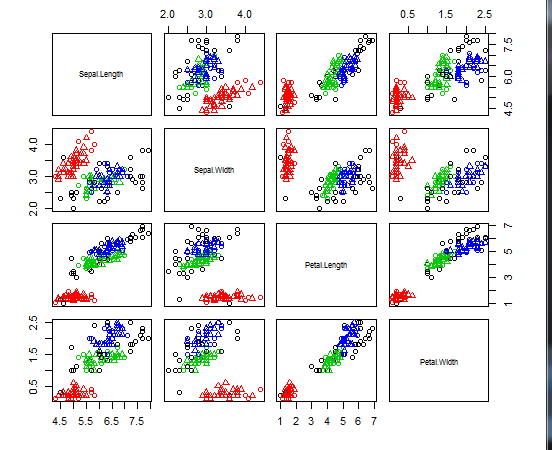
k-means法与k-medoids法都是基于距离判别的聚类算法。本文将使用iris数据集,在R语言中实现k-means算法与k-medoids算法。
-
k-means聚类

首先删去iris中的Species属性,留下剩余4列数值型变量。再利用kmeans()将数据归为3个簇
names(iris) iris2 <- iris[,-5] #删去species一列 kmeans_result <- kmeans(iris2,3) #将数据归为3个簇
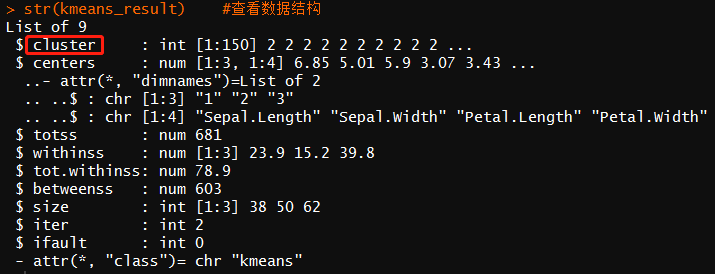
str(kmeans_result) #查看数据结构
table(iris$Species,kmeans_result$cluster) #查看聚类结果和观测值的对比

从聚类结果可看出,'versicolor‘类与'virginica’类之间存在小范围的重叠。有2个versicolor被错误归类为第一类,有14个'virginica’被归为第三类。
1 plot(iris2[c('Sepal.Length','Sepal.Width')],col=kmeans_result$cluster) 2 points(kmeans_result$centers[,c('Sepal.Length','Sepal.Width')],col=1:3,pch=10,cex=3)
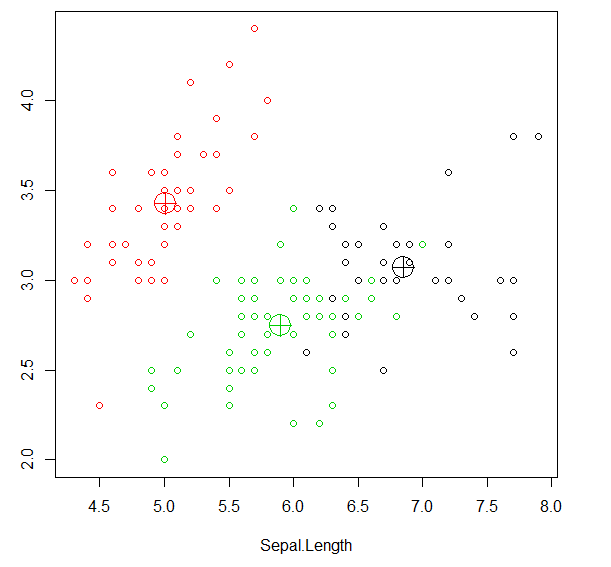
数据集有四个维度,而绘图只用了前两个维度的数据,
图中所示的一些靠近绿色中心的黑点实际在四维空间中更靠近黑色中心
需注意的是多次运行得到的K-means聚类结果可能不同,这是因为初始的簇中心是随机选择的
-
k-medoids聚类

先使用fpc包中的pamk()实现K-中心聚类,优点是不要求用户输入K的值
2 #而是自动调用pam()或函数clara()更具最优平均阴影宽度估计的聚类簇个数来划分数据 3 library(fpc) 4 pamk.result <- pamk(iris2) 5 str(pamk.result)
1 pamk.result$nc #推荐使用两个簇

