr: mysql_global_status_wsrep_ready != 1
for: 5m
labels:
severity: warning
annotations:
description: '{{$labels.job}} on {{$labels.instance}} is not ready.'
summary: Galera cluster node not ready
- alert: MySQLGaleraOutOfSync
expr: (mysql_global_status_wsrep_local_state != 4 and mysql_global_variables_wsrep_desync
== 0)
for: 5m
labels:
severity: warning
annotations:
description: '{{$labels.job}} on {{$labels.instance}} is not in sync ({{$value}}
!= 4).'
summary: Galera cluster node out of sync
- alert: MySQLGaleraDonorFallingBehind
expr: (mysql_global_status_wsrep_local_state == 2 and mysql_global_status_wsrep_local_recv_queue
> 100)
for: 5m
labels:
severity: warning
annotations:
description: '{{$labels.job}} on {{$labels.instance}} is a donor (hotbackup)
and is falling behind (queue size {{$value}}).'
summary: xtradb cluster donor node falling behind
- alert: MySQLReplicationNotRunning
expr: mysql_slave_status_slave_io_running == 0 or mysql_slave_status_slave_sql_running
== 0
for: 2m
labels:
severity: critical
annotations:
description: Slave replication (IO or SQL) has been down for more than 2 minutes.
summary: Slave replication is not running
- alert: MySQLReplicationLag
expr: (mysql_slave_lag_seconds > 30) and on(instance) (predict_linear(mysql_slave_lag_seconds[5m],
60 * 2) > 0)
for: 1m
labels:
severity: critical
annotations:
description: The mysql slave replication has fallen behind and is not recovering
summary: MySQL slave replication is lagging
- alert: MySQLReplicationLag
expr: (mysql_heartbeat_lag_seconds > 30) and on(instance) (predict_linear(mysql_heartbeat_lag_seconds[5m],
60 * 2) > 0)
for: 1m
labels:
severity: critical
annotations:
description: The mysql slave replication has fallen behind and is not recovering
summary: MySQL slave replication is lagging
- alert: MySQLInnoDBLogWaits
expr: rate(mysql_global_status_innodb_log_waits[15m]) > 10
labels:
severity: warning
annotations:
description: The innodb logs are waiting for disk at a rate of {{$value}} /
second
summary: MySQL innodb log writes stalling
### 等等监控规则
创建prometheus
useradd prometheus -s /sbin/nologin -M
chown -R prometheus:prometheus /apps/prometheus
配置启动文件
vim /usr/lib/systemd/system/prometheus.service
[Unit]
Description=prometheus
[Service]
LimitNOFILE=1024000
LimitNPROC=1024000
LimitCORE=infinity
LimitMEMLOCK=infinity
EnvironmentFile=-/apps/prometheus/conf/prometheus
ExecStart=/apps/prometheus/bin/prometheus $PROMETHEUS_OPTS
Restart=on-failure
KillMode=process
User=prometheus
[Install]
WantedBy=multi-user.target
# 启动prometheus
systemctl start prometheus
# 开机启动
systemctl enable prometheus
# 部署consulR 注册监控服务 每个被监控的节点都需部署
cd /apps
chmod +x consulR
mv consulR /tmp
mkdir -p consulR/{bin,conf,logs}
mv /tmp/consulR consulR/bin
# 配置 consulR 注册prometheus 到consul
# 配置说明https://github.com/qist/registy-consul-service/blob/master/conf/consul.yaml
cd consulR/conf
vim prometheus-exporter.yaml
System:
ServiceName: registy-consul-service
ListenAddress: 0.0.0.0
# Port: 9984 # 多exporter 注释掉
FindAddress: 10.8.23.80:80
Logs:
LogFilePath: /apps/consulR/logs/info.log
LogLevel: trace
Consul:
Address: 10.8.23.80:8500,10.8.23.80:8500,10.8.23.80:8500
Token:
CheckHealth: /
CheckType: tcp
CheckTimeout: 5s
CheckInterval: 5s
CheckDeregisterCriticalServiceAfter: false
CheckDeregisterCriticalServiceAfterTime: 30s
