生成对抗网络(GAN与W-GAN)
作者:凯鲁嘎吉 - 博客园 http://www.cnblogs.com/kailugaji/
通过阅读《神经网络与深度学习》,了解生成对抗网络(Generative Adversarial Networks,GAN)的来龙去脉,并介绍GAN与Wasserstein GAN。
1. 基础知识
KL散度 (Kullback–Leibler Divergence)、JS散度 (Jensen–Shannon Divergence)、推土机距离 (Wasserstein Distance, or Earth-Mover’s Distance)以及Lipschitz连续函数.

2. Vanilla GAN (标准GAN/原始GAN)
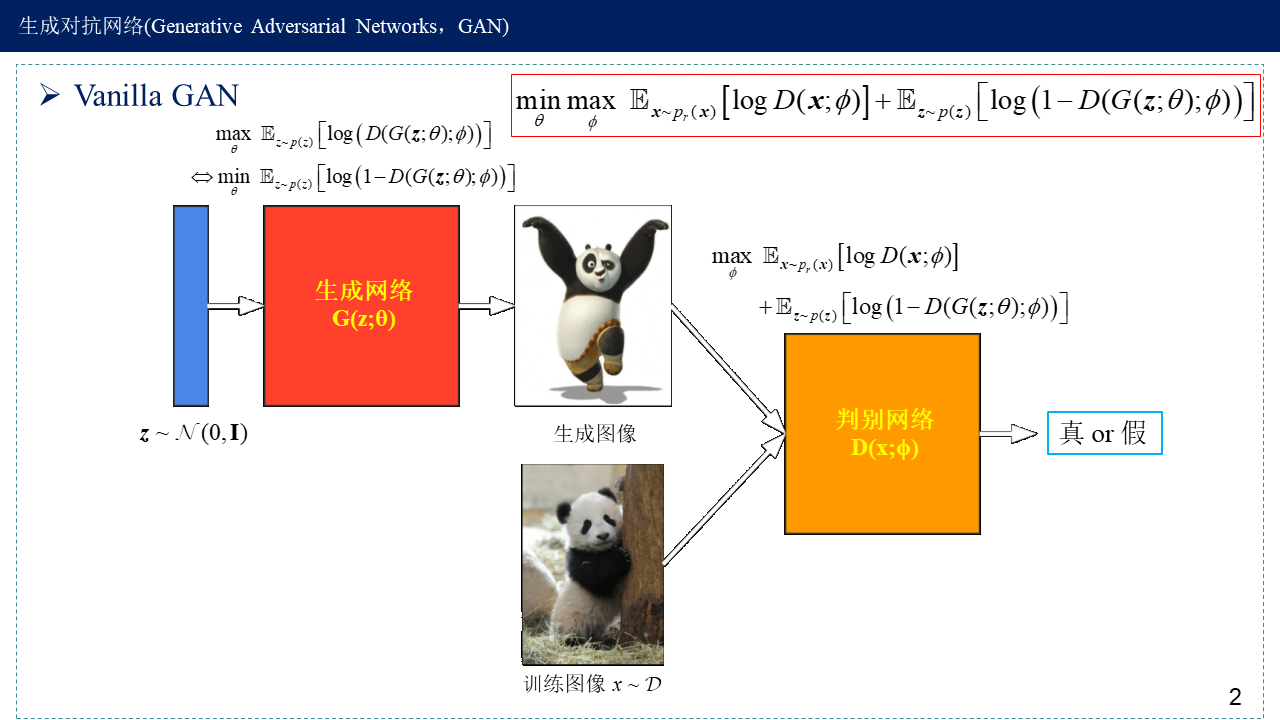
判别网络,生成网络,以及总体目标函数
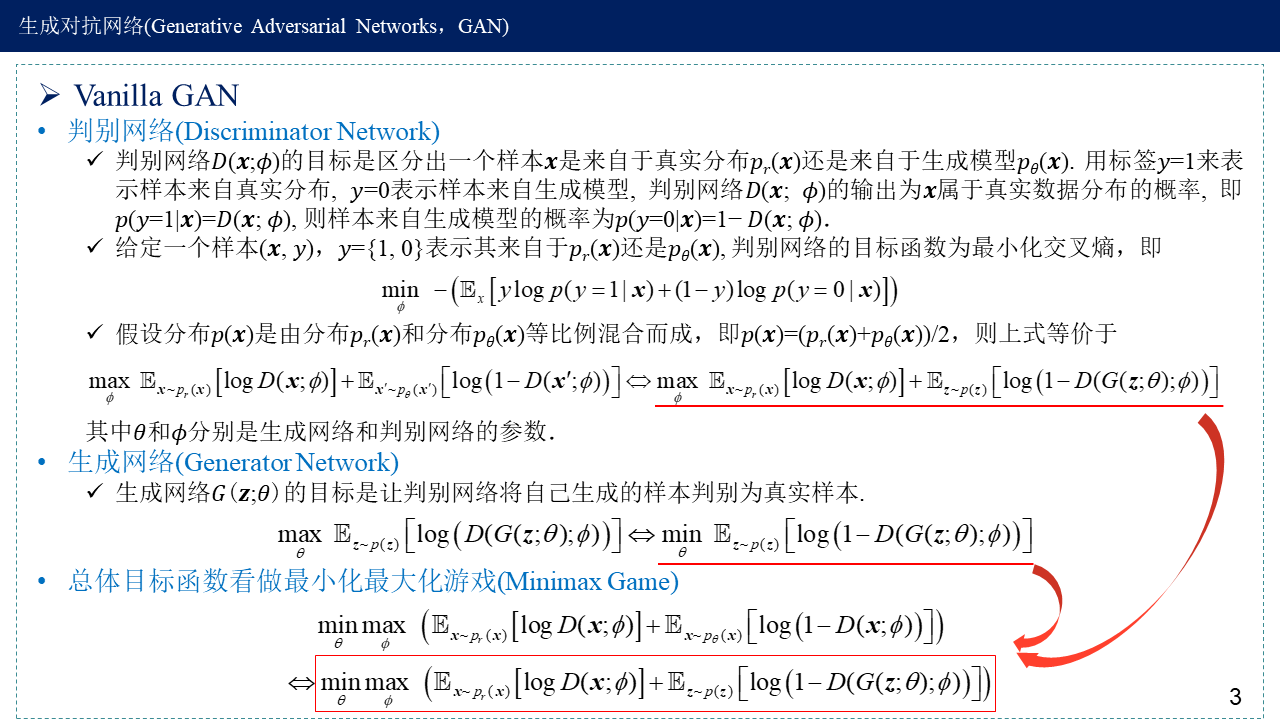
最小化交叉熵就是极大似然估计,使其期望最大化。
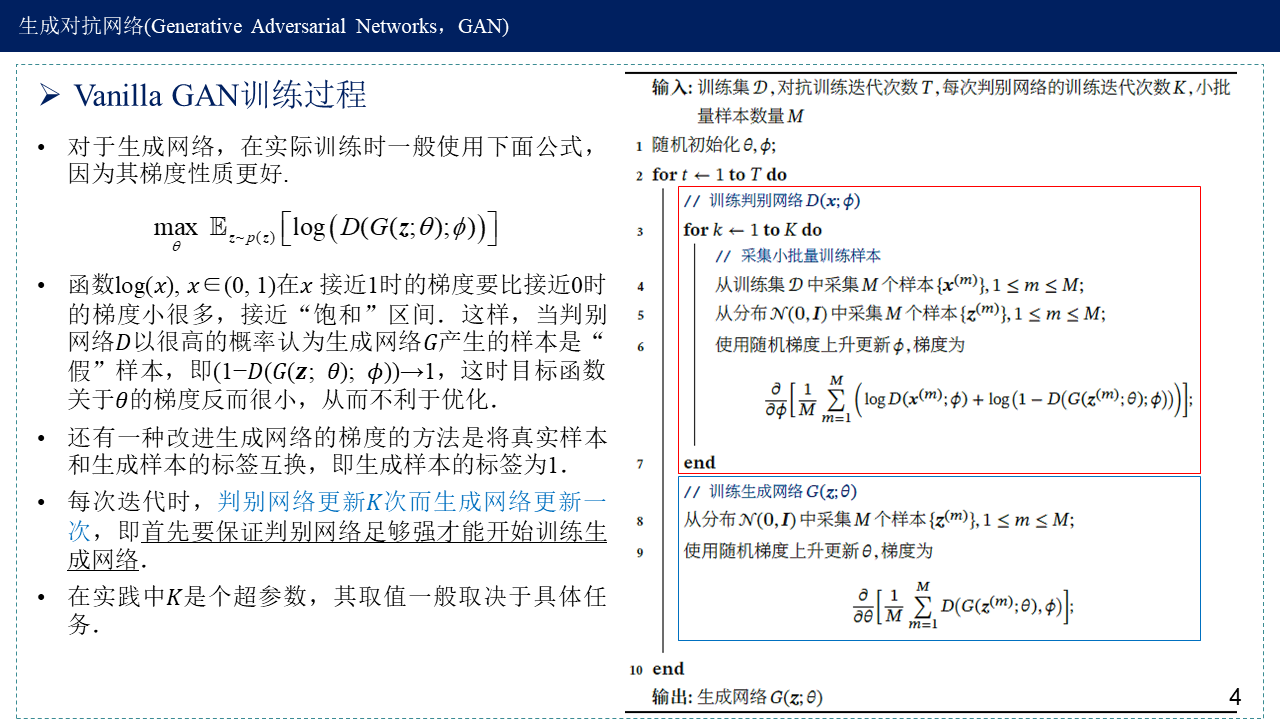
Vanilla GAN训练过程
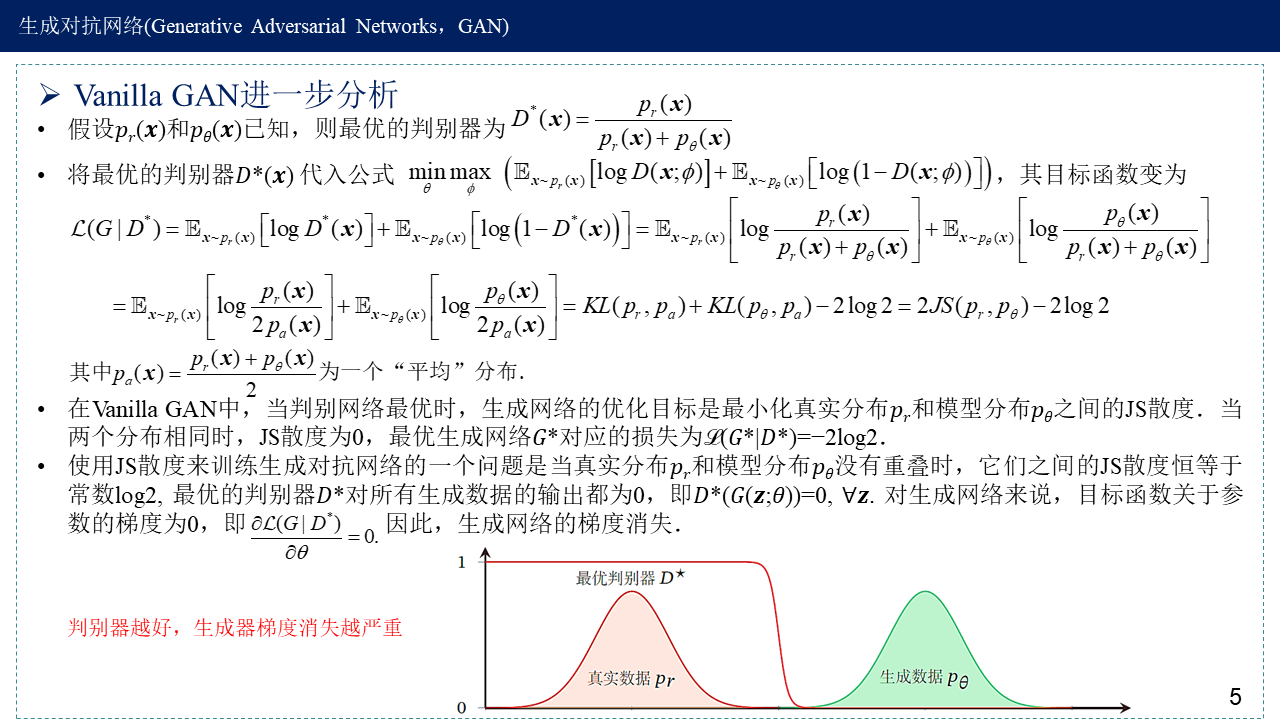