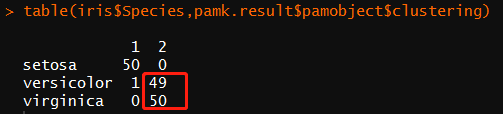
1 table(iris$Species,pamk.result$pamobject$clustering)

layout(matrix(c(1,2),1,2)) #图形显示为一行两列 plot(pamk.result$pamobject)
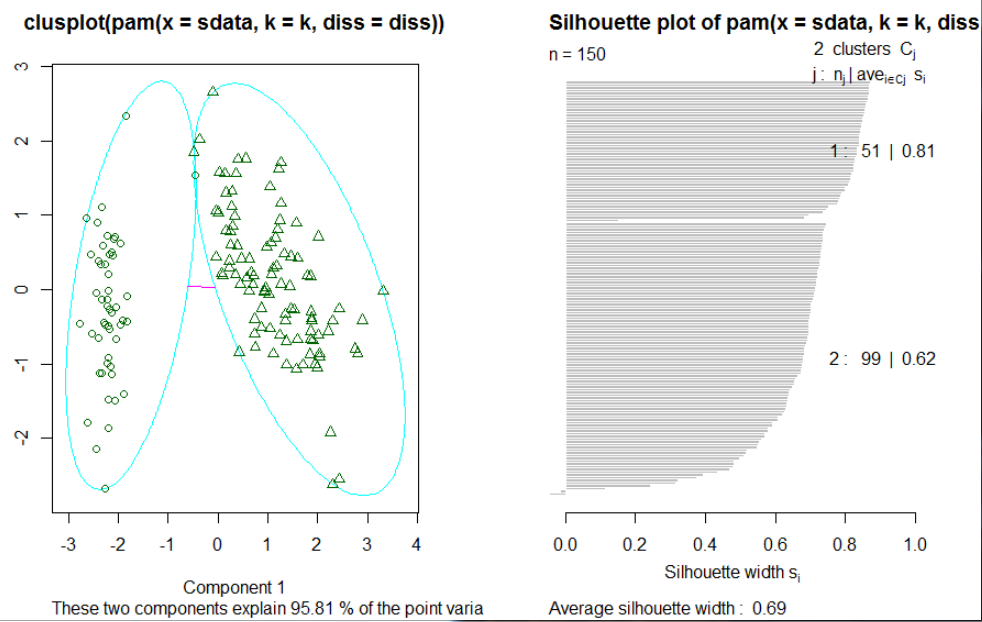
在 上 面 的 例 子 中 , 函 数 pamk() 生 成 了 两 个 簇 : 一 个 是 “ setosa ” , 另 一 个 是 “ versicolor ”
和 “ virgrnica " 的 混 合 。 在 图 6 . 2 中 , 左 边 的 图 像 为 两 个 簇 的 2 维 聚 类 图 像 ( “ clusplot " ) ,
两 个 簇 中 间 的 直 线 表 示 距 离 ; 右 边 的 图 像 显 示 了 这 两 个 簇 的 附 影 。 当 的 值 比 较 大 时 ( 接 近
1 ) 表 明 相 应 的 观 测 点 能 够 准 确 地 划 分 到 相 似 性 较 大 的 簇 中 , 当 的 值 比 较 小 时 ( 接 近 0 ) 表
明 观 测 点 位 于 这 两 个 簇 重 叠 的 部 分 。 如 果 观 测 点 的 凿 值 为 负 数 , 则 说 明 观 测 点 被 划 分 到 错 误
的 族 中 。 由 于 在 上 面 的 阴 影 图 中 , 两 个 簇 的 均 值 分 别 为 0 , 81 和 0 . 62 , 所 以 这 表 明 这 两 个
簇 的 划 分 结 果 很 好
接下来使用cluster包中的pam()函数
library(cluster) pam.result <- pam(iris2,3) table(pam.result$clustering,iris$Species)