Service:
Tag: prometheus-exporter
Address:
Port: 9090
# 注册node-exporter
vim node-exporter.yaml
System:
ServiceName: registy-consul-service
ListenAddress: 0.0.0.0
# Port: 9984
FindAddress: 10.8.23.80:80
Logs:
LogFilePath: /apps/consulR/logs/info.log
LogLevel: trace
Consul:
Address: 10.8.23.80:8500,10.8.23.80:8500,10.8.23.80:8500
Token:
CheckHealth: /
CheckType: tcp
CheckTimeout: 5s
CheckInterval: 5s
CheckDeregisterCriticalServiceAfter: false
CheckDeregisterCriticalServiceAfterTime: 30s
Service:
Tag: node-exporter
Address:
Port: 9100
# 创建启动文件
vim /usr/lib/systemd/system/consulR@.service
[Unit]
Description=ConsulR process %i
[Service]
#LimitNOFILE=1024000
#LimitNPROC=1024000
LimitCORE=infinity
LimitMEMLOCK=infinity
ExecStart=/apps/consulR/bin/consulR -confpath=/apps/consulR/conf/%i.yaml
ProtectHome=true
ProtectSystem=full
PrivateTmp=true
TasksMax=infinity
Restart=on-failure
StartLimitInterval=30min
StartLimitBurst=30
RestartSec=20s
[Install]
WantedBy=multi-user.target
# 启动consulR 并z注册到consul 业务进程必须先启动
systemctl start consulR@node-exporter
systemctl start consulR@prometheus-exporter
# 配置开机启动
systemctl enable consulR@node-exporter
systemctl enable consulR@prometheus-exporter
# 部署alertmanager
cd /apps
tar -xvf alertmanager-0.21.0.linux-amd64.tar.gz
mkdir alertmanager/{bin,conf,data}
mv alertmanager-0.21.0.linux-amd64/* alertmanager/bin
# 创建配置文件
cd alertmanager/conf
vim alertmanager.yml
"global":
"resolve_timeout": "1m"
"route":
"group_by": ["alertname","container_name","namespace","severity","pod_name","instance","service_name","environment"]
"group_wait": "30s"
"group_interval": "30m"
"repeat_interval": "3h"
"receiver": "web.hook"
routes:
- "receiver": "web.hook"
"group_by": ["alertname","container_name","namespace","severity","pod_name","instance","service_name","environment"]
"group_wait": "10s"
"group_interval": "5m"
"repeat_interval": "30m"
match_re:
"severity": "critical"
- "receiver": "web.hook"
"group_by": ["alertname","container_name","namespace","severity","pod_name","instance","service_name","environment"]
"group_wait": "10s"
"group_interval": "30m"
"repeat_interval": "1h"
match_re:
"severity": "high"
"receivers":
- "name": "web.hook"
"webhook_configs":
- "url": "http://xxxxxxx.xxxxx.com/k8smntoauth/api/alert_api/alert/prometheus/" # 专用报警平台,可以参考其它配置 alertmanager
"http_config":
"bearer_token": ""
"inhibit_rules":
- "source_match":
"severity": "critical"
"target_match":
"severity": "warning"
"equal": ["alertname", "dev", "instance"]
# alertmanager 启动配置文件
vim alertmanager
ALERTMANAGER_OPT="--config.file=/apps/alertmanager/conf/alertmanager.yml \
--storage.path=/apps/alertmanager/data \
--data.retention=120h \
--web.listen-address=:9093 \
--web.route-prefix=/"
# 配置alertmanager 启动脚本
vim /usr/lib/systemd/system/alertmanager.service
[Unit]
Description=alertmanager
[Service]
LimitNOFILE=1024000
LimitNPROC=1024000
LimitCORE=infinity
LimitMEMLOCK=infinity
EnvironmentFile=-/apps/alertmanager/conf/alertmanager
ExecStart=/apps/alertmanager/bin/alertmanager $ALERTMANAGER_OPT
Restart=on-failure
KillMode=process
User=prometheus
[Install]
WantedBy=multi-user.target
# 设置运行用户
chown -R prometheus:prometheus /apps/alertmanager
# 启动alertmanager
systemctl start alertmanager
# 开机启动
systemctl enable alertmanager
# 启动的环境参数次二进制方式部署K8S 集群部署使用(kube-prometheus)
# 下载 代码
git clone https://github.com/prometheus-operator/kube-prometheus.git
