简单的文件上传
一、准备文件上传的条件:
1、安装nodejs环境
2、安装vue环境
3、验证环境是否安装成功
二、实现上传步骤
1、前端部分使用 vue-cli 脚手架,搭建一个 demo 版本,能够实现简单交互:
<template> <div id="app"> <input type="file" @change="uploadFile"></button> </div> </template>
2、安装 axios 实现与后端交互:
import Axios from 'axios' const Server = Axios.create({ baseURL: '/api' }) export default Server
3、后端使用 node-koa 框架:
// index.js const Koa = require('koa'); const router = require('koa-router')() // koa路由组件 const fs = require('fs') // 文件组件 const path = require('path') // 路径组件 const koaBody = require('koa-body') //解析上传文件的插件 const static = require('koa-static') // 访问服务器静态资源组件 const uploadPath = path.join(__dirname, 'public/uploads') // 文件上传目录 const app = new Koa(); // 实例化 koa // 定义静态资源访问规则 app.use(static('public', { maxAge: 30 * 24 * 3600 * 1000 // 静态资源缓存时间 ms })) app.use(koaBody({ multipart: true, formidable: {
uploadDir: uploadPath, maxFileSize: 10000 * 1024 * 1024 // 设置上传文件大小最大限制,默认20M } })) // 对于任何请求,app将调用该异步函数处理请求: app.use(async (ctx, next) => { console.log(`Process ${ctx.request.method} ${ctx.request.url}...`); ctx.set('Access-Control-Allow-Origin', '*');//*表示可以跨域任何域名都行 也可以填域名表示只接受某个域名 ctx.set('Access-Control-Allow-Headers', 'X-Requested-With,Content-Type,token');//可以支持的消息首部列表 ctx.set('Access-Control-Allow-Methods', 'PUT,POST,GET,DELETE,OPTIONS');//可以支持的提交方式 ctx.set('Content-Type', 'application/json;charset=utf-8');//请求头中定义的类型 if (ctx.request.method === 'OPTIONS') { ctx.response.status = 200 } try { await next(); } catch (err) { console.log(err, 'errmessage') ctx.response.status = err.statusCode || err.status || 500 ctx.response.body = { errcode: 500, msg: err.message } ctx.app.emit('error', err, ctx); } })
4、前端实现上传请求:
// vue export default { name: 'App', methods: { uploadFile(e) { const file = e.target.files[0] this.sendFile(file) }, sendFile(file) { let formdata = new FormData() formdata.append("file", file) this.$http({ url: "/upload/file", method: "post", data: formdata, headers: { "Content-Type": "multipart/form-data" } }).then(({ data }) => { console.log(data, 'upload/file') }) } } }
5、node 接收文件接口:
router.post('/api/upload/file', function uploadFile(ctx) {
const files = ctx.request.files
const filePath = path.join(uploadPath, files.file.name)
// 创建可读流
const reader = fs.createReadStream(files['file']['path']);
// 创建可写流
const upStream = fs.createWriteStream(filePath);
// 可读流通过管道写入可写流
reader.pipe(upStream);
ctx.response.body = {
code: 0,
url: path.join('http://localhost:3000/uploads', files.file.name),
msg: '文件上传成功'
}
})
以上全部过程就实现了一个简单的文件上传功能。

这种实现方式上传功能对于小文件来说没什么问题,但当需求中碰到大文件的时候,能解决上传中遇到的各种问题,比如网速不好时、上传速度慢、断网情况、暂停上传、重复上传等问题。想要解决以上问题则需要优化前面的逻辑。
分片上传
1、分片逻辑如下:
- 由于前端已有 Blob Api 能操作文件二进制,因此最核心逻辑就是前端运用 Blob Api 对大文件进行文件分片切割,将一个大文件切成一个个小文件,然后将这些分片文件一个个上传。
- 现在的 http 请求基本是 1.1 版本,浏览器能够同时进行多个请求,这将用到一个叫 js 异步并发控制的处理逻辑。
- 当前端将所有分片上传完成之后,前端再通知后端进行分片合并成文件。
2、在进行文件分片处理之前,先介绍下 js 异步并发控制:
function sendRequest(arr, max = 6, callback) { let i = 0 // 数组下标 let fetchArr = [] // 正在执行的请求 let toFetch = () => { // 如果异步任务都已开始执行,剩最后一组,则结束并发控制 if (i === arr.length) { return Promise.resolve() } // 执行异步任务 let it = fetch(arr[i++]) // 添加异步事件的完成处理 it.then(() => { fetchArr.splice(fetchArr.indexOf(it), 1) }) fetchArr.push(it) let p = Promise.resolve() // 如果并发数达到最大数,则等其中一个异步任务完成再添加 if (fetchArr.length >= max) { p = Promise.race(fetchArr) } // 执行递归 return p.then(() => toFetch()) } toFetch().then(() => // 最后一组全部执行完再执行回调函数 Promise.all(fetchArr).then(() => { callback() }) ) }
