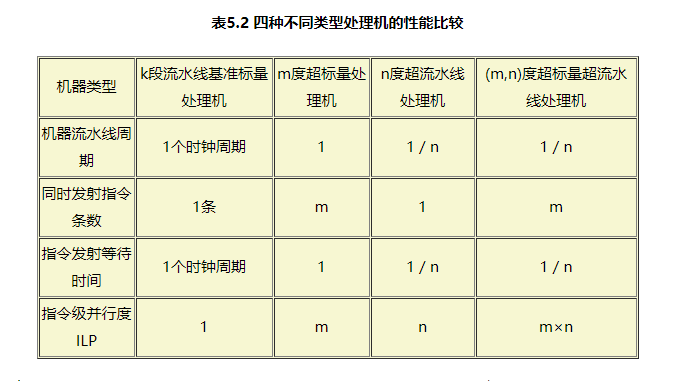
在表5.2中,基准标量处理机是一台普通的单流水线处理机。为了便于进行比较,把基准标量处理机的机器流水线周期和指令发射等待时间都假设为1个时钟周期,同时发射的指令条数为一条,它的指令级并行度ILP(Instruction Level Parallelism)假设为1。另外三种指令级并行处理机,即并行度为m的超标量处理机,并行度为n的超流水线处理机,以及并行度为(m,n)的超标量超流水线处理机,它们的性能都相对于基准标量处理机进行比较。
单流水线处理机只有一条指令流水线,只有一个多功能的操作部件,每个时钟周期"取指令"和"分析"完成一条指令。在许多流水线处理机中,指令流水线的流水段数k=4;它把一条指令的执行过程主要分解为"取指令"、"分析"、"执行"和"写结果"4个阶段。指令所要执行的功能主要在多功能操作部件中,在"执行"这一流水段完成。多数流水线处理机的多功能操作部件采用流水线结构。有的简单指令,只要一个时钟周期就能够在"执行"流水段中完成,而比较复杂的指令往往需要多个时钟周期。另外,还有条件转移等的影响;因此,一般流水线标量处理机每个时钟周期平均执行指令的条数小于1,即它的指令级并行度ILP<1。
超标量、超流水线和超标量超流水线三种处理机在一个时钟周期内可以执行完成多条指令,即它们的指令级并行度ILP都大于1。
超标量处理机
基本结构
超标量处理机的典型结构是有多个操作部件,一个或几个比较大的通用寄存器堆,一个或两个高速Cache。先进的超标量处理机一般都包含有三个处理单元,一个是定点处理单元,通常称为中央处理单元(CPU),它由一个或多个整数处理部件组成;第二个是浮点处理单元(FPU),它由浮点加减法部件和浮点乘除法部件等组成;第三个是图形加速部件,也称为图形处理单元(GPU),这是现代处理机中不可缺少的一个部分。先进的超标量处理机通常都设置有大量的通用寄存器。在有的超标量处理机中,CPU和FPU分别使用两个通用寄存器堆。在多数超标量处理机中都设置有两个一级高速Cache,一个是指令Cache,另一个是数据Cache,这种把指令Cache和数据Cache分开的结构被称为哈佛(Harvard)结构。每个高速Cache的容量一般在几K至几十K字节;有的超标量处理机,还把二级Cache也做在处理机芯片内。
在MC88110超标量处理机内部有两个寄存器堆;其中,整数部件使用通用寄存器堆,它由32个32位的寄存器组成;浮点点部件使用扩展寄存器堆,它由32个80位的寄存器组成。每个寄存器堆有8个端口,分别与8条内部总线相连接,可以同时读出8个操作数提供给各个操作部件使用。另外,在取数/存数部件中,还有一个缓冲深度为4的先行读数栈和一个缓冲深度为3的后行写数栈。
指令和数据分别存放在两个独立的高速Cache中,指令Cache和数据Cache的容量各为8K字节。两个Cache都采用两路组相联方式工作,因此,每个时钟周期可以提供两个64位的指令和数据。另外,为了减少转移指令对流水线的影响,专门设置有一个转移目标指令Cache。在遇到条件转移指令时,在指令Cache和目标指令Cache中分别存放两路分支上的有关指令;并且,指令分配部件在每个时钟周期分别从指令Cache和目标指令Cache中各取出两条指令来同时进行译码;最后,根据形成的条件码决定把其中一路分支上的指令送到操作部件中去。