# 或者 git clone https://github.com/qist/k8s.git
# 主要修改文件 prometheus-prometheus.yaml
apiVersion: monitoring.coreos.com/v1
kind: Prometheus
metadata:
labels:
prometheus: k8s
name: k8s
namespace: monitoring
spec:
alerting:
alertmanagers:
- name: alertmanager-main
namespace: monitoring
port: web
image: quay.io/prometheus/prometheus:v2.22.1
nodeSelector:
kubernetes.io/os: linux
podMonitorNamespaceSelector: {}
podMonitorSelector: {}
replicas: 2
# 取消系统生成 external_labels
replicaExternalLabelName: ""
prometheusExternalLabelName: ""
# 配置外部标签多环境报警使用
externalLabels:
environment: k8s # 环境env 必须修改
#secrets: # 添加etcd 跟istio https 监控请取消注释
#- etcd-certs
#- istio-certs
#configMaps: # 添加blackbox-exporter 站点批量监控
#- prometheus-files-discover
resources:
requests:
memory: 4096Mi
retention: 2d
#storage: #使用外部存储 请取消注释
# volumeClaimTemplate:
# spec:
# accessModes:
# - ReadWriteOnce
# resources:
# requests:
# storage: 50Gi
# storageClassName: alicloud-disk-ssd
# volumeMode: Filesystem
ruleSelector:
matchLabels:
prometheus: k8s
role: alert-rules
additionalScrapeConfigs:
name: additional-configs
key: prometheus-additional.yaml # 参数 qist 仓库 k8s/k8s-yaml/kube-prometheus/prometheus
securityContext:
fsGroup: 2000
runAsNonRoot: true
runAsUser: 1000
serviceAccountName: prometheus-k8s
serviceMonitorNamespaceSelector: {}
serviceMonitorSelector: {}
version: v2.22.1
# 其它直接 应用
kubectl apply -f setup/.
kubectl apply -f .部署victoriametrics
# 为啥使用victoriametrics victoriametrics 存储空间压缩的很小 prometheus 占用空间很大
# prometheus 联邦集群一天产生几百GB 的监控数据
# victoriametrics 每天产生几G的监控数据压缩的很小 victoriametrics 配置可以自己刷新
# 可以使用prometheus remote_write 方案跟prometheus 联邦集群方案 这里选择 prometheus 联邦集群方案 remote_write 方案在victoriametrics 重启会占用大量的带宽,所以这里我选择prometheus 联邦集群方案 抓取federate
# prometheus remote_write 写法
remote_write:
- url: http://192.168.2.220:8428/api/v1/write
remote_timeout: 30s
queue_config:
capacity: 20000
max_shards: 50
min_shards: 1
max_samples_per_send: 10000
batch_send_deadline: 60s
min_backoff: 30ms
max_backoff: 100ms
# K8S 集群 prometheus-prometheus.yaml 添加
remoteWrite:
- url: http://192.168.2.220:8428/api/v1/write
batchSendDeadline: 60s
capacity: 20000
maxBackoff: 100ms
maxSamplesPerSend: 10000
maxShards: 50
minBackoff: 30ms
minShards: 1
# victoriametrics 兼容prometheus 配置
# 节点192.168.2.220
# 下载 victoriametrics 可选集群版本跟单机版本这里我选择单机版本
cd /apps
wget https://github.com/VictoriaMetrics/VictoriaMetrics/releases/download/v1.50.2/victoria-metrics-v1.50.2.tar.gz
tar -xvf victoria-metrics-v1.50.2.tar.gz
# 创建运行目录
mkdir -p victoriametrics/{bin,conf,data}
mv victoria-metrics-prod victoriametrics/bin/
# 创建配置文件
cd victoriametrics/conf
vim prometheus.yml
# my global config
global:
scrape_interval: 15s # Set the scrape interval to every 15 seconds. Default is every 1 minute.
evaluation_interval: 15s # Evaluate rules every 15 seconds. The default is every 1 minute.
# scrape_timeout is set to the global default (10s).
# Alertmanager configuration
alerting:
alertmanagers:
- static_configs:
- targets:
# - alertmanager:9093
# Load rules once and periodically evaluate them according to the global 'evaluation_interval'.
rule_files:
# - "first_rules.yml"
# - "second_rules.yml"
# A scrape configuration containing exactly one endpoint to scrape:
# Here it's Prometheus itself.
scrape_configs:
# The job name is added as a label `job=<job_name>` to any timeseries scraped from this config.
- job_name: 'victoriametrics'
# metrics_path defaults to '/metrics'
# scheme defaults to 'http'.
static_configs:
- targets: ['localhost:8428'] # 静态监控
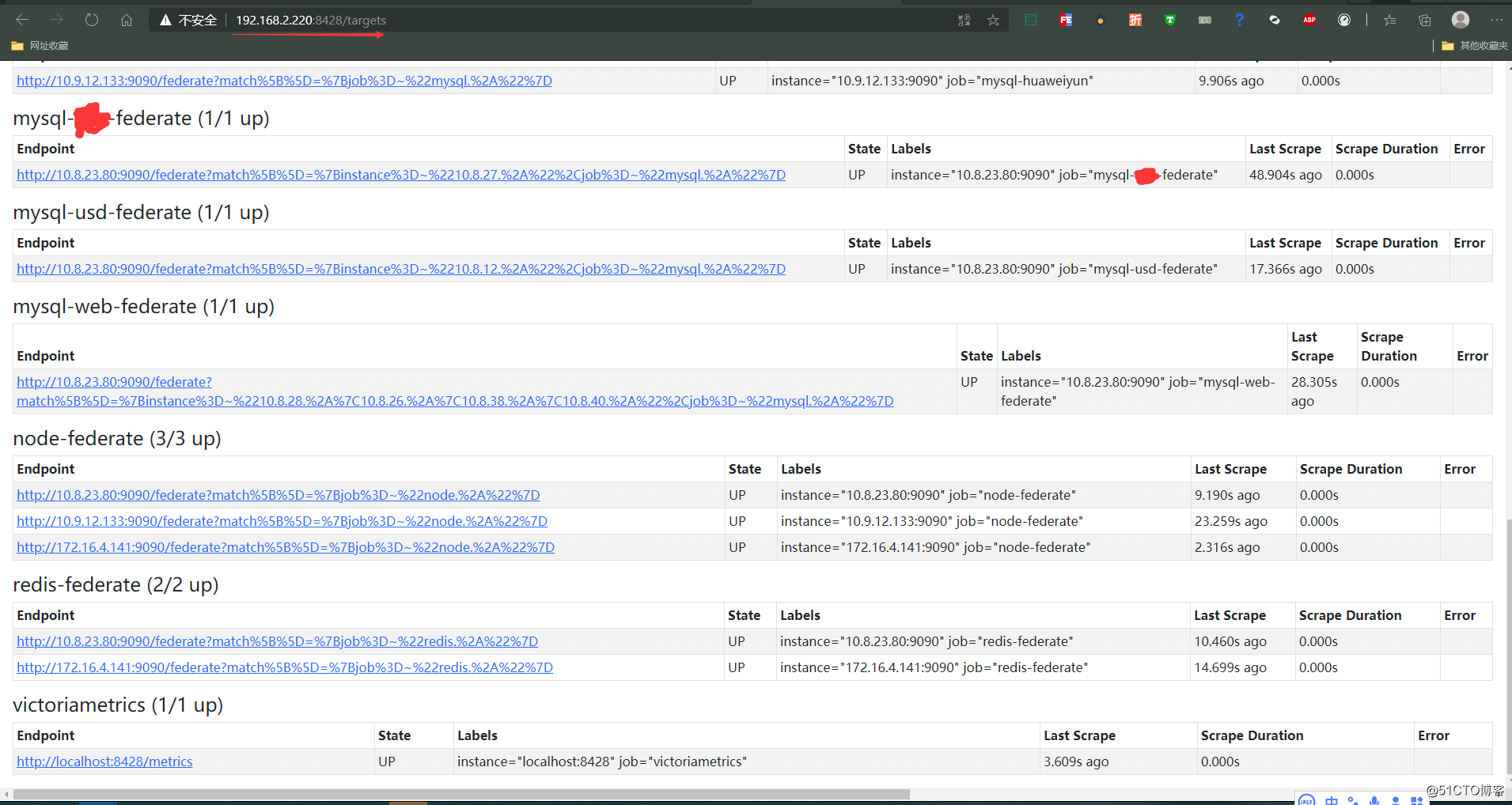
- job_name: 'federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
#- '{job=~"prometheus.*"}'
- '{environment=~".*"}' # 拉取所有environment
static_configs:
- targets:
- '192.168.201.62:9090' # ack service IP
- '172.100.41.118:9090' # 办公idc K8S service IP
- job_name: 'aliyun-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"prometheus.*"}' # 基于job 模式拉取
- '{job=~"aliyun.*"}'
- '{job=~"windows.*"}'
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- job_name: 'huaweiyun-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"huaweiyun.*"}' # 基于job 模式拉取
- '{job=~"prometheus.*"}'
static_configs:
- targets:
- '10.9.12.133:9090'
- job_name: 'redis-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