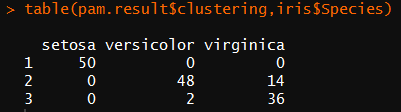
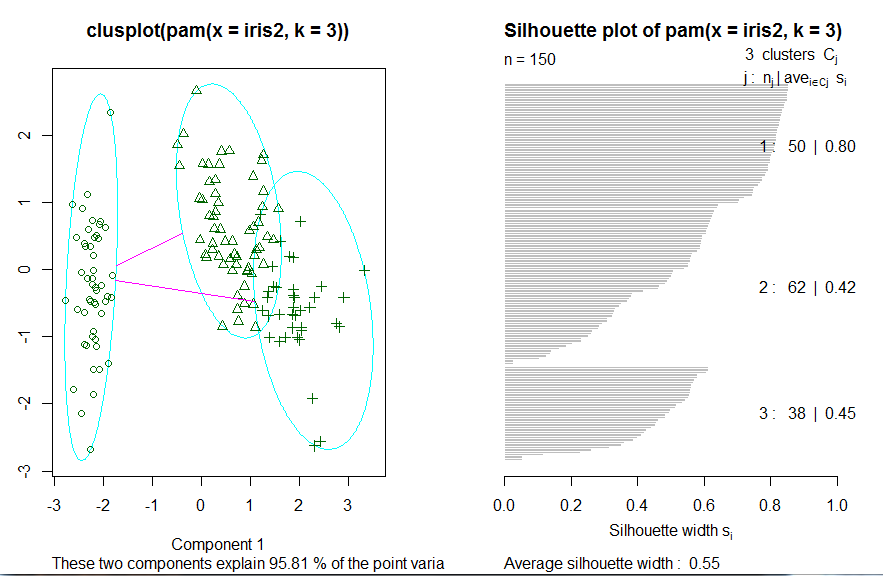
对 比 上 面 两 个 聚 类 的 结 果 , 很 难 说 函 数 pamk() 和 pam() 哪 一 个 能 获 得 更 好 的 聚 类 结 果 ,
结 果 质 量 的 好 坏 依 赖 于 目 标 问 题 以 及 领 域 知 识 和 经 验 。 在 这 个 例 子 中 , 函 数 pam() 得 到 的 聚
类 结 果 似 乎 更 好 , 这 是 因 为 它 识 别 出 3 个 不 同 的 簇 , 分 别 对 应 于 3 个 不 同 的 种 类 。 因 此 , 使
用 启 发 式 方 法 来 识 别 簇 个 数 的 函 数 pamk() 并 不 意 味 着 总 是 能 得 到 更 好 的 聚 类 结 果 。 还 需 要 注
意 的 是 , 由 于 事 先 已 经 知 道 Species 属 性 确 实 只 包 含 了 3 个 种 类 , 因 此 在 使 用 函 数 pam() 时 将
设 置 为 3 也 具 有 一 定 的 投 机 性 。
-
两种聚类算法的对比
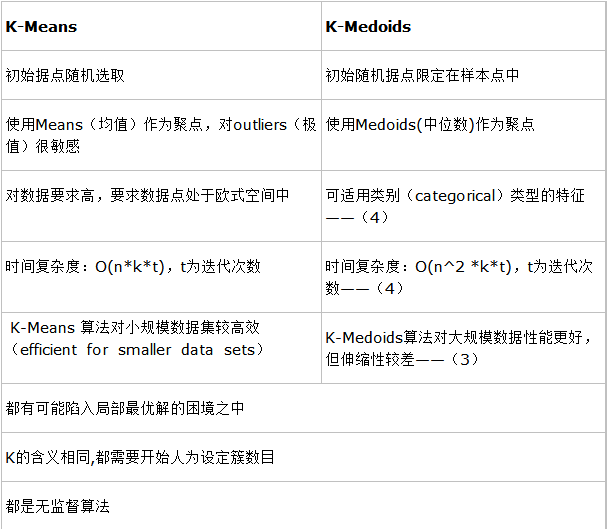
-
层次聚类
使用iris数据集,抽取40个样本
1 set.seed(1234) 2 idx <- sample(1:nrow(iris),40) #抽取40个数 3 iris_sample <- iris[idx,-5] #抽取40个样本且删去species一列
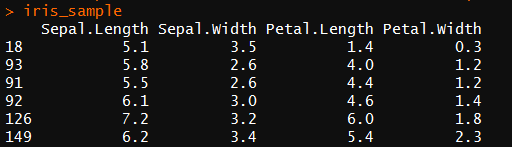
out.dist <- dist(iris_sample,method = 'euclidean')#dist()将数据转化为两点之间的距离