如图5.47所示,是由Motorola公司生产的一种先进超标量处理机MC88110。它有10个操作部件,其中两个整数部件,可以作32位整数运算,其中也包括地址运算等。整数操作是单周期执行,完成一条 整数运算指令使用一条4段流水线,包括取指令IF、译码ID、执行EX和写结果WR,每个时钟周期可以完成两条整数指令。浮点运算是80位字长的,包括浮点加、减、乘、除和求浮点平方根等16条指令。浮点加法部件和乘法部件都采用3级流水线,每个时钟周期可以完成一条乘法指令和一条浮点加法指令;而且,对单精度、双精度及扩展双精度指令的执行速度都一样快。两个专用的图形处理部件可以直接对图形的象素进行处理,它与浮点操作部件一起,提供高性能的三维(3D)图形处理能力,共有9条专门的图形处理指令。
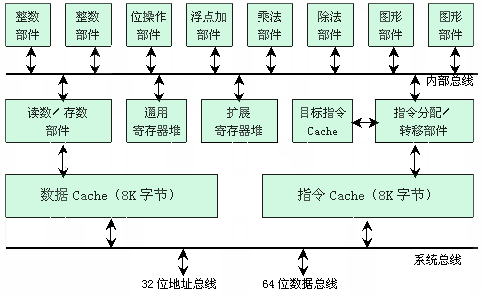
在MC88110超标量处理机内部有两个寄存器堆;其中,整数部件使用通用寄存器堆,它由32个32位的寄存器组成;浮点点部件使用扩展寄存器堆,它由32个80位的寄存器组成。每个寄存器堆有8个端口,分别与8条内部总线相连接,可以同时读出8个操作数提供给各个操作部件使用。另外,在取数/存数部件中,还有一个缓冲深度为4的先行读数栈和一个缓冲深度为3的后行写数栈。
指令和数据分别存放在两个独立的高速Cache中,指令Cache和数据Cache的容量各为8K字节。两个Cache都采用两路组相联方式工作,因此,每个时钟周期可以提供两个64位的指令和数据。另外,为了减少转移指令对流水线的影响,专门设置有一个转移目标指令Cache。在遇到条件转移指令时,在指令Cache和目标指令Cache中分别存放两路分支上的有关指令;并且,指令分配部件在每个时钟周期分别从指令Cache和目标指令Cache中各取出两条指令来同时进行译码;最后,根据形成的条件码决定把其中一路分支上的指令送到操作部件中去。
单发射与多发射
单发射处理机的指令执行时空图如图5.48(a)所示,它在一个时钟周期内只从存储器中取出一条指令,并且只对一条指令进行译码,只执行一条指令,只写一个运算结果。
在单发射处理机中,取指令部件和指令译码部件只各设置一套,而操作部件可以只设置一个多功能操作部件,也可以设置多个独立的操作部件。例如,定点算术逻辑部件ALU、取数存数部件LSU、浮点加法部件FAD、乘除法部件MDU等。一个有4个操作部件组成的单发射处理机如图5.49(a)所示。单发射处理机在指令一级通常采用流水线结构;而在操作部件中,有的机器采用流水线结构,也有的机器不采用流水线结构。
单发射处理机的设计目标是每个时钟周期平均执行一条指令,即它的指令级并行度ILP的期望值1。如果从表5.2中看,相当于m=1。实际上,它就是一台有k段流水线的普通标量处理机。由于数据相关、条件转移和资源冲突等原因,实际的ILP不可能达到1。通过优化编译器对指令序列进行重组(recorganizer),以及采用软件与硬件相结合的方法处理数据相关、条件转移和资源冲突等,可以使ILP接近于1。但是,单发射处理机的ILP不可能大于1。