# - '{job=~"mysql.*"}'
- '{job=~"redis.*"}' # 基于job 模式拉取
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- job_name: 'mysql-ddd-federate'
scrape_interval: 60s
scrape_timeout: 60s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{instance=~"10.8.27.*",job=~"mysql.*"}' # 基于ip 地址+job 拉取监控数据量很大这样分区
static_configs:
- targets:
- '10.8.23.80:9090'
- job_name: 'mysql-usd-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{instance=~"10.8.12.*",job=~"mysql.*"}' # 基于ip 地址+job 拉取监控数据量很大这样分区
static_configs:
- targets:
- '10.8.23.80:9090'
- job_name: 'mysql-web-federate'
scrape_interval: 60s
scrape_timeout: 60s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{instance=~"10.8.28.*|10.8.26.*|10.8.38.*|10.8.40.*",job=~"mysql.*"}' # 基于ip 地址+job 拉取监控数据量很大这样分区
static_configs:
- targets:
- '10.8.23.80:9090'
- job_name: 'mysql-bs-federate'
scrape_interval: 60s
scrape_timeout: 60s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"mysql.*"}'
static_configs:
- targets:
- '172.16.4.141:9090'
- job_name: 'mysql-huaweiyun'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"mysql.*"}' # 基于job 模式拉取
static_configs:
- targets:
- '10.9.12.133:9090'
- job_name: 'docker-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"alertmanager.*"}' # 基于job 模式拉取
- '{job=~"consul.*"}'
- '{job=~"docker.*"}'
- '{job=~"elasticsearch.*"}'
- '{job=~"haproxy.*"}'
- '{job=~"nginx-vts.*"}'
- '{job=~"rabbitmq.*"}'
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- '10.9.12.133:9090'
- job_name: 'node-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"node.*"}' # 基于job 模式拉取
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- '10.9.12.133:9090'
- job_name: 'dns-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"coredns.*"}' # 基于job 模式拉取
- '{job=~"online.*"}'
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- '10.9.12.133:9090'
- job_name: 'blackbox-federate'
scrape_interval: 30s