1 hc <- hclust(out.dist,method='average') #代入两点距离(out.dist),method='ave'指使用类平均法聚类

1 plot(hc,hang=-1,labels=iris$Species[idx]) #labels:根据目测值添加标签
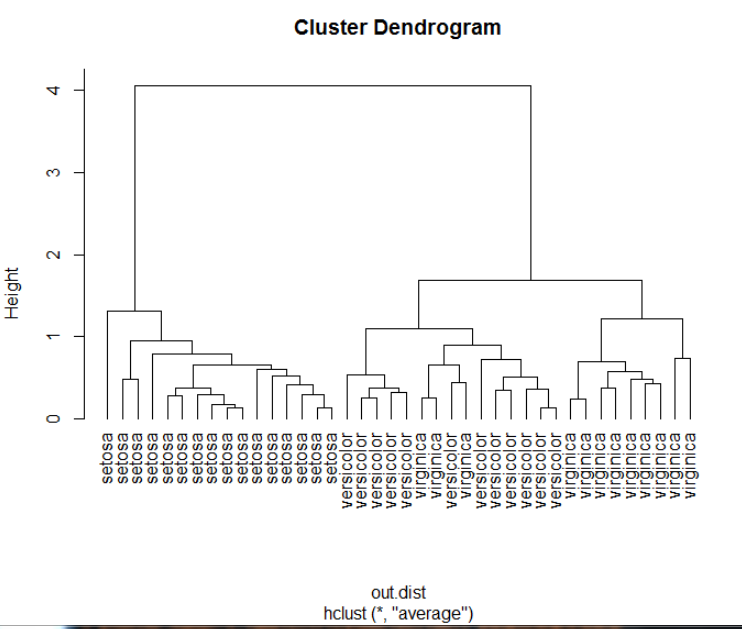
1 rect.hclust(hc,k=3) #归为三类
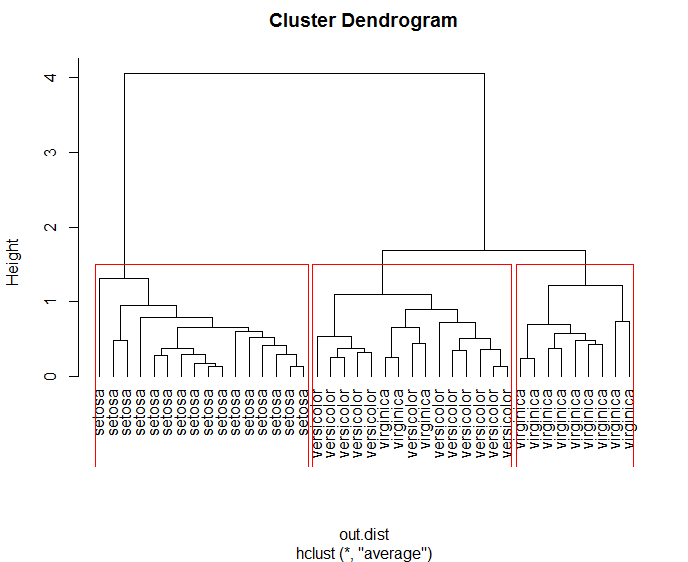
1 groups <- cutree(hc,k=3) #查看分类

-
基于密度的聚类

1 library(fpc) 2 iris2 <- iris[,-5] 3 ds <- dbscan(iris2,eps = 0.42,MinPts = 5) #设置可达距离和最小数目的对象点 4 table(ds$cluster,iris$Species)
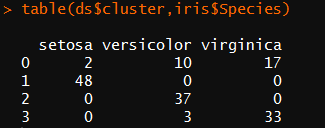
‘1’-‘3’指被识别出来的三个聚类簇,‘0’表示噪声数据或离散点,即不属于任何簇的对象,绘制的图中使用黑色小圆圈表示
1 plot(ds,iris2[c(1,4)]) #展示第一列和第四列的聚类结果
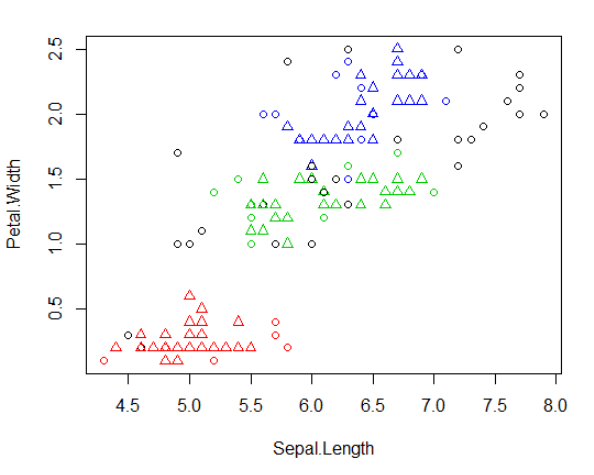
1 plot(ds,iris2)