公司要开搞大数据了,针对大数据的一般姿势做了个简单调研。
一、通用架构
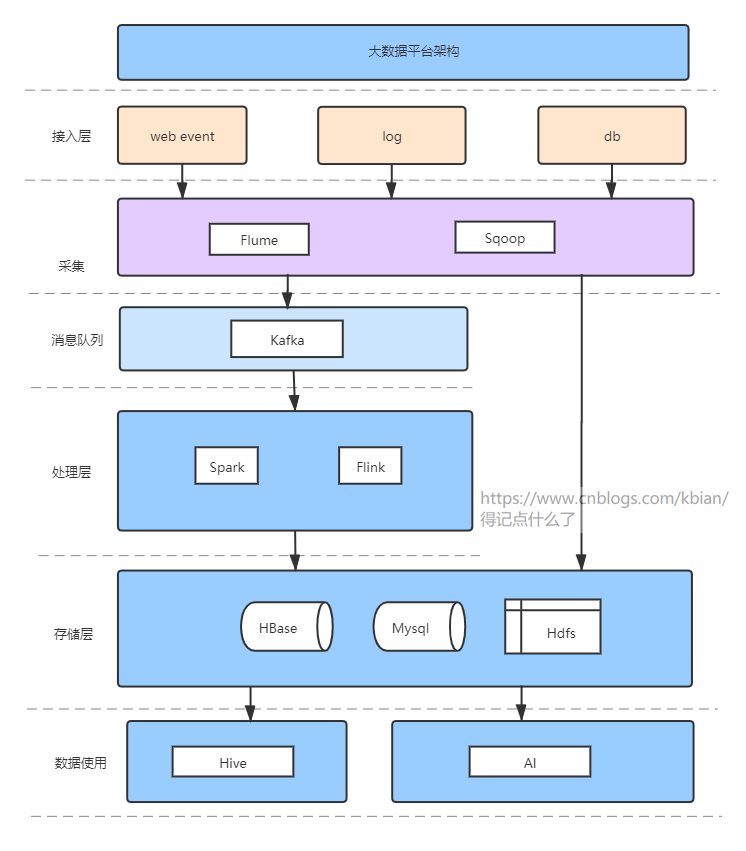
二、组件选择
1、Hdfs、HBase
Hdfs:分布式文件存储,无缝对接所有大数据相关组件。高容错(多副本)、高吞吐。适合一次写入,多次读出。不适合低延迟读取、小文件存储(寻址时间超过读取时间)。
HBase:非关系型分布式数据库,基于Hdfs,高容错、高吞吐。HBase采用的是Key/Value的存储方式,即使随着数据量增大,也几乎不会导致查询的性能下降。
2、Flume、Sqoop
Flume:最主要的作用就是,实时读取服务器本地磁盘的数据,将数据写入到HDFS/Kafka/HBase。
Sqoop:用来在RDBMS和Hadoop之间进行数据传输的工具就是我们所说的Sqoop。在这里,RDBMS指的是MySQL,Oracle SQL等,而Hadoop指的是Hive,HDFS和HBase等。 我们使用Sqoop将数据从RDBMS导入Hadoop,也可用于将数据从Hadoop导出到RDBMS
3、Kafaka
高并发的基石。吞吐量远远领先于同类别的MQ。
LinkedIn团队做了个实验研究,对比Kafka与Apache ActiveMQ V5.4和RabbitMQ V2.4的性能
生产者 消费者