scrape_timeout: 30s
honor_labels: true
metrics_path: '/federate'
params:
'match[]':
- '{job=~"blackbox-.*"}' # 基于job 模式拉取
static_configs:
- targets:
- '10.8.23.80:9090'
- '172.16.4.141:9090'
- '10.9.12.133:9090'
# 配置 victoriametrics 启动参数
vim victoriametrics
VICTORIAMETRICS_OPT="-http.connTimeout=5m \
-influx.maxLineSize=100MB \
-import.maxLineLen=100MB \
-maxConcurrentInserts=20000 \
-maxInsertRequestSize=100MB \
-maxLabelsPerTimeseries=200 \
-insert.maxQueueDuration=5m \
-dedup.minScrapeInterval=60s \
-bigMergeConcurrency=20 \
-retentionPeriod=180d \
-search.maxQueryDuration=10m \
-search.maxQueryLen=30MB \
-search.maxQueueDuration=60s \
-search.maxConcurrentRequests=32 \
-storageDataPath=/apps/victoriametrics/data \
-promscrape.streamParse=true \
-promscrape.config=/apps/victoriametrics/conf/prometheus.yml \
-promscrape.configCheckInterval=30s \
-promscrape.consulSDCheckInterval=30s \
-promscrape.discovery.concurrency=2000 \
-promscrape.fileSDCheckInterval=30s \
