InfluxDB是一个当下比较流行的时序数据库,InfluxDB使用 Go 语言编写,无需外部依赖,安装配置非常方便,适合构建大型分布式系统的监控系统。
1 下载安装
wget https://dl.influxdata.com/influxdb/releases/influxdb-1.4.3_linux_amd64.tar.gz
tar xvfz influxdb-1.4.3_linux_amd64.tar.gz
mv influxdb-1.4.3_linux_amd64 ~/disk/influxdb14
启动守护进程
cd ~/disk/influxdb14/usr/bin
./influxd &
创建管理员用户
./influx
show users
create user fsj with password 'fsj' with all privileges
将配置文件中auth-enabled字段修改为true
重启服务
service influxdb restart
重新登录
./influx -username fsj -password fsj
2 配置
查看当前配置 influxd config
设置密码
Enable authentication by setting the auth-enabled option to true in the [http] section of the configuration file
https://kiswo.com/article/1020
$ cat run_influxd.sh
app=/home/work/workspace/apps
log=/home/work/log/influxdb
influxd=$app/influxdb14/usr/bin/influxd
conf=$app/influxdb14/etc/influxdb/influxdb.conf
$influxd -config $conf 1>$log/stdout 2>$log/stderr & # -config指定配置文件
3 基本用法
influx -precision rfc3339 -username fsj -password fsj
CREATE DATABASE mydb
SHOW DATABASES
> show measurements;
name: measurements
name
----
TableTest
> select * from TableTest limit 10 # 大小写敏感
name: TableTest
time App Area Cid ContentId FloorId FloorName Imei Page count
---- --- ---- --- --------- ------- --------- ---- ----- -----
1520921431000000000 TMall list 0 271 居家 863276004580322 $Home$ 1
1520921431000000000 JD banner 77 首页 352042013052762 $Home$ 1
...
4 聚合函数
COUNT()
Returns the number of non-null values in a single field.
5 连续查询
查看CQ
SHOW CONTINUOUS QUERIES
name: TableTest_stat
name query
---- -----
pv CREATE CONTINUOUS QUERY pv ON TableTest_stat BEGIN SELECT sum(count) INTO TableTest_stat.autogen.TableTest_pv FROM TableTest_stat.autogen.TableTest GROUP BY time(30m) END
pv_day CREATE CONTINUOUS QUERY pv_day ON TableTest_stat BEGIN SELECT sum(count) INTO TableTest_stat.autogen.TableTest_pv_day FROM TableTest_stat.autogen.TableTest GROUP BY time(1d) END
pv_hour CREATE CONTINUOUS QUERY pv_hour ON TableTest_stat BEGIN SELECT sum(count) INTO TableTest_stat.autogen.TableTest_pv_hour FROM TableTest_stat.autogen.TableTest GROUP BY time(1h) END
pv_minute CREATE CONTINUOUS QUERY pv_minute ON TableTest_stat BEGIN SELECT sum(count) INTO TableTest_stat.autogen.TableTest_pv_minute FROM TableTest_stat.autogen.TableTest GROUP BY time(1m) END
uv_day CREATE CONTINUOUS QUERY uv_day ON TableTest_stat BEGIN SELECT count(distinct(Imei)) INTO TableTest_stat.autogen.TableTest_uv_day FROM TableTest_stat.autogen.TableTest GROUP BY time(1d) END
创建CQ
CREATE CONTINUOUS QUERY pv_all_1h ON TableTest_stat BEGIN SELECT sum(count) INTO "h.pv.all.1h" FROM TableTest GROUP BY time(1m),App,Area,Cid,ContentId,FloorId,FloorName,Imei END
CREATE CONTINUOUS QUERY uv_all_1d ON TableTest_stat BEGIN SELECT count( distinct(Uid)) INTO "h.uv.all.1d" FROM TableTest GROUP BY time(1d),App,Area,Cid,ContentId,FloorId,FloorName,Imei END
创建之后INTO "h.pv.all.1h"会自动变成 INTO TableTest_stat.autogen."h.pv.all.1h"
删除CQ
drop continuous query pv_all_1m on TableTest_stat;
聚合group by
all_1d CREATE CONTINUOUS QUERY all_1d ON TableTest_stat BEGIN SELECT count(distinct(Imei)) as CDImei, sum(count) as SCount INTO TableTest_stat.autogen."h.all.1d" FROM TableTest_stat."10day".TableTest GROUP BY time(1d), App, Area END
all_1h CREATE CONTINUOUS QUERY all_1h ON TableTest_stat BEGIN SELECT count(distinct(Imei)) as CDImei, sum(count) as SCount INTO TableTest_stat.autogen."h.all.1h" FROM TableTest_stat."10day".TableTest GROUP BY time(1d), App, Area END
6 数据保存策略
InfluxDB没有提供直接删除Points的方法,但是它提供了Retention Policies。主要用于指定数据的保留时间:当数据超过了指定的时间之后,就会被删除。
新建存储策略
> CREATE RETENTION POLICY "10day" ON "TableTest_stat" DURATION 240h REPLICATION 1 DEFAULT
> SHOW RETENTION POLICIES
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
10day 240h0m0s 24h0m0s 1 true
> ALTER RETENTION POLICY "10day" ON TableTest_stat SHARD DURATION 1w
> SHOW RETENTION POLICIES
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
10day 240h0m0s 168h0m0s 1 true
默认autogen的duration为0表示永久。
那shardGroupDuration对数据保存有什么影响呢?