4、MapReduce & Hive & Spark & Flink & Beam
4.1、演变史

4.2、MapReduce 到 Hive 到 SparkSQL的演变

4.3、MapReduce 、 Spark 、Flink
MapReduce

Spark


MapReduce:
MapReduce 模型的抽象层次低,大量的底层逻辑都需要开发者手工完成。
只提供 Map 和 Reduce 两个操作。比如两个数据集的 Join 是很基本而且常用的功能,但是在 MapReduce 的世界中,需要对这两个数据集做一次 Map 和 Reduce 才能得到结果。
在 Hadoop 中,每一个 Job 的计算结果都会存储在 HDFS 文件存储系统中,所以每一步计算都要进行硬盘的读取和写入,大大增加了系统的延迟。
Spark:
Spark 最基本的数据抽象叫作弹性分布式数据集(Resilient Distributed Dataset, RDD),它代表一个可以被分区(partition)的只读数据集,它内部可以有很多分区,每个分区又有大量的数据记录(record)。
RDD 是 Spark 最基本的数据结构。Spark 定义了很多对 RDD 的操作。如 Map、Filter、flatMap、groupByKey 和 Union 等等,极大地提升了对各种复杂场景的支持。
相对于 Hadoop 的 MapReduce 会将中间数据存放到硬盘中,Spark 会把中间数据缓存在内存中,从而减少了很多由于硬盘读写而导致的延迟,大大加快了处理速度。
Flink
在 Flink 中,程序天生是并行和分布式的。一个 Stream 可以包含多个分区(Stream Partitions),一个操作符可以被分成多个操作符子任务,每一个子任务是在不同的线程或者不同的机器节点中独立执行的。
性能对比

可以看出,Hadoop 做每一次迭代运算的时间基本相同,而 Spark 除了第一次载入数据到内存以外,别的迭代时间基本可以忽略。
4.4、几种处理引擎对比
| API | 类SQL | 性能 | 容错性 | 实时性 | 批处理 | 流处理 | Exactly once语义 | 社区活跃度 | |
|---|---|---|---|---|---|---|---|---|---|
| MapReduce | 复杂 | 没有 | 低 | 低 | 低 | 中 | 不支持 | 无 | 低 |
| Hive | 简单 | 有 | 低 | 高 | 低 | 中 | 不支持 | 无 | 中 |
| Spark | 简单 | 有 | 高 | 高 | 中高(秒级) | 高 | 中 | 支持 | 高 |
| Flink | 简单 | 有 | 高 | 高 | 高(微妙级) | 中 | 高 | 支持 | 中 |
| Beam | 或者代表着未来。目前在谷歌内部使用、生态还没发展起来。拭目以待 | ||||||||
附1:
在流处理系统中,我们对应数据记录的处理,有3种级别的语义定义,以此来衡量这个流处理系统的能力。
- At most once(最多一次)。每条数据记录最多被处理一次,潜台词也表明数据会有丢失(没被处理掉)的可能。
- At least once(最少一次)。每条数据记录至少被处理一次。这个比上一点强的地方在于这里至少保证数据不会丢,至少被处理过,唯一不足之处在于数据可能会被重复处理。
- Exactly once(恰好一次)。每条数据记录正好被处理一次。没有数据丢失,也没有重复的数据处理。这一点是3个语义里要求最高的。
4.5、使用场景
MapReduce:仅仅用来学习,理解大数据的原理。
Hive:类SQL引擎,适合做报表分析
Spark: Spark 存在的一个缺点——无法高效应对低延迟的流处理场景入手。对于以下场景,你可以选择 Spark。
- 数据量非常大而且逻辑复杂的批数据处理,并且对计算效率有较高要求(比如用大数据分析来构建推荐系统进行个性化推荐、广告定点投放等);
- 基于历史数据的交互式查询,要求响应较快;
- 基于实时数据流的数据处理,延迟性要求在在数百毫秒到数秒之间。
Spark 完美满足这些场景的需求, 而且它可以一站式解决这些问题,无需用别的数据处理平台。
Flink:由于 Flink 是为了提升流处理而创建的平台,所以它适用于各种需要非常低延迟(微秒到毫秒级)的实时数据处理场景,比如实时日志报表分析。
而且 Flink 用流处理去模拟批处理的思想,比 Spark 用批处理去模拟流处理的思想扩展性更好,所以我相信将来 Flink 会发展的越来越好,
生态和社区各方面追上 Spark。比如,阿里巴巴就基于 Flink 构建了公司范围内全平台使用的数据处理平台 Blink,美团、饿了么等公司也都接受 Flink 作为数据处理解决方案。
可以说,Spark 和 Flink 都在某种程度上统一了批处理和流处理。
三、任务分工