-promscrape.maxScrapeSize=100MB \
"
# 配置启动文件
vim /usr/lib/systemd/system/victoriametrics.service
[Unit]
Description=victoriametrics
[Service]
LimitNOFILE=1024000
LimitNPROC=1024000
LimitCORE=infinity
LimitMEMLOCK=infinity
EnvironmentFile=-/apps/victoriametrics/conf/victoriametrics
ExecStart=/apps/victoriametrics/bin/victoria-metrics-prod $VICTORIAMETRICS_OPT
Restart=on-failure
KillMode=process
[Install]
WantedBy=multi-user.target
# 启动
service victoriametrics start
# 开机启动
chkconfig victoriametrics on部署grafana
# 使用二进制或者K8S 模式部署 我这里以前使用K8S 不是了grafana 不想再去从新部署所以 就修改了数据源
# 参考下面url 记得添加外部存储
https://github.com/qist/k8s/tree/master/k8s-yaml/kube-prometheus/grafana
# environment-dashboards 目录为多环境dashboards
# 使用 import-dashboards.sh 导入即可
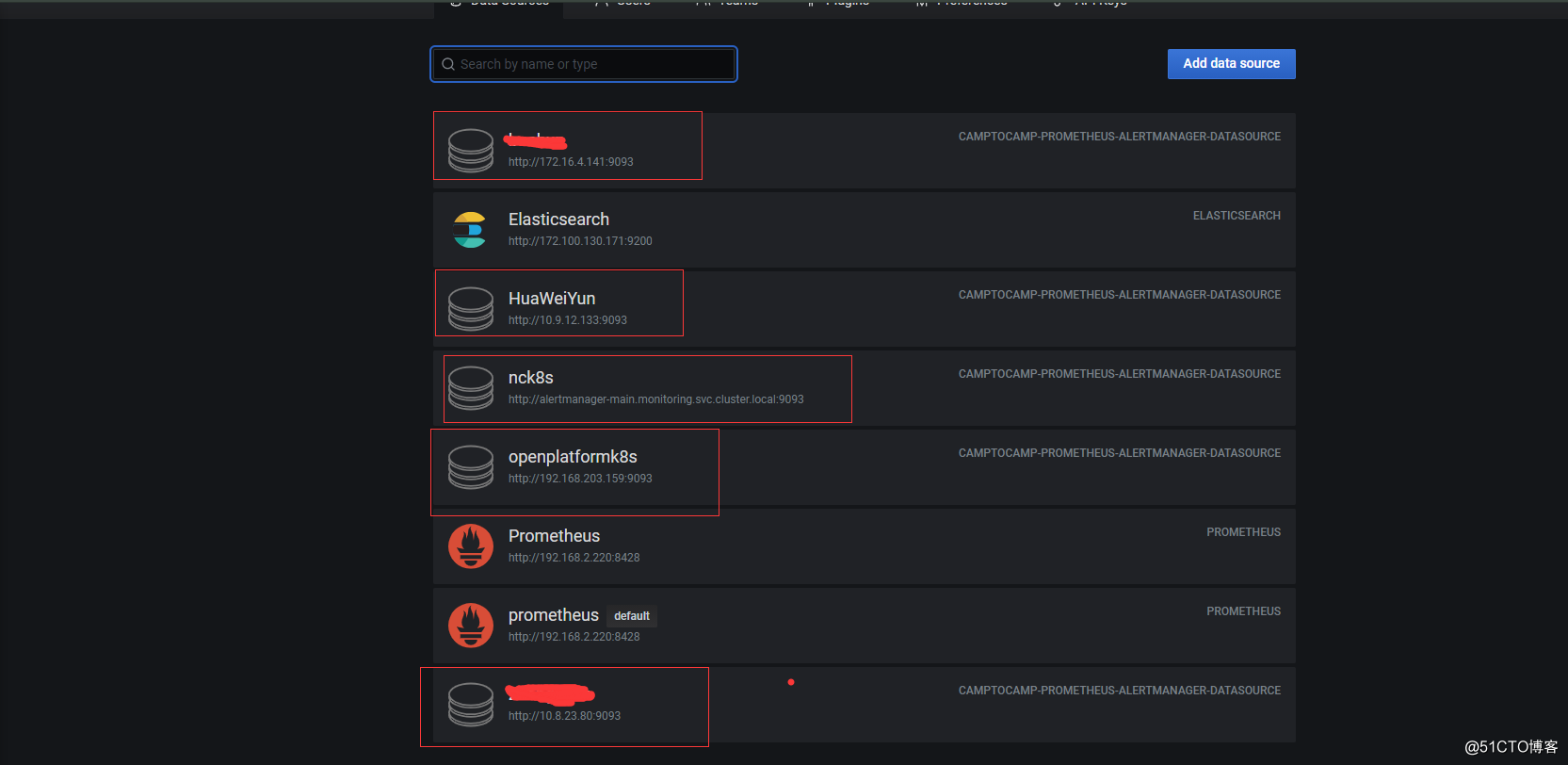
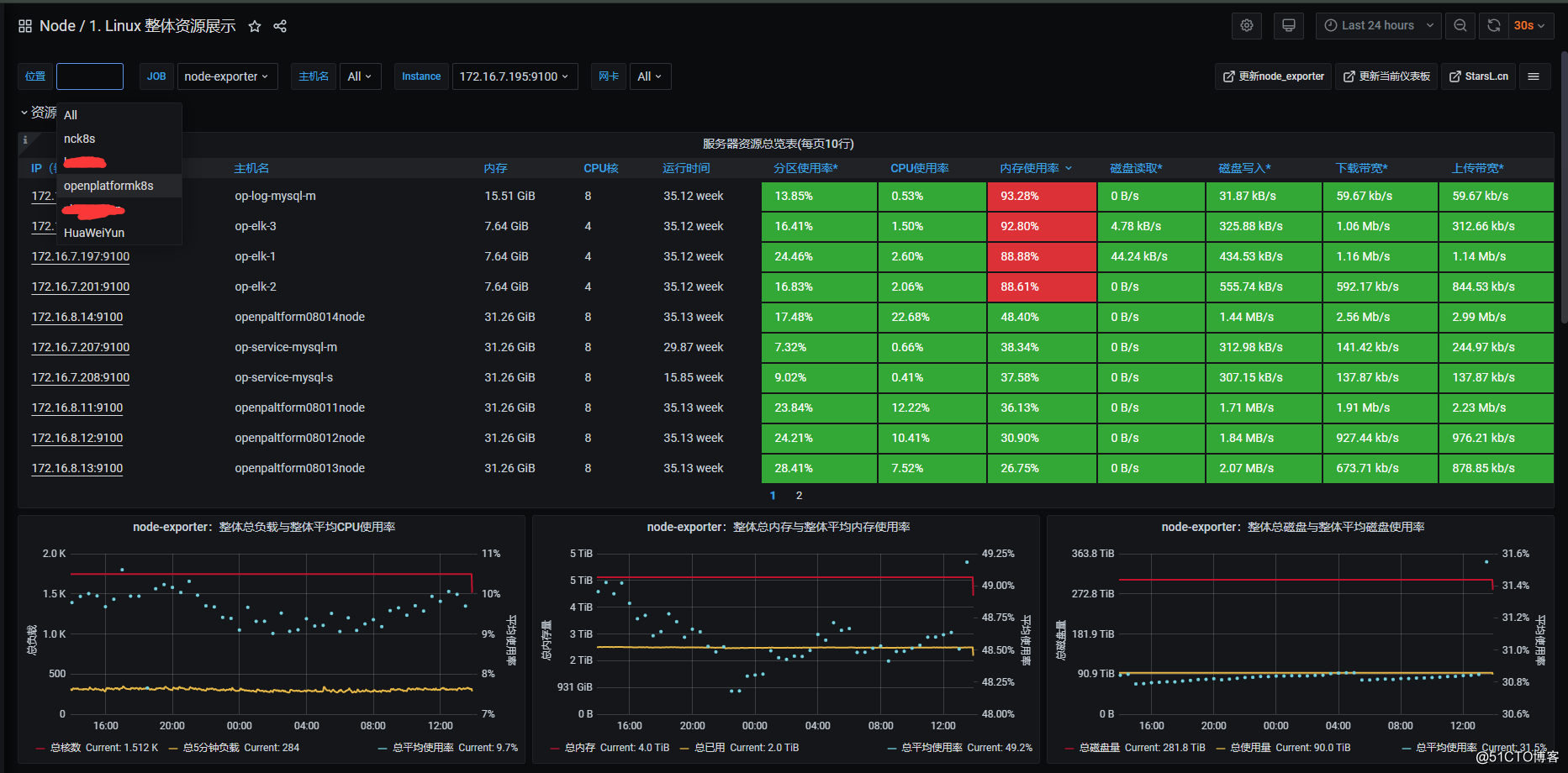
# grafana 数据源 选择prometheus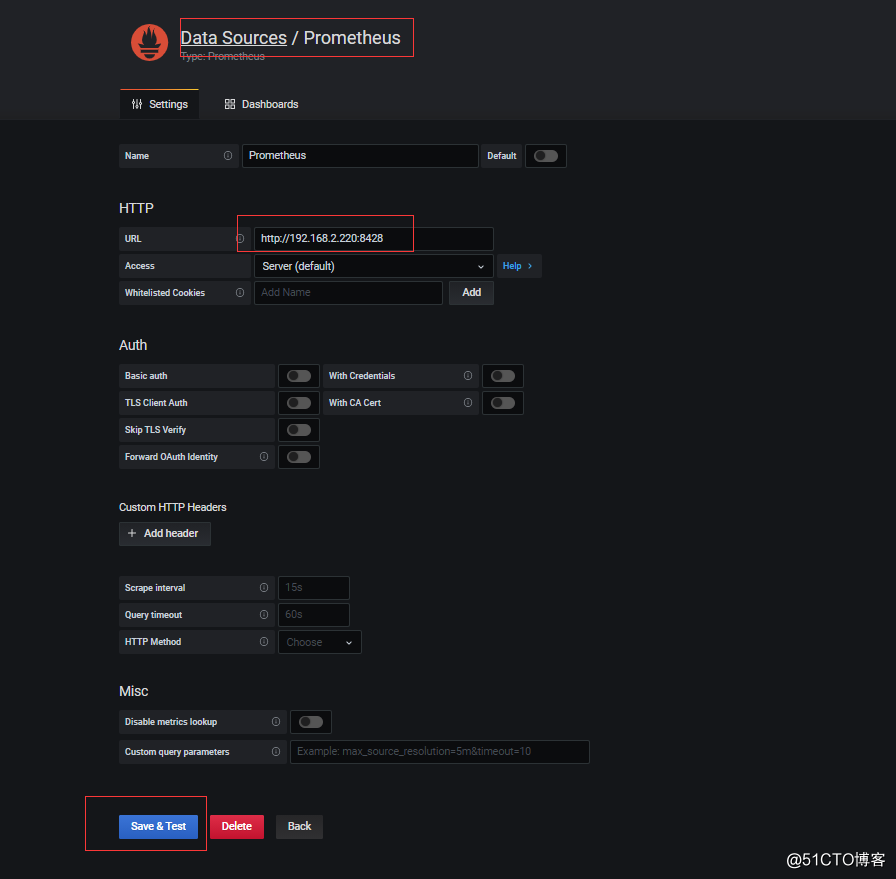
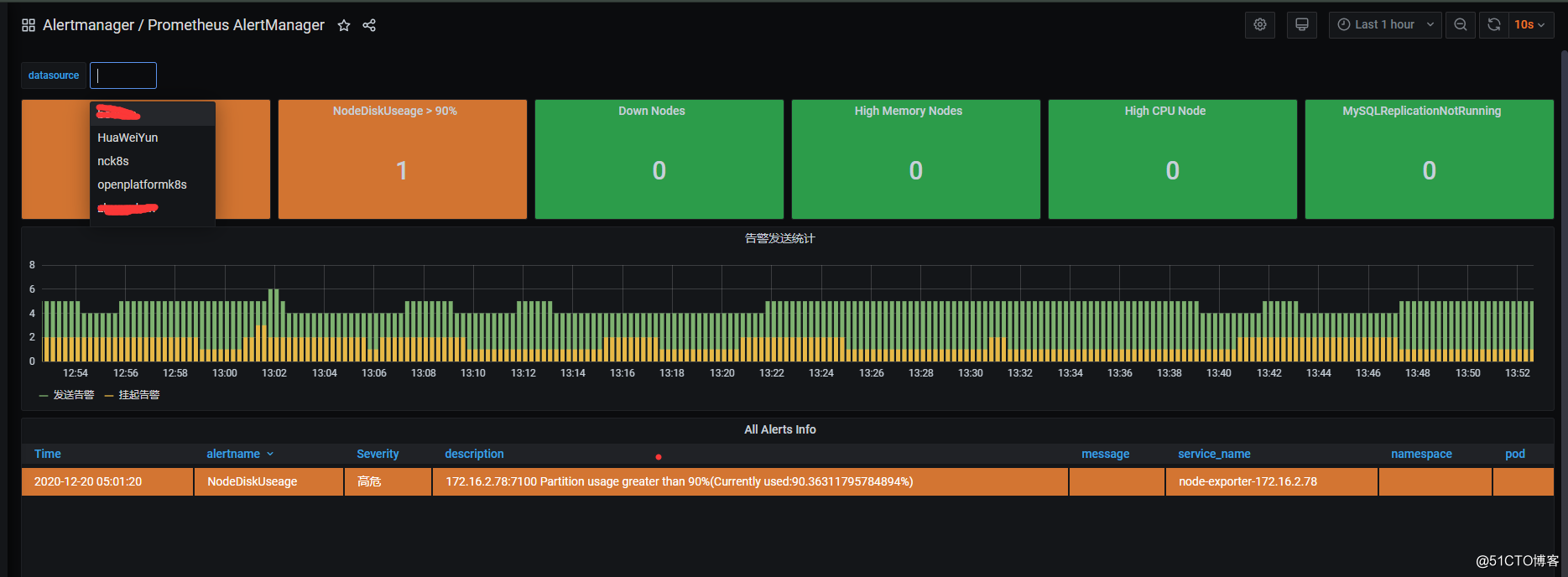
prometheus-alertmanager 多环境配置