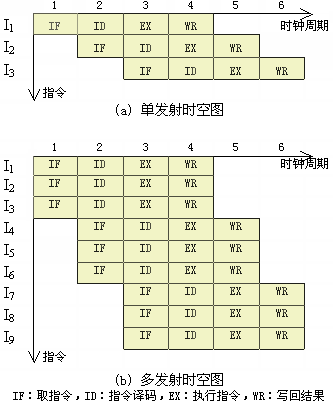
图5.48 单发射与多发射处理机的指令执行时空图
多发射处理机在一个基本时钟周期内同时从指令Cache中读出多条指令,同时对多条指令进行译码。一个同时发射三条指令的多发射处理机的指令执行时空图如图5.48(b)所示。为了实现在一个时钟周期同时多发射条指令,通常需要有多个取指令部件,多个指令译码部件和多个写结果部件。图6.53(b)是一个同时发射两条指令的多发射处理机的指令流水线。两个取指令部件同时从指令Cache中取出两条指令,两个指令译码部件同时对两条指令进行译码,指令的译码结果分别送往4个操作部件执行。
性能
为了便于比较,把单流水线普通标量处理机的指令级并行度记作(1,1),超标量处理机的指令级并行度记作(m,1),超流水线处理机的指令级并行度记作(1,n),而超标量超流水线处理机的指令级并行度记作(m,n)。
在理想情况下,N条指令在单流水线普通标量处理机上的执行时间为: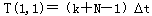
(5.29)
其中,k是流水线的级数,是一个时钟周期的时间长度。
如果把相同的N条指令在一台每个时钟周期发射m条指令的超标量处理机上执行,所需要的时间为: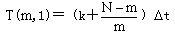
其中,第一项是第一批m条指令同时通过m条指令流水线所需要的执行时间,而第二项是执行其余N-m条指令所需要的时间,这时,每一个时钟周期有m条指令分别通过m条指令流水线。
因此,超标量处理机相对于单流水线普通标量处理机的加速比为: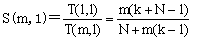
当N→∞时,在没有资源冲突,没有数据相关和控制相关的理想情况下,超标量处理机的加速比的最大值为: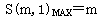
超流水线处理机
在一般标量流水线处理机中,通常把一条指令的执行过程分解为"取指令"、"译码"、"执行"和"写回结果"4个流水段。如果把其中的每个流水段再细分,例如,再分解为两个延迟时间更短的流水段,则一条指令的执行过程就要经过8个流水段,这样,在一个时钟周期内就能够"取指令"两条,"译码"、"执行"和"写结果"各两条指令。这种在一个时钟周期内能够分时发射多条指令的处理机称为超流水线处理机。另外,也可以把指令流水线的段数大于或等于8的流水线处理机称为超流水线处理机。
超流水线处理机与上一节中介绍的超标量处理机不同,超标量处理机是通过重复设置多"取指令"部件,设置多个"译码"、"执行"和"写结果"部件,并让这些功能部件同时工作来提高指令的执行速度,实际上是以增加硬件资源为代价来换取处理机性能的;而超流水线处理机则不同,它只需要增加少量硬件,是通过各部分硬件的充分重叠工作来来提高处理机性能的。从流水线的时空图上看,超标量处理机采用的是空间并行性,而超流水线处理机采用的是时间并行性。
指令执行时序
一台并行度ILP为n的超流水线处理机,它在一个时钟周期内能够发射n条指令;但这n条指令不是同时发射的,每隔1/n个时钟周期发射一条指令;因此,实际上超流水线处理机的流水线周期为1/n个时钟周期。一台每个时钟周期分时发射3条指令的超流水线处理机的指令执行时空图如图5.56所示。