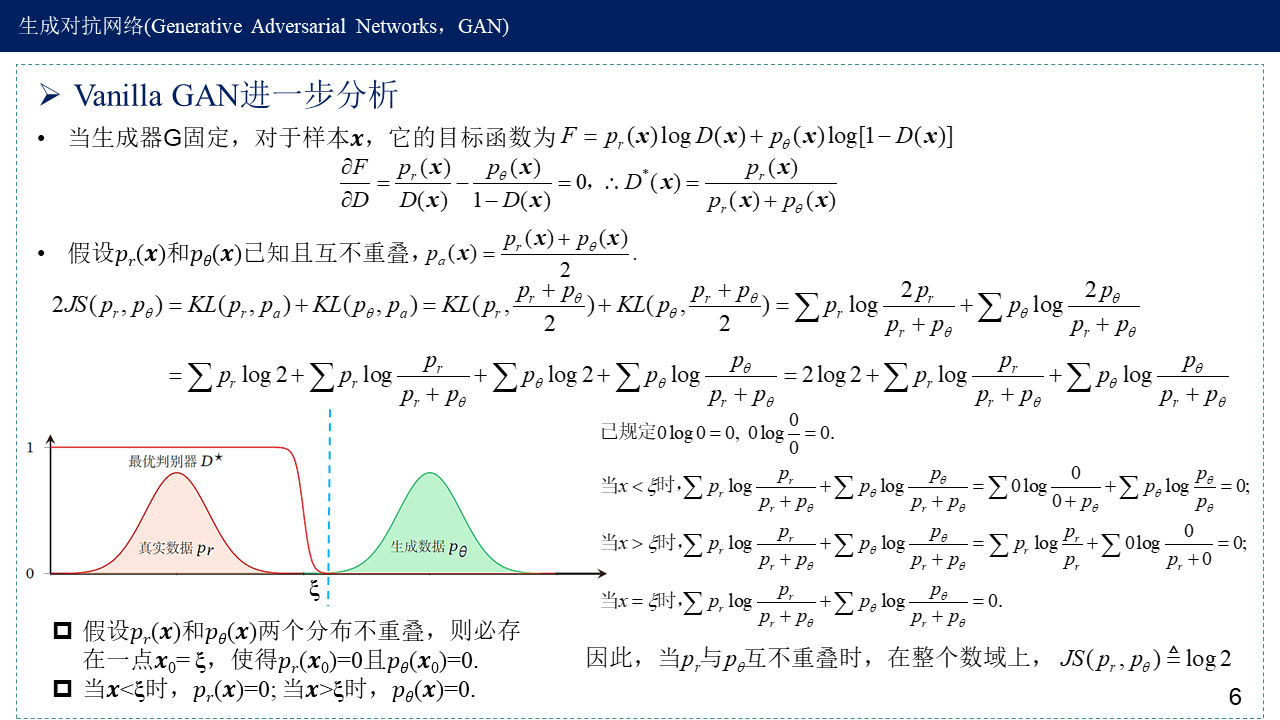
Vanilla GAN进一步分析——梯度消失,分布不重叠时,JS散度恒为log2
Vanilla GAN进一步分析——逆向KL散度导致模型坍塌

3. Wasserstein GAN



拓展:由生成对抗网络联想到假设检验中的两类错误
生成器:支持原假设,$p_{data}=p_{ heta}$,生成的图像越真实越好;
判别器:支持备择假设,$p_{data} eq p_{ heta}$,越能判别出假图像越好。
假设检验会出现两类错误,本来图像是真实的,原假设是正确的,但是却拒绝原假设,认为图像是假的,这是第一类错误;本来图像是假的,原假设是错误的,却接受原假设,认为图像是真实的,这是第二类错误。统计学告诉我们这两类错误都无法避免,也无法同时使两者出现的概率都最小,一类错误的减少必然会使另一类错误增加。一种折中的方案是,只限制犯第一类错误的概率,这就是Fisher显著性检验。对于GAN来说,生成器生成了一些重复但是很安全的样本,缺乏多样性。
4. 参考文献
邱锡鹏,神经网络与深度学习,机械工业出版社,https://nndl.github.io/, 2020.