注意,存储策略有点类似于分区数据块,修改了策略,新策略里不会有旧策略的数据。
要想查看旧策略下的数据,需要在 measurement 前加上策略名称。
> select * from "h.pv.all.1h" limit 10;
> select * from "autogen"."h.pv.all.1h" limit 10;
name: h.pv.all.1h
....
influxdb 也支持通过 http方式写入, see also https://stackoverflow.com/questions/37729008/can-i-create-different-retention-policy-for-different-measurements-in-influxdb
- http://www.oznetnerd.com/influxdb-retention-policies-shard-groups/
- https://www.linuxdaxue.com/retention-policies-in-influxdb.html
7 tag
> show series from TableTest limit 10;
key
---
TableTest,Action=Pay,App=JD,Area=list,Cid=0,FloorId=1,FloorName=办公,Page=Home,Rid=4
TableTest,Action=Pay,App=TM,Area=list,Cid=0,FloorId=2,FloorName=运动,Page=Home,Rid=1
...
> show tag keys from TableTest;
name: TableTest
tagKey
------
Action
App
Area
Cid
ContentId
FloorId
FloorName
Page
Rid
Sid
> show tag values from TableTest with key="App" limit 30;
name: TableTest
key value
--- -----
App JD
App TM
...
> show tag values from TableTest with key="Area" limit 30;
name: TableTest
key value
--- -----
Area list
Area banner
...
8 Field
相当于实际记录的数据值,也是采用key=value形式,多个 tag 之间用 ',' 分隔。
> show field keys
name: TableTest
fieldKey fieldType
-------- ---------
Imei string
count integer
field列不能用在group by后面。
当列按照filed写入后,改成按tag写入,会使得改列即是filed又是tag。还是不能用在group by后面。
只能删表重建。
9 查询实战
select count(Imei) as PV,count(distinct(Imei)) as UV from TableTest where (time>=1521993600000000000 and time <1522080000000000000) and ((App ='JD')) and Action = 'View' group by App,time(86400s) tz('Asia/Shanghai')
select count(distinct(Imei)) AS CDImei, sum(count) AS SCount from TableTest where App='JD' and time>'2018-03-29' tz('Asia/Shanghai')
where条件中,要通过tag筛选必须加单引号,不能双引号
> select time,App,Action,count from TableTest where Action="View" order by time desc limit 10;
从命令行查询