js 异步并发控制的逻辑是:运用 Promise 功能,定义一个数组 fetchArr,每执行一个异步处理往 fetchArr 添加一个异步任务,当异步操作完成之后,则将当前异步任务从 fetchArr 删除,则当异步 fetchArr 数量没有达到最大数的时候,就一直往 fetchArr 添加,如果达到最大数量的时候,运用 Promise.race Api,每完成一个异步任务就再添加一个,当所有最后一个异步任务放进了 fetchArr 的时候,则执行 Promise.all,等全部完成之后则执行回调函数。
上面这逻辑刚好适合大文件分片上传场景,将所有分片上传完成之后,执行回调请求后端合并分片。
前端改造:
1、定义一些全局参数:
export default { name: 'App', data() { return { remainChunks: [], // 剩余切片 isStop: false, // 暂停上传控制 precent: 0, // 上传百分比 uploadedChunkSize: 0, // 已完成上传的切片数 chunkSize: 2 * 1024 * 1024 // 切片大小 } } }
2、文件分割方法:
cutBlob(file) { const chunkArr = [] // 所有切片缓存数组 const blobSlice = File.prototype.slice || File.prototype.mozSlice || File.prototype.webkitSlice // 切割Api不同浏览器分割处理 const spark = new SparkMD5.ArrayBuffer() // 文件hash处理 const chunkNums = Math.ceil(file.size / this.chunkSize) // 切片总数 return new Promise((resolve, reject) => { const reader = new FileReader() reader.readAsArrayBuffer(file) reader.addEventListener('loadend', () => { const content = reader.result // 生成文件hash spark.append(content) const hash = spark.end() let startIndex = '' let endIndex = '' let contentItem = '' // 文件切割 for(let i = 0; i < chunkNums; i++) { startIndex = i * this.chunkSize endIndex = startIndex + this.chunkSize endIndex > file.size && (endIndex = file.size) contentItem = blobSlice.call(file, startIndex, endIndex) chunkArr.push({ index: i, hash, total: chunkNums, name: file.name, size: file.size, chunk: contentItem }) } resolve({ chunkArr, fileInfo: { hash, name: file.name, size: file.size } }) }) reader.addEventListener('error', function _error(err) { reject(err) }) }) }
以上方式的处理逻辑:定义一个切片缓存数组,当文件进行分片之后,将缓存所有的分片信息、根据最大分片大小计算分片数量、计算整个文件的 hash (spark-md5) 值,这将意味着,只要文件内容不变,这 hash 值也将不变,这涉及到后面的秒传功能、然后进行文件分片。
3、改造上传方法:
async uploadFile(e) { const file = e.target.files[0] this.precent = 0 this.uploadedChunkSize = 0 // 如果文件大于分片大小5倍,则进行分片上传 if (file.size < this.chunkSize * 5) { this.sendFile(file) } else { const chunkInfo = await this.cutBlob(file) this.remainChunks = chunkInfo.chunkArr this.fileInfo = chunkInfo.fileInfo this.mergeRequest() } }
注意:以上代码中设置当文件大小大于分片大小的5倍进行分片上传。
4、定义分片上传请求(sendRequest)和合并请求(chunkMerge):
mergeRequest() { const chunks = this.remainChunks const fileInfo = this.fileInfo this.sendRequest(chunks, 6, () => { // 请求合并 this.chunkMerge(fileInfo) }) }
5、分片请求将结合上面提到的 JS 异步并发控制:
sendRequest(arr, max = 6, callback) { let fetchArr = [] let toFetch = () => { if (this.isStop) { return Promise.reject('暂停上传') } if (!arr.length) { return Promise.resolve() } const chunkItem = arr.shift() const it = this.sendChunk(chunkItem) it.then(() => { fetchArr.splice(fetchArr.indexOf(it), 1) }, err => { this.isStop = true arr.unshift(chunkItem) Promise.reject(err) }) fetchArr.push(it) let p = Promise.resolve() if (fetchArr.length >= max) { p = Promise.race(fetchArr) } return p.then(() => toFetch()) } toFetch().then(() => { Promise.all(fetchArr).then(() => { callback() }) }, err => { console.log(err) }) }
6、切片上传请求:
sendChunk(item) { let formdata = new FormData() formdata.append("file", item.chunk) formdata.append("hash", item.hash) formdata.append("index", item.index) formdata.append("name", item.name) return this.$http({ url: "/upload/snippet", method: "post", data: formdata, headers: { "Content-Type": "multipart/form-data" }, onUploadProgress: (e) => { const { loaded, total } = e this.uploadedChunkSize += loaded < total ? 0 : +loaded this.uploadedChunkSize > item.size && (this.uploadedChunkSize = item.size) this.precent = (this.uploadedChunkSize / item.size).toFixed(2) * 1000 / 10 } }) }
7、切片合并请求:
chunkMerge(data) { this.$http({ url: "/upload/merge", method: "post", data, }).then(res => { console.log(res.data) }) }
前端处理文件分片逻辑代码已完成
后端处理
后端部分就只新增两个接口:分片上传请求和分片合并请求:
1、分片上传请求:
router.post('/api/upload/snippet', function snippet(ctx) {
let files = ctx.request.files
const { index, hash } = ctx.request.body
// 切片上传目录
const chunksPath = path.join(uploadPath, hash, '/')
// 切片文件
const chunksFileName = chunksPath + hash + '-' + index
if(!fs.existsSync(chunksPath)) {
fs.mkdirSync(chunksPath)
}
// 秒传,如果切片已上传,则立即返回
if (fs.existsSync(chunksFileName)) {
ctx.response.body = {
code: 0,
msg: '切片上传完成'
}
return
}
// 创建可读流
const reader = fs.createReadStream(files.file.path);
// 创建可写流
const upStream = fs.createWriteStream(chunksFileName);
// // 可读流通过管道写入可写流
reader.pipe(upStream);
reader.on('end', () => {
// 文件上传成功后,删除本地切片文件
fs.unlinkSync(files.file.path)
})
ctx.response.body = {
code: 0,
msg: '切片上传完成'
}
})
2、分片合并请求:
/** * 1、判断是否有切片hash文件夹 * 2、判断文件夹内的文件数量是否等于total * 4、然后合并切片 * 5、删除切片文件信息 */ router.post('/api/upload/merge', function uploadFile(ctx) { const { total, hash, name } = ctx.request.body const dirPath = path.join(uploadPath, hash, '/') const filePath = path.join(uploadPath, name) // 合并文件 // 已存在文件,则表示已上传成功 if (fs.existsSync(filePath)) { ctx.response.body = { code: 0, url: path.join('http://localhost:3000/uploads', name), msg: '文件上传成功' } // 如果没有切片hash文件夹则表明上传失败 } else if (!fs.existsSync(dirPath)) { ctx.response.body = { code: -1, msg: '文件上传失败' } } else { const chunks = fs.readdirSync(dirPath) // 读取所有切片文件 const fileWriteStream = fs.createWriteStream(filePath) // 创建可写存储文件 if(chunks.length !== total || !chunks.length) { ctx.response.body = { code: -1, msg: '上传失败,切片数量不符' } } for(let i = 0; i < chunks.length; i++) { // 将切片追加到存储文件 fs.appendFileSync(filePath, fs.readFileSync(dirPath + hash + '-' + i)) // 然后删除切片 fs.unlinkSync(dirPath + hash + '-' + i) } // 然后再删除切片文件夹 fs.rmdirSync(dirPath) // 默认情况下不需要手动关闭,但是在某些文件的合并并不会自动关闭可写流,比如压缩文件,所以这里在合并完成之后,统一关闭下 fileWriteStream.close() // 合并文件成功 ctx.response.body = { code: 0, url: path.join('http://localhost:3000/uploads', name), msg: '文件上传成功' } } })
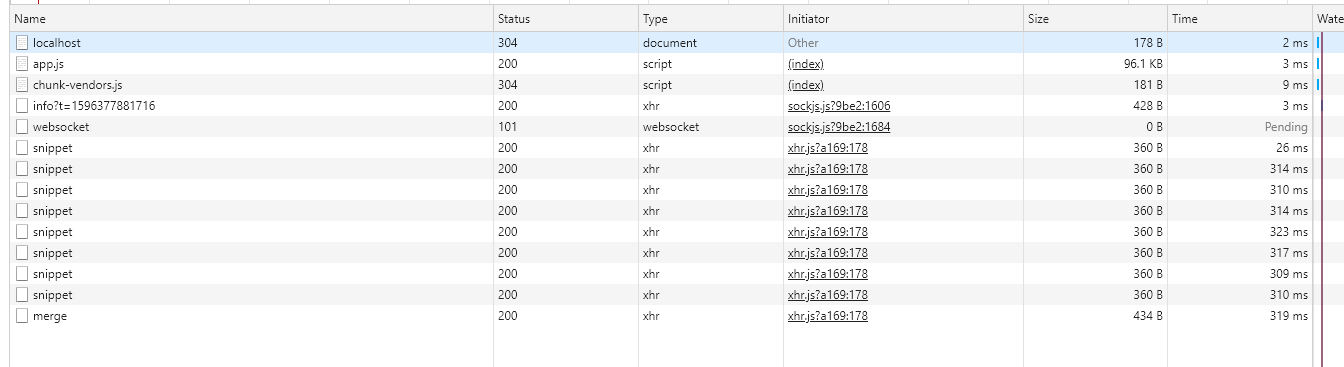
切片上传成功与文件合并截图:

其它
1、前端暂停,续传功能:
<template> <div id="app"> <input type="file" @change="uploadFile">{{ precent }}% <button type="button" v-if="!isStop" @click="stopUpload">暂停</button> <button type="button" v-else @click="reupload">继续上传</button> </div> </template>
2、js 新增主动暂停和续传方法,比较简单,这里没有做停止正在执行的请求:
stopUpload() { this.isStop = true }, reupload() { this.isStop = false this.mergeRequest() }
前端大文件的分片上传就差不多了。还可以优化的一点,在进行文件 hash 求值的时候,大文件的 hash 计算会比较慢,这里可以加上 html5 的新特性,用 Web Worker 新开一个线程进行 hash 计算。