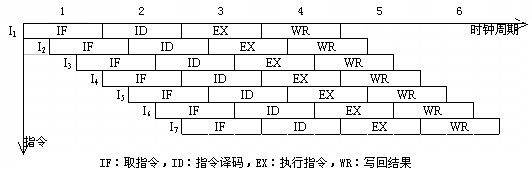
图5.56只是超流水线处理机原理上的指令执行时空图。实际上,流水段还要进一步细分,一个流水段要细分为多个流水级,每一个流水级也都有名称。在分解流水段时要根据实际情况,有些流水段分解的流水级数可多些。例如,图5.56中的"译码(ID)"流水段,可以再细分为"译码"流水级、"取第一个操作数"流水级和"取第二个操作数"流水级等。有些流水段分解的流水级数可少些,也的流水段可以不再细分,如"写结果"流水段一般不再细分。
典型结构
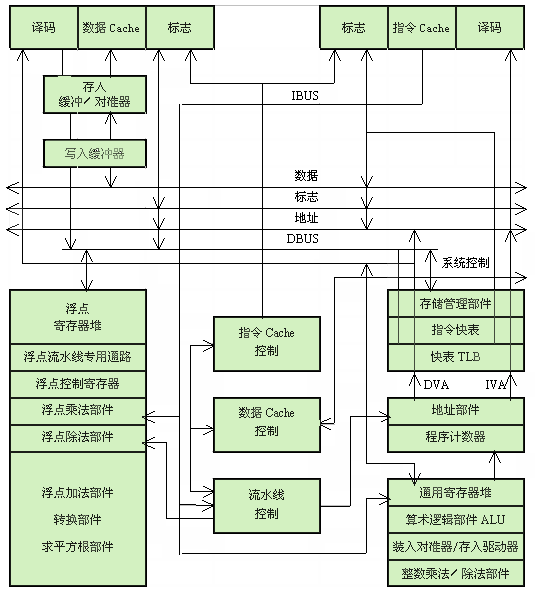
在早期生产的计算机中,巨型计算机CRAY-1和大型计算机CDC-7600属于超流水线处理机,其指令级并行度n=3。在目前大量使用的微处理器中,只有SGI公司的MIPS(Microprocessor without Interlocked Piped Stages)系列处理机属于超流水线处理机。MIPS是除Intel公司的X86系列微处理器之外,生产量最大的一种微处理器。MIPS系列的微处理器主要有R2000、R3000、R4000、R5000和R10000等几种,其中,R4000是典型的超流水线处理机。下面以R4000为例,说明超流水线处理机的基本结构和工作原理,图5.57是R4000微处理器的结构框图。
R4000芯片内有两个Cache,指令Cache和数据Cache的容量各8K字节,每个Cache的数据宽度为64位。由于每个时钟周期可以访问Cache两次,因此,在一个时钟周期内可以从指令Cache中读出两条指令,从数据Cache中读出或写入两个数据。
整数部件是R4000的核心处理部件,它主要包括一个32个32位的通用寄存器堆,一个算术逻辑部件,一个专用的乘法/除法部件。整数部件负责取指令,整数操作的译码和执行,LOAD与STORE操作的执行等。通用寄存器堆用作标量整数操作和地址计算,寄存器堆有两个输出端口和一个输入端口,它还设置有专用的数据通路,可以对每一个寄存器读和写两次。整数部件包括一个整数加法器和一个逻辑部件,负责执行算术运算操作,地址运算和所有的移位操作。乘法/除法部件能够执行32位带符号和不带符号的乘法或除法操作,它可以与整数部件并行执行指令。
浮点部件包括一个浮点通用寄存器堆和一个执行部件。浮点通用寄存器堆由16个64位的通用寄存器组成,它也可以设置成32个32位的浮点寄存器。浮点执行部件由浮点乘法部件、浮点除法部件和浮点加法/转换/求平方根部件等三个独立的部件组成,这三个浮点部件可以并行工作。浮点操作主要包括浮点加、减、乘、除和求平方根、定点与浮点格式的转换、浮点格式之间的转换、浮点数比较等15种。浮点控制寄存器用来设置浮点协处理器的状态和控制信息,主要用于诊断软件、异常事故处理、状态保存与恢复、舍入方式的控制等。