$ influx -precision rfc3339 -username admin -password x -database TableTest_stat -execute "YOUR SQL" -format=csv
10 进阶
10.1 选型
Influxdb vs Prometheus
influxdb集成已有的概念,比如查询语法类似sql,引擎从LSM优化而来,学习成本相对低。
influxdb支持的类型有float,integers,strings,booleans,prometheus目前只支持float。
influxdb的时间精度是纳秒,prometheus的则是毫秒。
influxdb仅仅是个数据库,而prometheus提供的是整套监控解决方案,当然influxdb也提供了整套监控解决方案。
influxdb支持的math function比较少,prometheus相对来说更多,influxdb就目前使用上已经满足功能。
2015年prometheus还在开发阶段,相对来说influxdb更加稳定。
influxdb支持event log,prometheus不支持。
更详细的对比请参考:
https://db-engines.com/en/system/Graphite%3BInfluxDB%3BPrometheus
open source influxdb cluster http://mysql.taobao.org/monthly/2018/02/02/
10.2 架构
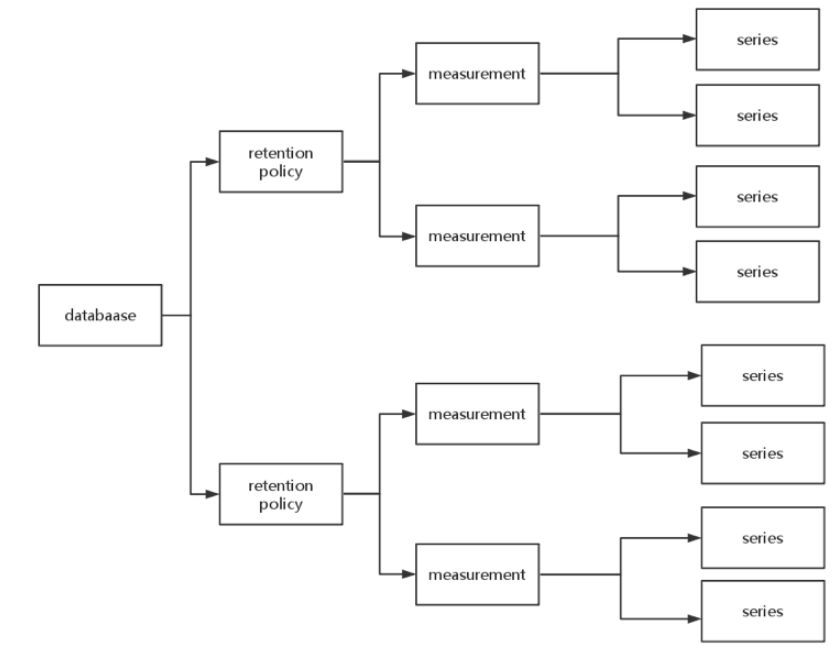
measurement, tag set, retention policy相同的数据集合算做一个 series。理解这个概念至关重要,因为这些数据存储在内存中,如果series太多,会导致OOM。
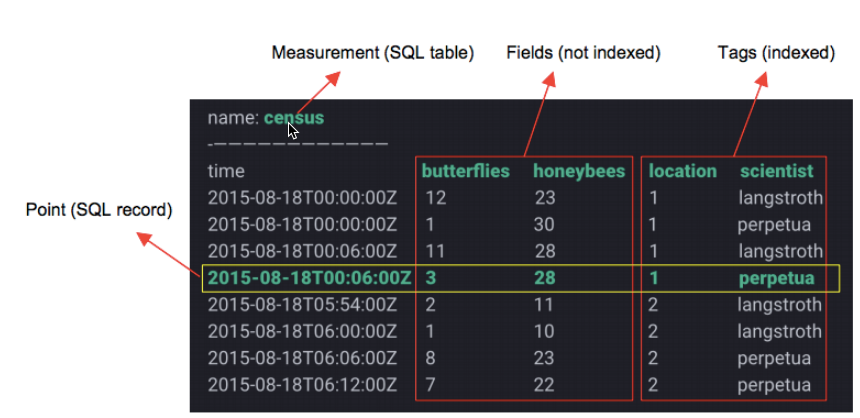
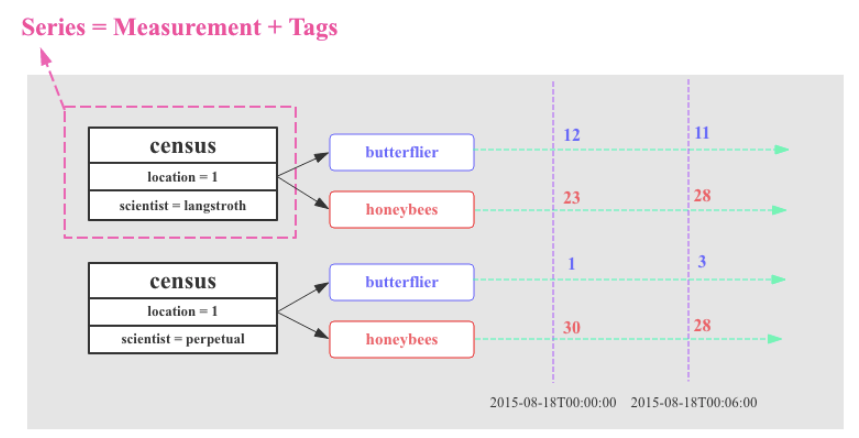
不考虑PR,也可以说series = measurement + tags
插入一条记录到新表:INSERT Cpu,host=serverA,region=us_west value=0.64
也是 insert measurement,tags field 的格式
11.3 shardGroupDuration对数据保存的影响
http://www.oznetnerd.com/influxdb-retention-policies-shard-groups/
Shard 存储一定时间间隔的数据,每个目录对应一个shard,目录的名字就是shard id。每一个shard都有自己的cache、wal、tsm file以及compactor,目的就是通过时间来快速定位到要查询数据的相关资源,加速查询的过程,并且也让之后的批量删除数据的操作变得非常简单且高效。
Shard Group 是shard的逻辑容器。每一个有数据的RP至少有一个关联的shard group,
一个shard group覆盖的时间范围由RP里的SHARD DURATION参数决定。
shard duration的默认值
Retention Policy’s DURATION Shard Group Duration
< 2 days 1 hour
= 2 days and <= 6 months 1 day
6 months 7 days
较小的shard group duration有助于系统更高效的删数据。
假如RP duration是1d,shard group duration是1h,那么系统每个小时都会删一个shar group
test case
> show retention policies;
name duration shardGroupDuration replicaN default
---- -------- ------------------ -------- -------
autogen 0s 168h0m0s 1 false
d1 24h0m0s 1h0m0s 1 true
> show shard groups;
name: shard groups
id database retention_policy start_time end_time expiry_time
