Hadoop程序说明,就是创建一个文本文件,然后统计这个文本文件中单词出现过多少次!
(MapReduce 运行在本地 启动JVM )
第一步 创建需要的文件目录,然后进入该文件中进行编辑
1.1

1.2 使用命令 vi wc.input 进入编辑 编辑如下内容

第二步 运行WordCount程序,数据来源于HDFS上
2.1 将创建出来的文件上传到HDFS文件系统上
bin/hdfs dfs -put wordcount/wc.input /user/zuoyan/mapreduce/wordcount/input
此时可视化的图形界面就已经能显示出来了
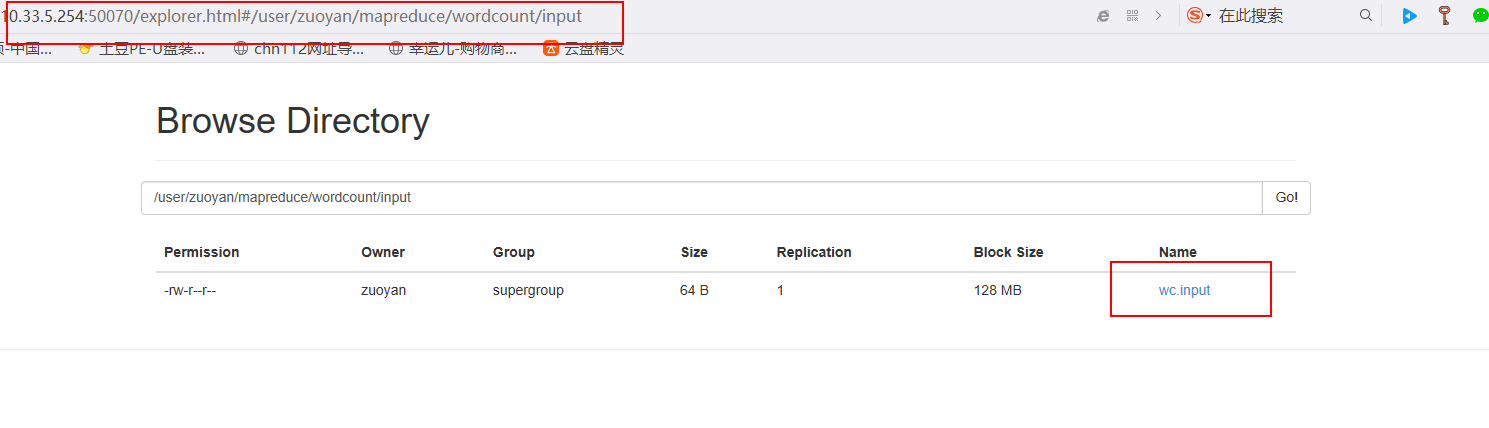
2.2 也可以使用命令来查看文件中的内容
使用命令:
bin/hdfs dfs -cat /user/zuoyan/mapreduce/wordcount/input/wc.input
使用之后的效果 (这样就表示文件已经成功的上传到文件系统上面去了!)

!!!2.3 注意一点,如果配置了 hadoop安装目录/etc/hadoop/core-site.xml 中的那个Hdfs文件系统 那读取数据的地址就是从配置的IP上读取 如果没有
就是默认从本机上读取
配置图如下

2.4 运行 Mapreduce程序
命令:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.5.0.jar wordcount /user/zuoyan/mapreduce/wordcount/input/ /user/zuoyan/mapreduce/wordcount/output
执行成功之后的截图

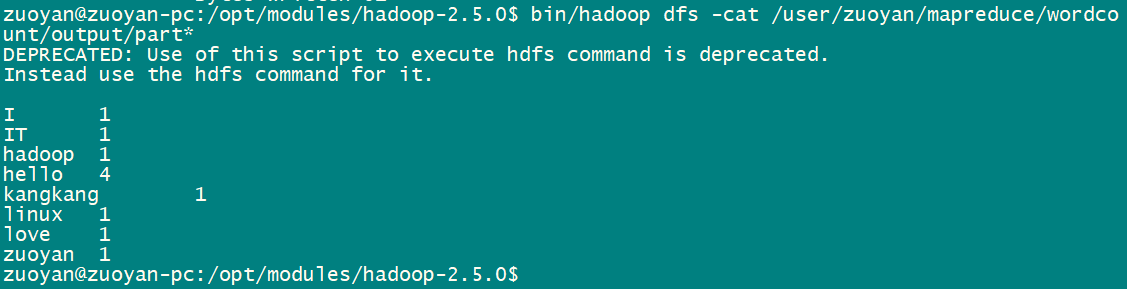
还有可以通过命令查看结果