R4000的指令流水线有8级,流水线操作如图5.58所示。R4000采用超流水线结构,取指令和访问数据都要跨越两个流水级。实际上,每个时钟周期包含两个流水级,处理器取第一条指令(IF)和取第二条指令(IS)两个流水级都要访问指令Cache,这两个流水级为一个时钟周期。在寄存器流水级(RF)的开始,指令已经读到了指令寄存器中,因此可以进行译码,并且访问寄存器堆。另外,由于指令Cache是采用直接映象方式的,因此,从指令Cache中读出的区号要与访问存储器的物理地址进行比较。如果相等,表示指令Cache命中。
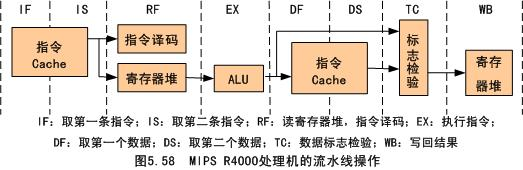
对于非存储器操作指令,如果指令Cache命中,那么,指令可以在指令执行(EX)流水级执行,指令的执行结果可以在EX流水级的末尾得到。
在正常情况下,MIPS R4000指令流水线工作时序如图5.59所示。一条指令的执行过程经历8个流水线周期。由于一个主时钟周期包含有两个流水线周期,因此,也可以认为每4个主时钟周期执行完一条指令。
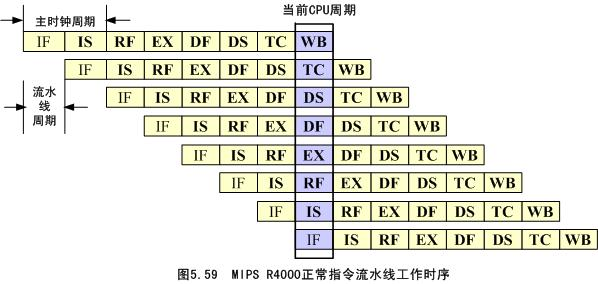
从流水线的输入端看,每一个流水线周期启动一条指令。同样,从流水线的输出端看,每一个流水线周期执行完成一条指令。当流水线被充满时,如图5.59中的黑框内所示,有8条指令在同时执行。如果把两个流水线周期看作一个时钟周期,则在一个时钟周期内,R4000处理机分时发射了两条指令。同样,在一个时钟周期内,流水线也执行完成了两条指令,因此,R4000是一种很典型的超流水线处理机。
在取第一个数据(DF)和取第二个数据(DS)流水级期间,R4000要访问数据Cache。首先,存储器管理部件(MMU)在DF和DS流水级把数据的虚拟地址变换成主存物理地址,然后,在标志检验(TC)流水级从数据Cache中读出数据的区号,并把读出的区号与变换成的主存物理地址进行比较。如果比较结果相等,则数据Cache命中。对于STORE指令,如果命中,只要把数据送到写入缓冲器,由写入缓冲器负责把数据写到数据Cache的指定中去。对于非存储器操作指令,在写回结果(WB)流水级要把指令的最后执行结果写回到通用寄存器堆中。
性能
在一台指令级并行度为(1,n)的超流水线处理机上,执行N条没有数据相关和控制相关的指令所需要的时间为: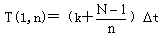
其中,k是指令流水线的流水段数,或时钟周期数;而不是流水线级数。在一般超流水线处理机中,指令流水线的级数实际应为k n。上式中的头一项是第一条指令通过指令流水线执行完成所需要的时间,而第二项是执行其余N-1条指令所需要的时间,这时,每一个时钟周期有n条指令要在指令流水线中执行完成,也就是每一个流水线周期执行完成一条指令。
单流水线普通标量处理机连续执行N条指令所用时间如(5.29)式所示,因此,超流水线处理机相对于单流水线普通标量处理机的加速比为:
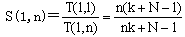
当执行的指令条数N→∞时,在没有数据相关和控制相关的理想情况下,超流水线处理机的加速比的最大值为:
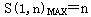
摘自https://pop0726.github.io/jsj/content/sec.htm,侵删(TSU的远古课件,但还是很详尽)