2 mydb autogen 2018-03-05T00:00:00Z 2018-03-12T00:00:00Z 2018-03-12T00:00:00Z
80 mydb autogen 2018-05-28T00:00:00Z 2018-06-04T00:00:00Z 2018-06-04T00:00:00Z
81 mydb d1 2018-05-29T08:00:00Z 2018-05-29T09:00:00Z 2018-05-30T09:00:00Z
82 mydb d1 2018-05-29T09:00:00Z 2018-05-29T10:00:00Z 2018-05-30T10:00:00Z
83 mydb d1 2018-05-29T10:00:00Z 2018-05-29T11:00:00Z 2018-05-30T11:00:00Z
84 mydb d1 2018-05-29T11:00:00Z 2018-05-29T12:00:00Z 2018-05-30T12:00:00Z
85 mydb d1 2018-05-29T12:00:00Z 2018-05-29T13:00:00Z 2018-05-30T13:00:00Z
87 mydb d1 2018-05-29T13:00:00Z 2018-05-29T14:00:00Z 2018-05-30T14:00:00Z
4 nodes autogen 2018-03-12T00:00:00Z 2018-03-19T00:00:00Z 2018-03-19T00:00:00Z
5 TableTest autogen 2018-03-12T00:00:00Z 2018-03-19T00:00:00Z 2018-03-19T00:00:00Z
> select * from autogen.cpu;
name: cpu
time host region value
---- ---- ------ -----
2018-03-06T06:30:57.464227026Z serverA us_west 0.64
> select * from Cpu;
name: Cpu
time host region value
---- ---- ------ -----
2018-05-29T08:36:13Z serverX us_west 0.64
2018-05-29T08:48:54Z serverF us_west 0.64
2018-05-29T08:48:54Z serverF1 us_west 0.64
2018-05-29T09:06:58.532829069Z serverC us_west 0.64
2018-05-29T09:09:36.977236835Z serverC us_west 0.64
...每秒一个
11 实战经验
1、在influxdb中,tag_set + timestamp 用于标识是否同一条记录,如果有两条记录该值相同,后面的记录的field_set会覆盖前面的值。
2、取值范围很多的列不要存到tag。
配置文件中默认max-values-per-tag = 100000。虽然修改这个值可以解决 max-values-per-tag limit exceeded (100000/100000) 问题,但是建议不改,把这种列放到filed里
InfluxDB在内存中维护了系统中每个series数据的索引。随着具有唯一性的series数据数量的增长,RAM的使用也会增长。过高的series cardinality会导致操作系统kill掉InfluxDB进程,抛出OOM异常。
3、日志过多塞爆服务器
删除文件后,进程占用的空间也没有被释放
4、 每天存储量
目前可以抗住每天6G的存储。
上限应该是每天8T以上(参考 http://www.infoq.com/cn/articles/storage-in-sequential-databases )
修改存储路径:https://stackoverflow.com/questions/28350290/how-to-change-location-of-influxdb-storage-folder